

Method 1: Replace non-ASCII characters with a Single Space
When working with Python 🐍, one may come across the need to replace non-ASCII characters with a single space in a given string. Removing these characters helps maintain consistency and avoid encoding issues in data processing tasks. Let’s dive into a simple method for achieving this goal.
The first step is to utilize Python’s re module to create a regular expression pattern that matches non-ASCII characters. Import the re module and create a function that employs the re.sub() method, which allows for pattern matching and replacement in a given string 👩💻:
import re
def remove_non_ascii(text):
return re.sub(r'[^\x00-\x7F]', ' ', text)
Here, the regular expression r'[^\x00-\x7F]' targets any character that falls outside the range of standard ASCII characters. With this pattern, the re.sub() method replaces all matched non-ASCII characters with a single space in the input text 🔄.
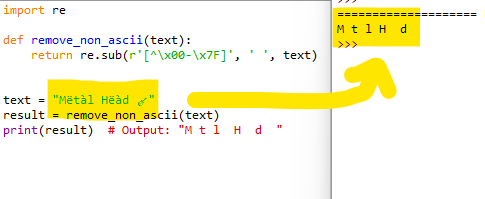
Now, let’s take a look at an example to see our function in action 🎬:
text = "Mëtàl Hëàd 🎸" result = remove_non_ascii(text) print(result) # Output: "M t l H d "
As a result, our function successfully replaced all non-ASCII characters in the input string with single spaces, making the text more uniform and easier to process 👍.
In the following, I’ll explore various methods to remove Unicode characters from strings in Python. These methods include using string encoding and decoding, regular expressions, list comprehensions, string replace(), and checking if a character is alphanumeric. Let’s dive into each method. 😊
Method 2: Using String Encoding and Decoding to Remove Unicode Characters

One way to remove Unicode characters is to use the built-in string encoding and decoding methods, encode() and decode() (PythonPool). To do this, you can encode the Unicode string to ASCII and then decode it back, effectively removing any Unicode characters.
Here’s a simple example:
string_unicode = "𝕴 𝖆𝖒 𝕴𝖗𝖔𝖓𝖒𝖆𝖓!"
string_encode = string_unicode.encode("ascii", "ignore")
string_decode = string_encode.decode()
print(string_decode)
# Output:
# !Method 3: Using Regular Expressions to Remove Unicode Characters

Another method is to use the power of regular expressions. With Python’s re module, you can search and remove Unicode characters from the string:
import re string_unicode = "𝓡𝓮𝓰𝓮𝔁 𝓲𝓼 𝓪𝔀𝓮𝓼𝓸𝓶𝓮! ✨" string_clean = re.sub(r"[^\x00-\x7F]+", "", string_unicode) print(string_clean)
Here, we use the sub() function to replace all non-ASCII characters with an empty string.

💡 Recommended: Python Regex Sub
Method 4: Using List Comprehensions to Remove Unicode Characters
List comprehensions offer another way to remove Unicode characters from a string. For example, the expression "".join(c for c in string_unicode if ord(c) < 128) ignores all Unicode characters in the string_unicode.
Want an example? Here is one:
string_unicode = "𝕷𝖎𝖘𝖙 𝕮𝖔𝖒𝖕𝖗𝖊𝖍𝖊𝖓𝖘𝖎𝖔𝖓𝖘 𝖗𝖔𝖈𝖐! 🤘" string_clean = "".join(c for c in string_unicode if ord(c) < 128) print(string_clean)
In this example, we create a new string by joining only characters with ASCII code less than 128.
💡 Recommended: List Comprehension in Python — A Helpful Illustrated Guide
Method 5: Using String replace() to Remove Specific Unicode Chars

You can also use the replace() method to remove specific Unicode characters from a string:
string_unicode = "𝖂℮ 𝖆𝖗℮ 𝓰𝓻𝓸𝓸𝓿𝔂! 🕺"
string_clean = string_unicode.replace("℮", "e").replace("𝖆", "a")
print(string_clean)
Here, we replace specific Unicode characters with their ASCII equivalents.
💡 Recommended: Python String Replace
Method 6: Using String isalnum() to Remove Unicodes
Lastly, the isalnum() method can help remove Unicode characters by checking if a character is alphanumeric:
string_unicode = "𝕴 𝖆𝖒 𝕴𝖗𝖔𝖓𝖒𝖆𝖓! 𝖂𝖔𝖔𝖔!" string_clean = "".join(c for c in string_unicode if c.isalnum() or c.isspace()) print(string_clean)
In this example, we create a new string by joining only alphanumeric characters and spaces, filtering out other Unicode characters.
💡 Recommended: Python String isalnum()
Understanding Unicode Characters in Python

