
This tutorial shows you how to perform simple HTTP get requests to get an HTML page from a given URL in Python!
Problem Formulation
Given a URL as a string. How to extract the HTML from the given URL and store the result in a Python string variable?
Example: Say, you want to accomplish the following:
url = 'https://google.com' # ... Code to extract HTML page here ... print(result) # ... Google HTML file: ''' <!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="de"><head><meta content="text/html; charset=UTF-8" http-equiv="Content-Type"><meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png" itemprop="image"><title>Google</title>... '''
Let’s study the four most important methods to access a website in your Python script!
Method 1: requests.get(url)
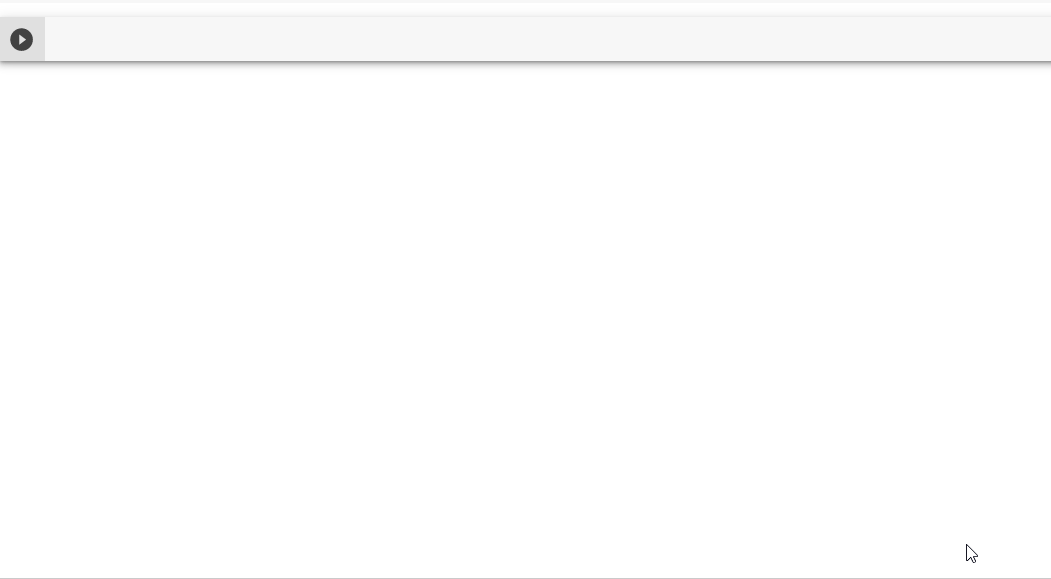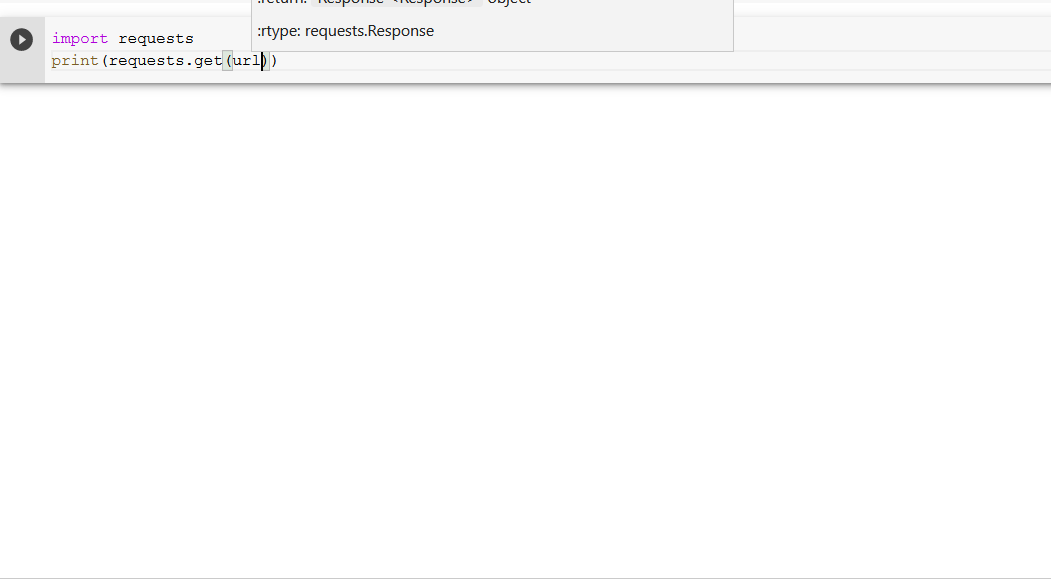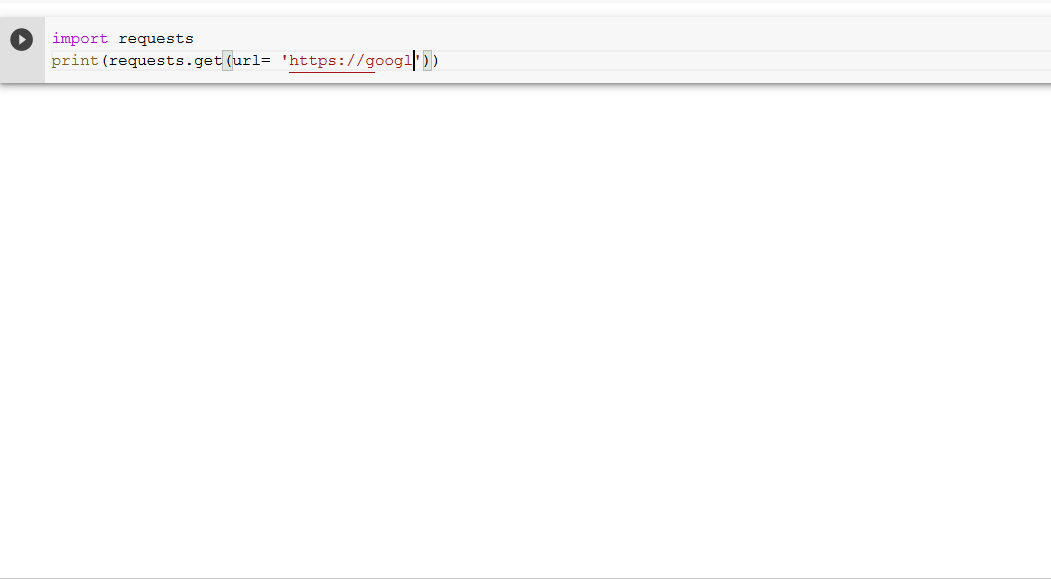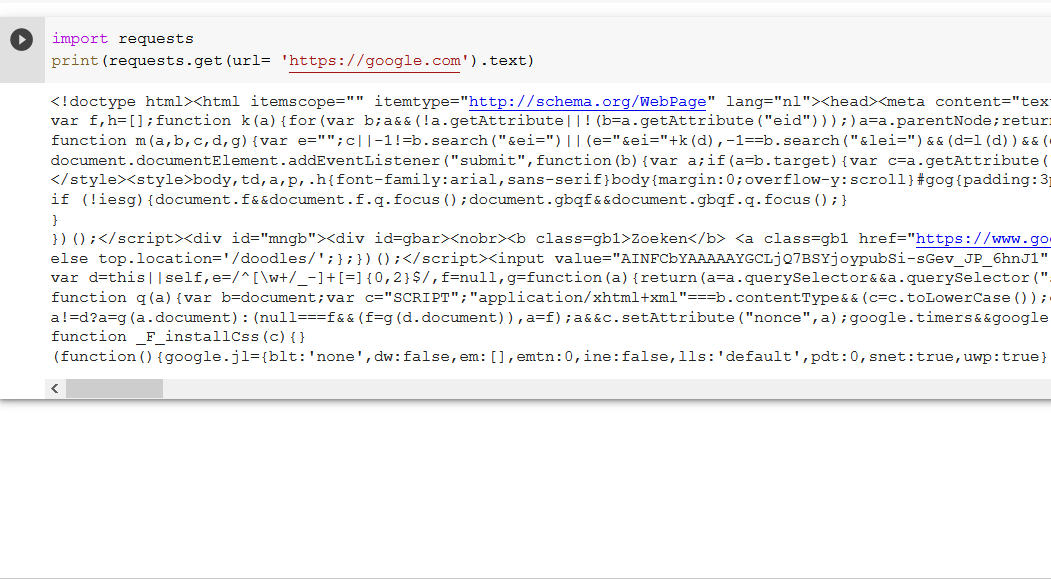
The simplest solution is the following:
import requests print(requests.get(url = 'https://google.com').text)
Here’s how this one-liner works:
- Import the Python library
requeststhat handles the details of requesting the websites from the server in an easy-to-process format. - Use the
requests.get(...)method to access the website and pass the URL'https://google.com'as an argument so that the function knows which location to access. - Access the actual body of the get
request(the return value is a request object that also contains some useful meta information like the file type, etc.). - Print the result to the shell.
The output is the desired Google website:
''' <!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="de"><head><meta content="text/html; charset=UTF-8" http-equiv="Content-Type"><meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png" itemprop="image"><title>Google</title>... '''
Note that you may have to install the requests library with the following command in your operating system terminal:
$ pip install requests
Method 2: One-Liner with requests.get()
