
If we have to work with data in the form of key-value pair we know that the right Python data type (structure) to perform this is a Python dictionary. Below we show a way to define a little python dictionary called “d”.
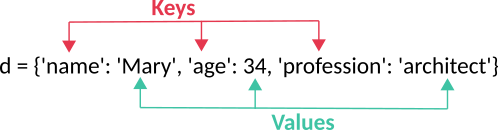
The dictionary keys can be several types of data, but not a list or a dictionary as they are mutable.
Instead, the dictionary values can be lists or even another dictionary. This last case is what we called a nested dictionary. As we can see in the example below the key ‘name’ has dictionary as value.

A nested dictionary, as we see, is a good option when we have to store data in a structured way. We can access the values easily. For example d['age'] will return 34 and d['name']['last'] will return 'Smith'.
Sometimes we may need to go through all the values in a dictionary even if they are nested. Here we are going to see some methods to do it and we are going to show it by printing each key-value pair.
As an example, let’s use a simple data structure that simulates the data of a programming course for children as shown in the figure.
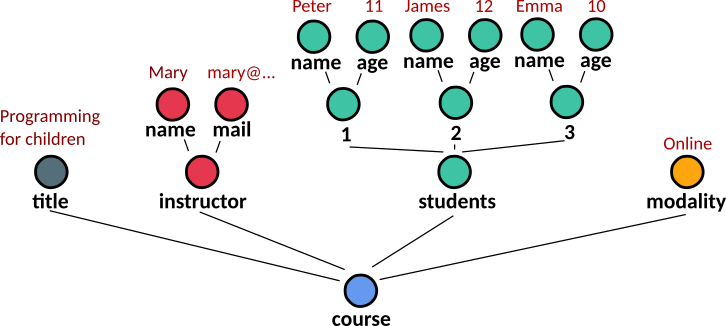
In Python, we can write this structure as:
course={'title': 'Programming for children',
'instructor': {'name':'Mary', 'mail': 'mary@abc.com'},
'students': {'n1': {'name': 'Peter', 'age': '11'},
'n2': {'name': 'James', 'age': '12'},
'n3': {'name': 'Emma', 'age': '10'}},
'modality': 'google meet every monday from 18 to 19 hs'}
Finally, we will extract some conclusions considering also the results obtained by testing these methods with a test dictionary built with 10,000 entries and with random nesting in each entry.
Method 1: With recursion
Recursion is a form to go through all the branches and sub-branches of a tree data structure like we have in this case.
The main idea is to get each pair key-value from the dictionary and evaluate if the value is a dictionary, a nested dictionary, as we saw before. If the value is a “dict” type the dict_walk function is called again but with the value as the argument.
This will occur each time the value of the key-value pair would be a dictionary and this is what we called “recursion”.
It´s what we try to show in the figure below:

In Python we can implement this idea in the following way:
# Example 1
def dict_walk(d):
for k, v in d.items():
if type(v) == dict: # option 1 with “type()”
#if isinstance(v, dict): # option 2 with “isinstance()”
print(k) # this line is for printing each nested key
dict_walk(v)
else:
print(k, ': ', v)
dict_walk(course)
As we see, the argument of the dict_walk function is the dictionary saved in the variable called “course”.
Then “d.item” returns the items of the dictionary as (key, value) pairs that are saved in “k” and “v” respectively in each loop. Then we can use two options to resolve whether “v”, the value, is a dictionary:
- using
type() - or
isinstance()
Finally, when “v” would not be a dictionary we simply print the pair “k” “v”. The “print” inside the “if” is just to show each nested key.
The output of this program is:
title : Programming for children instructor name : Mary mail : mary@abc.com students n1 name : Peter age : 11 n2 name : James age : 12 n3 name : Emma age : 10 modality : google meet every monday from 18 to 19 hs
We can use also dictionary comprehension:
# Example 2
def dict_walk(d):
{k: dict_walk(v) if isinstance(v, dict) else print(k, ': ', v) for k, v in d.items()}
dict_walk(course)
But the code in example 2 does not show the nested keys as in example 1 and that’s why it’s a bit faster.
Anyway if we use dictionary comprehension as in example 3 we will get the same output as in example 1.
It must also be said that this last example was the slowest in method 1 to process the 10,000-entry test dictionary with random nesting.
# Example 3
def dict_walk(d):
{print(k,': ', v) if type(v) != dict else exec('print(k)\ndict_walk(v)') for k, v in d.items()}
dict_walk(course)
Method 2: Iterating and Using a List as a Stack
The main idea in this method is to use the list obtained by items(), as in method 1, as a stack.
Then, extract with pop() the last pair and if the value is a dictionary add its key-value pairs to the stack with “extend”.
With a “while” the process is repeated until all the items are removed and the stack is empty. If the extracted value is not a dictionary, we simply display the key-value pair with print().
This is we show in the next figure:

