

Do you know the best way of removing duplicates from a Python list? This is a popular coding interview question at Google, Facebook, and Amazon. In this article, I’ll show you how (and why) it works—so keep reading!
How to remove all duplicates of a given value in the list?
Naive Method: Go over each element and check whether this element already exists in the list. If so, remove it. However, this takes a few lines of code.
Efficient Method: A shorter and more concise way is to create a dictionary out of the elements in the list to remove all duplicates and convert the dictionary back to a list. This preserves the order of the original list elements.
lst = ['Alice', 'Bob', 'Bob', 1, 1, 1, 2, 3, 3] print(list(dict.fromkeys(lst))) # ['Alice', 'Bob', 1, 2, 3]
- Convert the list to a dictionary with
dict.fromkeys(lst). - Convert the dictionary into a list with
list(dict).
Each list element becomes a new key to the dictionary. For example, the list [1, 2, 3] becomes the dictionary {1:None, 2:None, 3:None}. All elements that occur multiple times will be assigned to the same key. Thus, the dictionary contains only unique keys—there cannot be multiple equal keys.
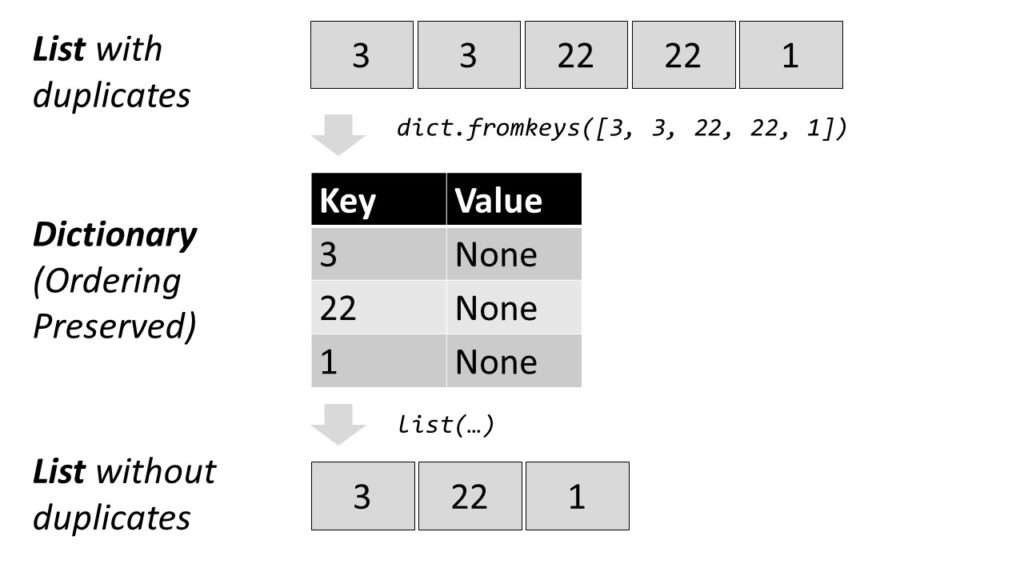
As dictionary values, you take dummy values (per default).
Then, you convert the dictionary back to a list, throwing away the dummy values.
Here’s the code:
>>> lst = [1, 1, 1, 3, 2, 5, 5, 2]
>>> dic = dict.fromkeys(lst)
>>> dic
{1: None, 3: None, 2: None, 5: None}
>>> duplicate_free = list(dic)
>>> duplicate_free
[1, 3, 2, 5]Related blog articles:
- Python Remove Duplicates From List of Lists
- Python List Remove
- The Ultimate Guide to Python Dictionaries!
Do Python Dictionaries Preserve the Ordering of the Keys?
Surprisingly, the dictionary keys in Python preserve the order of the elements. So, yes, the order of the elements is preserved. (source)
This is surprising to many readers because countless online resources like this one argue that the order of dictionary keys is not preserved. They assume that the underlying implementation of the dictionary key iterables uses sets—and sets are well-known to be agnostic to the ordering of elements. But this assumption is wrong. The built-in Python dictionary implementation in cPython preserves the order.
Here’s an example, feel free to create your own examples and tests to check if the ordering is preserved.
lst = ['Alice', 'Bob', 'Bob', 1, 1, 1, 2, 3, 3]
dic = dict.fromkeys(lst)
print(dic)
# {'Alice': None, 'Bob': None, 1: None, 2: None, 3: None}You see that the order of elements is preserved so when converting it back, the original ordering of the list elements is still preserved:
print(list(dic)) # ['Alice', 'Bob', 1, 2, 3]
However, you cannot rely on it because any Python implementation could, theoretically, decide not to preserve the order (notice the “COULD” here is 100% theoretical and does not apply to the default cPython implementation).
If you need to be certain that the order is preserved, you can use the ordered dictionary library. In cPython, this is just a wrapper for the default dict implementation.
Alternative with Set Conversion
Given a list, the goal is to remove all elements that exist more than once in the list.
Sets in Python allow only a single instance of an element. So by converting the list to a set, all duplicates are removed. In contrast to the naive approach (checking all pairs of elements if they are duplicates) that has quadratic time complexity, this method has linear runtime complexity. Why? Because the runtime complexity of creating a set is linear in the number of set elements. Now, you convert the set back to a list, and voilà, the duplicates are removed.
lst = list(range(10)) + list(range(10)) lst = list(set(lst)) print(lst) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # Does this also work for tuples? Yes! lst = [(10,5), (10,5), (5,10), (3,2), (3, 4)] lst = list(set(lst)) print(lst) # [(3, 4), (10, 5), (5, 10), (3, 2)]
However, converting a list to a set doesn’t guarantee to preserve the order of the list elements. The set loses all ordering information.
Linear-Runtime Method with Set to Remove Duplicates From a List
This third approach uses a set to check if the element is already in the duplicate-free list. As checking membership on sets is much faster than checking membership on lists, this method has linear runtime complexity as well (it has constant runtime complexity).
lst = [3, 3, 22, 22, 1]
dup_free = []
dup_free_set = set()
for x in lst:
if x not in dup_free_set:
dup_free.append(x)
dup_free_set.add(x)
print(dup_free)
This approach of removing duplicates from a list while maintaining the order of the elements has linear runtime complexity as well. And it works for all programming languages without you having to know implementation details about the dictionary in Python. But, on the other hand, it’s a bit more complicated to remember.
Where to Go From Here?
Enough theory, let’s get some practice!
To become successful in coding, you need to get out there and solve real problems for real people. That’s how you can become a six-figure earner easily. And that’s how you polish the skills you really need in practice. After all, what’s the use of learning theory that nobody ever needs?
Practice projects is how you sharpen your saw in coding!
Do you want to become a code master by focusing on practical code projects that actually earn you money and solve problems for people?
Then become a Python freelance developer! It’s the best way of approaching the task of improving your Python skills—even if you are a complete beginner.
Join my free webinar “How to Build Your High-Income Skill Python” and watch how I grew my coding business online and how you can, too—from the comfort of your own home.