Sometimes you don’t want to open an interactive Python session to access the URL. No problem, you can make the previous solution a one-liner and run it from your operating system command line or terminal.
Note that the semicolon is used to one-linerize the previously discussed method. This is useful if you want to run this command from your operating system with the following command:
python -r "import requests; print(requests.get(url = 'https://google.com').text)"
The output, again, is the desired Google HTML page:
''' <!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="de"><head><meta content="text/html; charset=UTF-8" http-equiv="Content-Type"><meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png" itemprop="image"><title>Google</title>... '''
Method 3: urllib.request
A recommended way to fetch web resources from a website is the urllib.request() function. This also works to create a simple one-liner to access the Google website in Python 3 as before:
import urllib.request as r
page = r.urlopen('https://google.com')
print(page.read())Again, you return a Request object that can be accessed to read the server’s response.
Note that this reads the file as a byte string. If you want to read the HTML file as a string, you need to convert the result using Python’s decode() method:
import urllib.request as r
page = r.urlopen('https://google.com')
print(page.read().decode('utf8'))Here’s the output of this code snippet with most of the HTML content omitted for brevity.
<!doctype html>...</html>
🌍 Recommended Tutorial: How to Open a URL in Your Browser From a Python Script?
Method 4: One-Liner with urllib.request
You can also cram everything into a single line so that you can run it from your OS’s terminal:
python -r "import urllib.request as r; print(r.urlopen('https://google.com').read())"Try It Yourself
You can try Methods 1 and 3 yourself in our interactive Juypter notebook with your own desired website URL:

To boost your skills in Python, feel free to check out the world’s most comprehensive Python email academy and download your Python cheat sheets here: