
Working in Python with files and directories in an efficient way is important especially when we are talking about several thousand files.
For example, if the goal is to “just” count the number of files in a directory it is probably a good idea to work directly with iterables without creating lists that would take up more memory.
Here we are going to try to do this whenever possible by applying functions from Python’s built-in modules such as os, glob, os.path, and pathlib.
addition to showing how to use them, we will briefly compare them and see which ones can be applied to do a recursive file count.
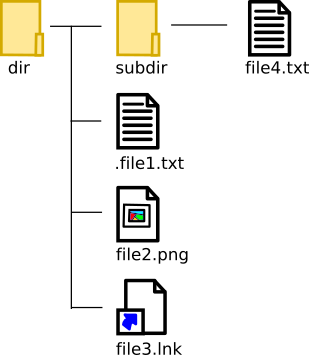
We will refer the examples to a simple file structure as shown in the figure. The directory “dir” contains a subdirectory “subdir” and three files including a text file, an image, and a shortcut.
The name of the text file starts with a dot (in Linux it would be a hidden file) and we will see that if we use “glob” (method 4) it will not count it.
Inside the subdirectory “subdir” there is only one text file. The file type is not important here.
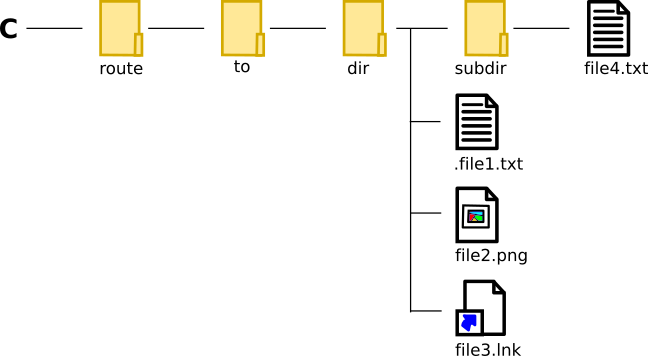
Let’s suppose that the path to the “dir” directory (adopting a Windows format) is:
“C:/route/to/dir” and we store it in the variable “dir_path“.
Method 1: Using os.listdir() and os.path.isfile()
This a non-recursive method.
The “os” module allows you to use many features of the operating system. Here we use one of its functions, listdir() with the argument dir_path, to get a list with the names of all files and subdirectories contained in “dir“.
For this you can also use os.scandir() which, as the official Python documentation says, is more efficient for many common use cases.
The os.path module implements some functions to manipulate path names and here we use the isfile() function to determine and count only those that are files.
Let’s see some examples:
import os, os.path
dir_path='C:/route/to/dir'
# Example 1
num=0
for element in os.listdir(dir_path):
element_path=os.path.join(dir_path, element)
# os.listdir return only names and we use os.path.join to concatenate the entire route
# os.path.join will concatenate intellegently the route according with your operating system format
if os.path.isfile(element_path):
num+=1
print(num)
# The result is 3
# Example 2 (a more compact form)
print(sum([1 for element in os.listdir(dir_path) if os.path.isfile(os.path.join(dir_path, element))]))
# The result is 3
The result in both cases is 3 because this method is not recursive and does not count file4.txt that is inside the “subdir” subdirectory
Method 2: Using os.scandir()
This is a non-recursive method.
The scandir() function of the os module returns an iterator of os.DirEntry objects. Each element contained in the specified directory will be represented by an os.DirEntry object that in addition to the path also contains other attributes of the same.
Thus, taking advantage of this information, we will know if something is a file or not by applying is_file() of the os module without the need to use the isfile() function of the os.path module.
This method is very efficient and, according to my tests, it is significantly faster than option 1 that uses os.listdir() with os.path.isfile().
Let’s see some examples:
import os
dir_path='C:/route/to/dir'
# Example 1:
num=0
for element in os.scandir(dir_path):
if element.is_file(): # each time element is a diferent os.DirEntry objetc inside the diretory
num+=1
print(num)
# The result is 3
# Example 2 (a more compact form)
print(sum(1 for element in os.scandir(dir_path) if element.is_file()))
# The result is 3The result in both cases is 3 because this method is not recursive and does not count file4.txt that is inside the “subdir” subdirectory
Method 3: Using os.walk() – the Fastest
This method can be recursive or non-recursive.
The os module function walk() returns an object generator. The function can walk a directory tree from top to bottom, or vice versa, and for each branch (or subdirectory) it returns a tuple containing all the subdirectory and file names of that branch.
Each tuple of each branch (parent tuple) contains 3 tuples inside (children).
- The first child tuple contains the name of the base directory of the branch.
- The second child tuple contains the names of all the subdirectories within the branch or base directory.
- The third child tuple contains all the files within the base directory.
In our example, the objects generated by walk() are two tuples because there is the main branch whose base directory is “dir” and the second branch whose base directory is “subdir“.
