
Hey Finxters! Today we are going to talk about one of the most popular clustering algorithms: K-Means.
Ever wondered how to organize seemingly unstructured data, making sense of unordered objects, in an easy way?
For example, you might need to:
- perform customer segmentation
- store files based on their text content
- compress images with your own code
We will learn how to implement it in Python and get a visual output!
A Bit of Theory
In case you are not that much into theory and/or need to get working quickly, you can just skip this part and go to the next one.
First of all, the Machine Learning algorithm that we are about to learn is an unsupervised algorithm. What does that mean?
It means that we do not have beforehand any labels to use for the data-clustering, we might even have no idea what to expect! So in a way we are going to ask the algo to make groups where we might not necessarily see ones.
In addition to being unsupervised, we say this is a clustering algorithm because its point is to create sub-groups of datapoints that are close in some way, in terms of numerical distance. This idea was first implemented by the Bell labs in the late 1950s.
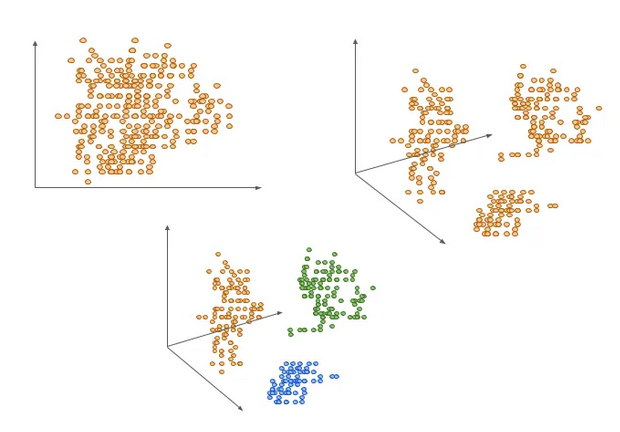
Perhaps the best way to view clusters for a human eye is in 3D like above, or in 2D; however, you rarely have so few features in the dataset. And it works better on data already clustered geometrically.
Which means it is often a good idea to start out reducing the dimensions, for example by means of a Principal Component Analysis algorithm.
Note that this algo must be assisted in that it requires the user to input the number of clusters to create. Each of them will have a center point called “centroid”.
Here is the procedure that will be run under the hood once we execute our code:
- Choose number of clusters K to look for (human input)
