
Are you trying to understand how to call Python code from Tableau? Maybe you tried other online resources but ran into frustrating errors. This TabPy tutorial will show you how to get the TabPy installed and setup, and will get you running Python code in Tableau.
Installing Tableau Desktop
If you need Tableau Desktop, you can get a 14-day trial here: https://www.tableau.com/products/desktop/download
Note: Tableau Public, the free license version of Tableau, does not support Python integration.
TabPy Installation
Reading the documentation, this should be as simple as:
pip install tabpy
Perhaps this will be all you need to get TabPy installed. But when I tried the install failed. This was due to a failure to install on one of the dependencies, a Python package called Twist. A search on StackOverflow leads to this solution (https://stackoverflow.com/questions/36279141/pip-doesnt-install-twisted-on-windows) and to this unofficial Windows binary available at (http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted). I downloaded the appropriate binary for my version of Python, navigated to the download directory, and installed with this command:
pip install Twisted-20.3.0-cp38-cp38-win_amd64.whl
That installed Twist, and I was then able to install TabPy as expected.
TabPy Setup
With TabPy installed, starting the TabPy server can be done from the command prompt:
TabPy
You should see a message like the one below, telling you that the web service is listening on port 9004:

With TabPy running, start Tableau Desktop.
In Tableau Desktop, click Help on the toolbar, then Settings and Performance > Manage Analytics Extension Connection.

Then select TabPy/External API, select localhost for the server, and set the port to 9004

TabPy Examples
The first example shows how to use a NumPy function on aggregated data to calculate the Pearson correlation coefficient.
The second example shows how to use a TabPy deployed function to do a t-test on disaggregated data.
Example – Correlation on Aggregated Data
We have TabPy running and Tableau’s analytics extension configured. Now we’ll call Python code from Tableau.
Downloaded data on the wages and education of young males (https://vincentarelbundock.github.io/Rdatasets/csv/Ecdat/Males.csv) and open using the Connect to Text File option.

Select Sheet1 to start a new worksheet.

Maried is spelled without the second ‘r’, so right-click on the field and rename it to “Married.”

Drag “Married” and “Experience” to the row shelf, and double-click on Exper and Wage:

Next, change SUM(Exper) to AVG(Exper) and SUM(Wage) to AVG(Exper):

The view should now look like this:

Now let’s add a calculation with some Python code! You can create a calculation by clicking on the Analysis tab on the toolbar and then “Create Calculated Field”
Call the calculation “TabPy Corr” and use this expression:
SCRIPT_REAL("import numpy as np
print(f'arg1_: {_arg1}')
print(f'arg2_: {_arg2}')
print(f'return: {np.corrcoef(_arg1,_arg2)[0,1]}')
return np.corrcoef(_arg1,_arg2)[0,1]",avg([Exper]),avg([Wage])
)
The print statements allow us to see the data exchange between Tableau and the TabPy server. Switch to the command prompt to see:

Tableau is sending two lists, _arg1 and _arg2, to the TabPy server. _arg1 is a list with the values from avg([Exper]) and _arg2 is a list with the values from avg([Wage]).
TabPy returns a single value representing the correlation of avg([Exper]) and avg([Wage]).

We return np.corrcoef(_arg1,_arg2)[0,1] instead of just np.corrcoef(_arg1,_arg2) because np.corrcoef(_arg1,_arg2) returns a 2×2 correlation matrix, but Tableau expects either a single value or a list of values with the same length as _arg1 and _arg2. If we return a the 2×2 matrix, Tableau will give us the error message, “TypeError : Object of type ndarray is not JSON serializable“

The functions used to communicate with the TabPy server, SCRIPT_REAL, SCRIPT_INT, SCRIPT_BOOL and SCRIPT_STR are “table calculations,” which means that the input parameters must be aggregated. For example, AVG([Exper]) is an acceptable parameter, but [Exper] is not. Table calculations work not on the data in the underlying dataset (Males.csv for this example) but on the values aggregated to the level shown in the Tableau worksheet. Tableau sends TabPy lists with the aggregated values.
We use SCRIPT_REAL rather than one of the other SCRIPT_* functions because our function will return a float. If, for example, the function was instead returning a string, we would use SCRIPT_STR.
One call is made from Tableau to TabPy for each partition in the table calculation. The default is Table(down) which uses a single partition for the entire table:
We can change the partition by selecting edit then table calculation:

Currently, the Table Calculation is computed using Table(down), which means that Tableau goes down all of the rows in the Table. You can see that all of the values are highlighted in yellow.

If we change from Table(down) to Pane(down) the table calculation will be done separately for each pane. The rows of the table are divided into two panes – one for married = no and another for married=yes. Therefore, there are two separate calls to TabPy, one for maried no and a second for maried=yes. Each call gets a separate response.