In Python:
# Example 4
def dict_walk(d):
stack = list(d.items())
while stack:
k, v = stack.pop()
if type(v) == dict: # option 1 with "type()"
#if isinstance(v, dict): # option 2 with "isinstance()"
stack.extend(v.items())
else:
print(k, ': ', v)
dict_walk(course)
Note that using a list as a stack implies using it in such a way that the last item added to the list is the first to be output, this is called LIFO (last in, first out).
Therefore, the characteristic of this method is that it goes through and displays the dictionary in reverse order, from the last to the first.
A way to make it go through the dictionary backward, from the beginning to the end, would be to add and remove elements at the beginning of the list but it would be less efficient because the list would have to move all its elements continuously while there are nestings.
This method also does not show the nested keys except for the last one and is therefore very similar in speed to example 2 of method 1 but perhaps less clear to see.
The output is:
modality : google meet every monday from 18 to 19 hs age : 10 name : Emma age : 12 name : James age : 11 name : Peter mail : mary@abc.com name : Mary title : Programming for children
Method 3: Implementing a generator
In easy words, this method returns one dictionary element at a time.
If in this element (a pair key-value) the value is a dictionary we apply recursion until the value isn’t a dictionary.
This is the process we try to show in the next figure and is similar, in a certain way, to what we have seen in method 1:
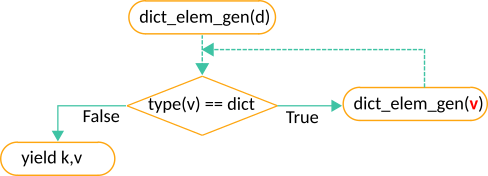
A generator works similar to a function, but instead of using “return” it uses “yield“.
This means that each time the generator is called, it returns what is under the first yield. The next time it will return what is under the second yield and so on.
The difference between yield and return is that yield returns something but does not continue the process until the generator is called again. And when it is called again it can continue from where it was last time because the state (for example the value of the local variables) is saved.
In this case, we are going to make, in addition, that if the value is a dictionary the generator calls itself (with yield from) recursively until it finds one that is not.
The fact that a generator works element by element implies memory saving. Anyway, in our time tests, it was always the slowest method.
The Python code could be:
# Example 5
def dict_walk(d):
for k, v in d.items():
if type(v) == dict: # option 1 with type()
#if isinstance(v, dict): # option 2 with isinstance()
yield (k,'')
yield from dict_walk(v)
else:
yield (k, v)
for k, v in dict_walk(course):
print(k, ': ', v)
The first yield after the if is to be able to show the nested keys, as in the other methods, but it is not essential.
Another possibility is using the ABC module. This provides some abstract base classes that, as said in the Python documentation, can be used to test whether a class or instance provides a particular interface, for example, if it is hashable or if it is a mapping.
A dictionary corresponds to the ABC class called “Mutable.Mapping“, which in turn is a subclass of “Mapping“.
This would allow us, in any of the previous methods, although we are going to exemplify it only for the third one, one more option to check if something is a dictionary.
In addition “Mutable.Mapping” and more generically “Mapping” allow us to work with many other classes that work like a dictionary.
That is, for example, we can work with a custom class that implements a mapping but that is not the built-in Python dictionary structure.
Finally in this case, with ABC, we have to use “isinstance()” function but not “type()” inside the “if” statement.
In Python:
# Example 6
from collections import abc
def dict_walk(d):
for k, v in d.items():
if isinstance(v, abc.MutableMapping): # Option 1 with Mutable.Mapping
#if isinstance(v, abc.Mapping): # Option 2 with Mapping (more generic)
yield (k,'')
yield from dict_walk(v)
else:
yield (k, v)
for k, v in dict_walk(course):
print(k, ': ', v)
A Bonus Tip
This is a little variant that can work with many of the above methods.
As said in the Python documentation the objects returned by d.items() are view objects and they provide a dynamic view on the dictionary’s entries, which means that when the dictionary changes, the view reflects these changes.
Perhaps this is not necessary in your program and you could also iterate directly over each dictionary key as shown in this last example:
# Example 7
def dict_walk(d):
for (k,v) in d:
v=d[k]
if type(v) == dict:
print(k)
dict_walk(v)
else:
print(k, ': ', v)
dict_walk(course)
Here we applied this tip to the recursion method but we can implement in some others ones.
Conclusion
Most notable in our tests with a 10,000-entry dictionary with random nestings in each entry was that:
The highest memory peak is similar in methods 1 and 3 but method 2 is almost the double. Therefore in terms of memory savings it seems better to use the recursive or with generator methods.
On the other hand in terms of speed, it could be said that methods 1 and 2 are more similar but method 3 was always shown to be about 30% slower.
For all this, if I had to choose, I would start by trying method 1 with either of the two variants, using d.items() or iterating directly on the dictionary as indicated in the additional tip.