That is to say, the first tuple is:
((dir),(subdir),(.file1.txt, file2.png, file3.lnk))
and the second one:
((subdir), (), file4.txt)
If we want to recursively count all the files in the directory tree, we will add the elements of all the third child tuples.
On the other hand, if we only want to count the files of the first base directory we only add the elements of the third child tuple of the first parent tuple.
Here we use the next() function to interact with the object generator and get the first of the collection (the first parent tuple).
This is what is shown in these examples:
import os
dir_path='C:/route/to/dir'
# Example 1: Non-recursive
tree=os.walk(dir_path, topdown=True)
top_branch=next(tree)
print(len(top_branch[2]))
# The result is 3
# Example 2: Non-recursive (a more compact form)
tree=os.walk(dir_path, topdown=True)
print(len(next(tree)[2]))
# The result is 3
# Example 4: Recursive
num=0
for i in os.walk(dir_path, topdown=True):
num += len(i[2])
print(num)
# The result is 4
💡 Note: In my tests with about 10000 files this method, in both cases, recursive and non-recursive, was the fastest
Method 4: Using glob.iglob() and os.path.isfile()
This method can be recursive or non-recursive.
The glob module is specific for finding files and directories whose names match a pattern, such as all those ending in .pdf. Here we use the iglob() function of this module which returns an iterator with all the matches.
As in this case, we want to match absolutely everything, we put an asterisk * at the end of the path.
To do the same but recursively we specify in the argument (recursive = true) but we also put (it is necessary) double asterisk ** at the end of the path.
To distinguish between directories and files we use the isfile() function of the os.path module as in Method 1.
Keep in mind that, as explained in its documentation, glob will not match files whose names start with a period (such as .file1.txt in our example). If this is a problem instead of using glob.iglob() you can use the fnmatch() function of the fnmatch module but it will not allow recursion.
🚀 Performance: Also, as the glob documentation warns, using the double asterisk can be an inordinate amount of time. This is what I noticed in my tests: without recursion and with about 300 files it took similar times to method 1, but with recursion with about 10000 files, it was very slow taking around 3.5 seconds, definitely not recommended for these cases.
Let’s see some examples:
import glob, os.path
# Example 1: Non-recursive
dir_path='C:/route/to/dir/*' # Route with one asterisk
num=0
for i in glob.iglob(dir_path,recursive=False):
if os.path.isfile(i):
num+=1
print(num)
# The Result is 2 (exclude .file1.txt that start with a dot)
# Example 2: Non-recursive (a more compact form)
print(num=sum(1 for i in glob.iglob(dir_path,recursive=False) if os.path.isfile(i)))
# Example 3: Recursive
dir_path='C:/route/to/dir/**' # Route with two asterisk
num=0
for i in glob.iglob(dir_path,recursive=True):
if os.path.isfile(i):
num+=1
print('num: ', num)
# The Result is 3 (exclude .file1.txt that start with a dot)
# Example 4: Recursive (a more compact form)
num=sum(1 for i in glob.iglob(dir_path,recursive=True) if os.path.isfile(i))
print(num)
# The Result is 3 (exclude .file1.txt that start with a dot)
Method 5: Using pathlib.Path()
This method can be recursive or non-recursive.
Here we make basic use of the pathlib module. Specifically, we use the iterdir(), glob() and is_file() functions of the Path() class.
The function iterdir() has some equivalence with the listdir() function of the os module that we used in Method 1 and glob() has some similarity with the iglob() function of the glob module that we used in Method 4.
In example 1, we use iterdir() to return the elements within the dir directory and with is_file() we select and count the elements that are files. The argument of the Path() class is the route to dir.
In example 3, we use glob('*') to match all the contents of the directory and then is_file() to select and count only those that are files.
In example 4, we used glob('**/*') to match all the contents of the dir directory recursively and then is_file() to select and count only those that are files.
Let’s look at the examples:
from pathlib import Path
dir_path='C:/route/to/dir'
# Example 1: Non-recursive
num=0
for element in Path(dir_path).iterdir():
if element.is_file():
num+=1
print(num)
# Example 2: Non-recursive (a more compact form)
print(sum(1 for element in Path(dir_path).iterdir() if element.is_file()))
# Example 3: Non-recursive
print(sum(1 for element in Path(dir_path).glob('*') if element.is_file()))
# Example 4: Recursive
print(sum(1 for element in Path(dir_path).glob('**/*') if element.is_file()))
Conclusion
In my time tests, without recursion, for a sample of about 300 files, the results were similar for Methods 1, 4, and 5 but Methods 3 (walk) and 2 (scandir) were about 10 times faster.
With recursion, counting about 10000 files, Method 3 (walk) was about 6 times faster than Method 4 and 5.
For these reasons, Method 2 (scandir) and especially Method 3 (walk) seem to be the most recommended.