The world of text processing in Python became more versatile with the introduction of Unicode characters. These characters allow for better representation of international text 🌍, as they can accommodate a much larger set of symbols than ASCII alone. This section will provide a brief understanding of Unicode characters in Python and how they differ from ASCII encoding.
Python has been using Unicode support for strings since version 3.0, making it simple to include characters from a wide variety of languages and scripts in your string literals 🔠. To ensure compatibility, the default encoding for Python source code is UTF-8 (“Unicode HOWTO — Python 3.11.3 documentation”). This enables the seamless use of Unicode characters in your string variables and expressions.
ASCII encoding, on the other hand, is limited to 128 unique characters, which includes alphabets (a-z and A-Z), numbers (0-9), special characters, symbols, and control codes (“Remove Unicode Characters in Python | Codeigo”). While it might work well for basic English text, it’s not sufficient for representing the diverse range of characters and symbols found in many other languages.
With Unicode support, it is significantly easier to work with international text and a more extensive range of characters, providing flexibility 🤸♂️ and precision in your text processing tasks.
Method 7: Unicode Normalization

Unicode normalization is a crucial process when working with Python and text data 🧑💻. It helps in transforming Unicode strings into a standard representation, making string comparison and manipulation easier. In this section, we will discuss a few handy methods to remove Unicode characters in Python.
One helpful technique is the unicodedata.normalize() method. This method can be used to convert accented characters to their non-accented counterparts, allowing us to remove diacritic marks. Here’s a sample code to achieve this:
import unicodedata
def remove_accents(input_str):
nfkd_form = unicodedata.normalize('NFKD', input_str)
return u"".join(c for c in nfkd_form if not unicodedata.combining(c))
Another option is to use regular expressions (re.sub) to remove specific Unicode characters 😺. The re.sub method takes three parameters: pattern, replace, and string. Here’s an example:
import re
def remove_unicode_chars(input_str):
pattern = re.compile(u"[\u200c-\u200f\u202a-\u202f\u2066-\u2069]")
return pattern.sub("", input_str)
Lastly, the str.encode method can be used to remove Unicode characters by encoding the string into another format like 'ascii'. After encoding, the string can be decoded back into a cleaned version. For example:
def remove_unicode_chars(input_str):
string_encode = input_str.encode("ascii", "ignore")
string_decode = string_encode.decode()
return string_decode
By using the above methods 🛠, developers can ensure their Python applications handle Unicode characters more effectively, resulting in accurate string manipulation and comparison 🎯.
Handling Unicode Errors

When working with different languages and character sets in Python, Unicode errors may occur. These errors can be handled using various methods to ensure a smooth data processing experience. 😊
One straightforward approach is to use the encode() and decode() methods with the ignore error handling strategy. This method simply removes the troubling Unicode characters from the string, making it easier to process.
For example, utilizing the str.encode() function with the "ascii" and "ignore" arguments will help to discard Unicode characters that are not part of the ASCII set, as demonstrated in this Python Guides example:
string_unicode = "Python is easy \u200c to learn."
string_encode = string_unicode.encode("ascii", "ignore")
string_decode = string_encode.decode()
print(string_decode)
Another approach to remove specific Unicode characters is by utilizing regular expressions with the re.sub() method, which replaces the specified pattern with a given string. This method can be useful when you need to target a specific set of characters for removal.
For example, according to Python Pool:
import re string_unicode = "I l\u00F8ve Python!" pattern = r"[\u00F8]" replace = "" result = re.sub(pattern, replace, string_unicode) print(result)
Remember to handle Unicode errors carefully, as removing characters without being aware of the data being discarded may lead to issues further down the line. Using these methods, you should be able to efficiently address Unicode errors and clean up your data in Python. 🐍
Best Practices

When working with Python to remove Unicode characters, there are some best practices you should consider. These practices will ensure cleaner, more efficient code and smoother experience when dealing with various encodings.
Firstly, make use of the built-in str.encode() and str.decode() methods whenever possible. This approach enables you to remove unwanted Unicode characters by encoding the string to an ASCII-compatible representation, ignoring unencodable characters, and then decoding it back to a string 🪄. You can see a simple example in this Stack Overflow thread.
Another good practice is to familiarize yourself with the encoding and decoding options available in Python. For example, you could use the ‘unicode_escape‘ codec to remove Unicode representations from a string, as explained in this Stack Overflow discussion.
When dealing with data from various sources, it’s always helpful to be aware of the expected encoding format. If unsure, consider using libraries like chardet to detect and handle different string encodings confidently 🕵️♀️.
Finally, whenever possible, use context-aware string manipulations. For example, when handling HTML or XML, avoid using regex for parsing and opt for dedicated libraries like Beautiful Soup or ElementTree. These libraries are designed to handle encoding issues more robustly, reducing the risk of processing errors 😇.
I used a lot of regular expressions in this article, so if you want to boost your regex skills, consider reading this tutorial:
💡 Recommended: Python Regex Superpower [Full Tutorial]
Also, feel free to join our free email academy on tech, Python, coding, and ChatGPT — it’s fun!