We can see the exchange of data by switching back to the command prompt:

The print statements show what is happening. The first call to TabPy represents the partition where married=no. Lists are sent with the average wage and experience values and the value returned is -0.3382. The second call represents the partition where married=yes, the related average wage and experience values are sent, and the function returns -0.0120. Tableau displays the results.
We called Python code from Tableau and used the results in our worksheet. Excellent!
But we could have done the same thing much more easily without Python by using Tableau’s WINDOW_CORR function:
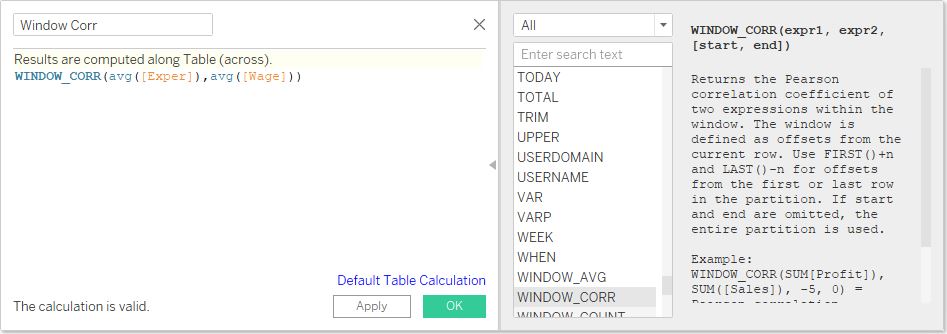
We can add this to the view and see that it gives the same results using either Table(down) or Pane(down):

This example is great for understanding TabPy. But we don’t need to use Python to calculate correlation since Python already has WINDOW_CORR built-in.
Example – Two-sample T-Test Disaggregated Data
If our data represents a sample of the general male population, then we can use statistics to make inferences about the population based on our sample. For example, we might want to ask whether our sample gives evidence that males in the general population who are unionized have more experience than those who are not. The test for this is a two-sample t-test. You can learn more about it here: (https://en.wikipedia.org/wiki/Two-sample_hypothesis_testing).
Unlike correlation, Tableau does not have a built-in t-test. So we will use Python to do a t-test.
But first, we will set up a new worksheet. The documentation here (https://github.com/tableau/TabPy/blob/master/docs/tabpy-tools.md#t-test) explains what we need to pass to the t-test function. We need to pass _arg1 with the years of experience and _arg2 as the categorical variable that maps each observation to either sample1 (Union=yes) or sample2 (Union=no).
Let’s start by creating a new view with Union on the row shelf and AVG(Exper) on the column shelf:

Disaggregate measures by unchecking:

With aggregate measures unchecked, AVG(Exper) should change to Exper. Use the “Show me” menu to change to a box-and-whisker plot:

Our view is set, except for the t-test. The t-test is one of the models included with TabPy, explained here (https://github.com/tableau/TabPy/blob/master/docs/tabpy-tools.md#predeployed-functions). We need to run a command before we can run t-tests. With the TabPy server running, open a second command prompt and enter the following command:
tabpy-deploy-models
You should see a result like this:

If it’s successful, you can now call anova, PCA, Sentiment Analysis, and t-tests from Tableau!
Create a new calculation, “Union Exper Ttest,” which will determine whether there is a statistically significant difference in average experience for the unionized compared with the non-unionized.
SCRIPT_REAL("print(f'unique values: {len(set(_arg2))}')
return tabpy.query('ttest',_arg1,_arg2)['response']"
,avg([Exper]),attr([Union]))Because SCRIPT_REAL is a table calculation the parameters have to be aggregated (using avg and attr) but with the “aggregate measures” unchecked the view is showing individual observations from Males.csv anyway, the individual values are passed to TabPy.
Drag the new calculation to the tooltip to show it in the view:

The t-test returns a p-value of 0.4320. We can interpret this to mean that we do not find evidence for a difference in average years experience for unionized versus non-unionized males. The average experience in our sample data is different for unionized men compared with non-unionized men, but because the p-value is high we don’t have evidence of a difference in the general population..
Tableau does not have a t-test built-in, but we have added it using Python!
Troubleshooting
You’re very likely to encounter errors when setting up calculations with TabPy. Here’s an example. If we try switching the table calculation from Table(down) to Cell, we get this message:

_arg1 and _arg2 are lists, so what’s the problem? The error message we see in Tableau doesn’t help us to pinpoint the problem. If we switch to the command prompt, we can see the stack trace:

The stack trace tells us that line 34 is throwing the error. We can look at the ttest.py code here https://github.com/tableau/TabPy/blob/master/tabpy/models/scripts/tTest.py to better understand the error.
The problem is that if we are doing a two-sample t-test, we can do it in one of two ways:
- Send
_arg1and_arg2as the two different samples. For example,_arg1could be[1, 4, 1]and_arg2be[3, 4, 5]. - Send both samples in
_arg1and use_arg2to specify which sample each observation should be included in. For example,_arg1could be[1, 4, 1, 3, 4, 5]and_arg2be[‘yes’,’yes’,’yes’, ’no’,’no’,’no’].
When the table calculation was set to use table(down), _arg2 had both the value Union=no and Union=yes, but now that we are using cell we have two calls to TabPy, one for Union=no and a second for Union=yes. Instead of sending _arg1 = [1, 2, 1, 5, 3, 4, 5, 1] _arg2= [‘yes’,’yes’,’yes’,’no’,’no’,’no’], we are sending _arg1 = [1, 4, 1] and _arg2 = [‘yes’,’yes’,’yes’] with one call to TabPy and then making a second call with _arg1 = [4, 5, 1] and _arg2=[‘no’,’no’,’no’]. As a result, in ttest.py len(set(_arg2)) == 2 evaluates to false, and we end up at line 34, which throws an error.
We can troubleshoot similar errors by checking the command prompt to find the error message and the line number that is throwing the error.