
[toc]
Introduction
In general, encoding means using a specific code for the letters, symbols, and numbers. Numerous encoding standards that are used for encoding a Unicode character. The most common ones are utf-8, utf-16, ISO-8859-1, latin, etc. For example, the character $ corresponds to U+0024 in utf-8 standard and the same corresponds to U+0024 in UTF-16 encoding standard and might not correspond to any value in some other encoding standard.
Now, when you read the input files in the Pandas library in Python, you may encounter a certain UnicodeDecodeError. This primarily happens when you are reading a file that is encoded in a different standard than the one you are using. Consider the below error as a reference.
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xda in position 6: invalid continuation byte
Here we are specifying the encoding as utf-8. However, the file has a character 0xda, which has no correspondence in utf-8 standard. Hence the error. To fix this error, we should either identify the encoding of the input file and specify that as an encoding parameter or change the encoding of the file.
Encoding and Decoding
The process of converting human-readable data into a specified format for secured data transmission is known as encoding. Decoding is the opposite of encoding which converts the encoded information to normal text (human-readable form).
In Python,
encode()is an inbuilt method used for encoding. In case no encoding is specified,UTF-8is used as default.decode()is an inbuilt method used for decoding.

In this tutorial, let us have a look at the different ways of fixing the UnicodeDecodeError.
#Fix 1: Set an Encoding Parameter
By default, the read_csv() method uses None as the encoding parameter value. If you are aware of the encoding standard of the file, set the encoding parameter accordingly. Note that there can be aliases to the same encoding standard. For example, latin_1 can also be referred to as L1, iso-8859-1, etc. You can find the list of supported Python Encodings and their aliases at this link:
Now, lets us say that your file is encoded in utf-8, then you must set utf-8 as a value to encoding parameter as shown below to avoid the occurence of an error.
import pandas as pd file_data=pd.read_csv(path_to_file, encoding="utf-8")
#Fix 2: Change The Encoding of The File
2.1 Using PyCharm
If you are using the Pycharm IDE then handling the Unicode error becomes a tad simpler. If you have a single input file or a lesser number of input files, you can change the encoding of the files to utf-8 directly within Pycharm. Follow the steps given below to implement encoding to utf-8 in Pycharm:
- Open the input file in PyCharm.
- Right-click and choose Configure Editor Tabs.

3. Select File Encodings.
4. Select a path to your file.
5. Under Project Encoding, choose UTF-8.
6. Save the file.

To become a PyCharm master, check out our full course on the Finxter Computer Science Academy available for free for all Finxter Premium Members:

2.2 Using Notepad++
In case you are using notepad++ for your script, follow the steps given below to enable automatic encoding to utf-8:
- Open the .csv file in Notepad++
- Click on Encoding ➡ Choose required encoding.
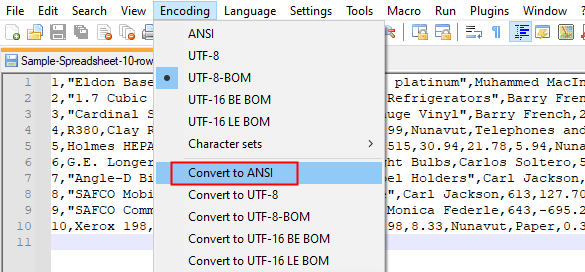
Now, call the read_csv method with encoding=”utf-8” parameter. Refer to the below code snippet for details.
import pandas as pd file_data=pd.read_csv(path_to_file, encoding="utf-8")
#Fix 3: Identify the encoding of the file.
In scenarios where converting the input file is not an option, we can try the following:
3.1 Using Notepad ++
We can identify the encoding of the file and pass the value as an encoding parameter. This is best suited when there is only one or a lesser number of input files.
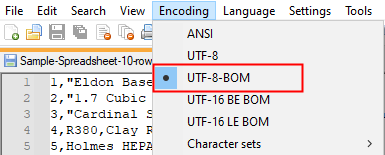
- Open the .csv file in Notepad++
- Click on Encoding.
- The one with a dot specifies your encoding standard.
4. In order to know the value that can be assigned to the encoding parameter, refer to Python Encodings
For example, if the Encoding is UTF-16 BE BOM, the read_csv() can be called as shown below. Notice that the value of encoding is utf_16_be.
import pandas as pd file_data=pd.read_csv(path_to_file, encoding="utf_16_be")
3.2 Use The chardet Package
When there are several input files, it becomes difficult to identify the encoding of the single file or to convert all the files. This method comes in handy in such cases.
There is a package in Python that can be used to identify the encoding of a file. Note that it is impossible to detect the exact encoding of a file. However, the best fit can be found.
Firstly, install chardet package using the below command:
pip install chardetRefer to the below code snippet. Here we have used the chardet package to detect the encoding of the file and then passed that value to the encoding parameter in the read_csv() method.
import chardet
import pandas as pd
with open('C:\\Users\\admin\\Desktop\\Finxter\\Sample-Spreadsheet-10-rows.csv','r') as f:
raw_data= f.read()
result = chardet.detect(raw_data.encode())
charenc = result['encoding']
# set the file-handle to point to the beginning of the file to re-read the file contents.
f.seek(0,0)
data= pd.read_csv(f,delimiter=",", encoding=charenc)If you do not want to find the encoding of the file, try the below fixes.
#Fix 4: Use engine=’python’
In most cases, the error can be fixed by passing the engine=’python’ argument in the read_csv() as shown below.
import pandas as pd file_data=pd.read_csv(path_to_file, engine="python")
#Fix 5: Use encoding= latin1 or unicode_escape
If you just want to get rid of the error and if having some garbage values in the file does not matter, then you can simply pass encoding=latin1 or encoding=unicode_escape in read_csv()
Example 1: Here, we are passing encoding=latin1
import pandas as pd file_data=pd.read_csv(path_to_file, encoding="latin1")
Example 2: Here, we are passing encoding=unicode_escape
import pandas as pd file_data=pd.read_csv(path_to_file, encoding=”unicode_escape")
Conclusion
In this tutorial, we have covered different ways of finding the encoding of a file and passing that as an argument to the read_csv function to get rid of the UnicodeDecodeError. We hope this has been informative. Please stay tuned and subscribe for more such tips and tricks.
Recommended: Finxter Computer Science Academy
- One of the most sought-after skills on Fiverr and Upwork is web scraping. Make no mistake: extracting data programmatically from websites is a critical life skill in today’s world that’s shaped by the web and remote work.
- So, do you want to master the art of web scraping using Python’s BeautifulSoup?
- If the answer is yes – this course will take you from beginner to expert in Web Scraping.

Programmer Humor
Q: What is the object-oriented way to become wealthy?
💰
A: Inheritance.