- Initialize K centroids randomly
- Compute mean-square distance of each datapoint with each centroid
- Assign each datapoint to the closest centroid (a cluster)
- Compute the mean of each cluster, which becomes your new centroids
The previous 3 steps make up what is called an epoch.
The program we will create will keep running epochs until centroids stop changing, i.e. convergence is obtained.
An image is worth a thousand words, so here is what it looks like:
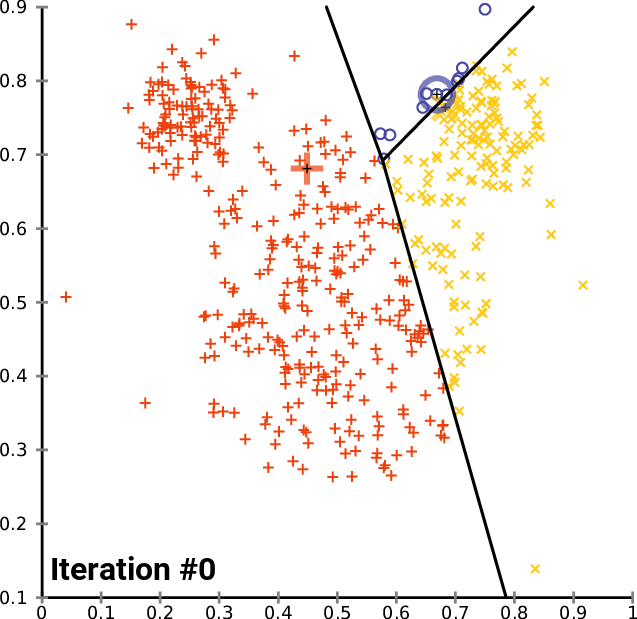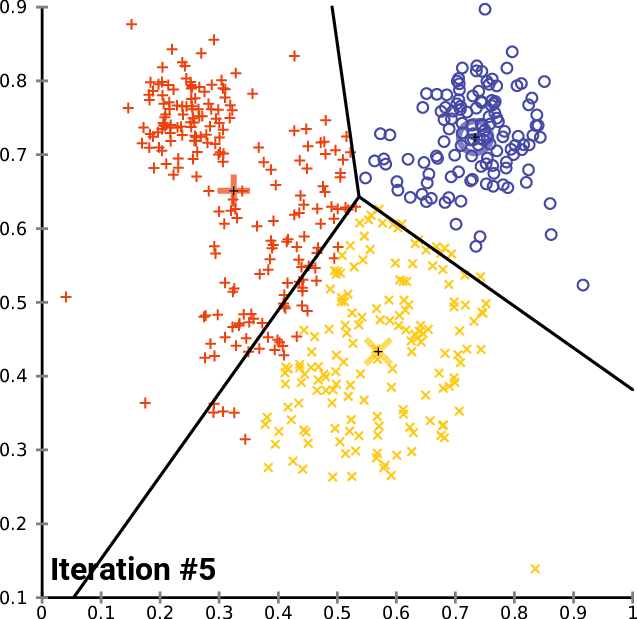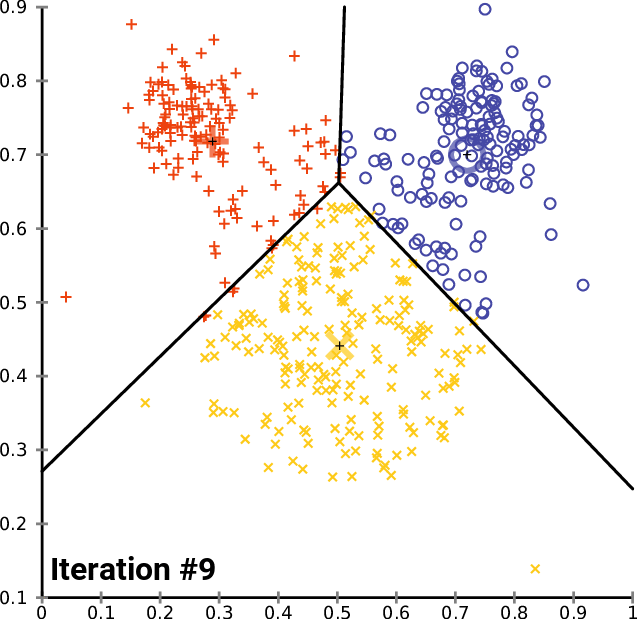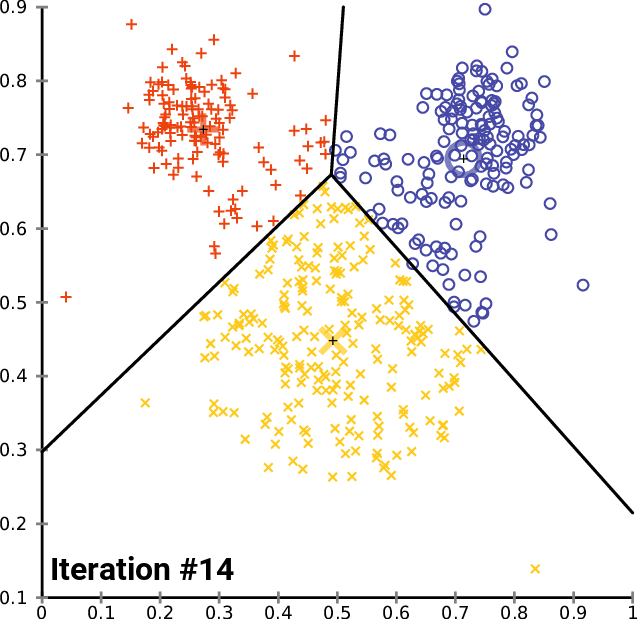
Does K-means have a loss function?
Yes, it is called inertia and is the sum of squares of distances between data points and their respective centroids.
In practice
- K-means is usually run a few times with different random initializations
- Can use random mini-batch at each epoch instead of full dataset, for faster convergence
- Algorithm is quite fast
Installing the Module
The module that we will be using to perform this task is Scikit-Learn, a very handy module when it comes to Machine Learning in Python.
If you do not already have it, proceed with the usual install command:
pip install scikit-learn
Then, check it installed correctly:
pip show scikit-learn
Here is the sklearn documentation page dedicated to Kmeans: https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#sklearn.cluster.KMeans , do not hesitate to check it for more details on the arguments you can pass and a more advanced use.
Once this is done, we will import the Kmeans class within this module:

The first line is the import.
Making the Magic Happen
The second line instantiates the Kmeans class by creating an actual Kmeans object, here is it put in a ‘km’ variable and the user asked for the creation of 3 clusters.
The third line launches the computation of the clustering.
Once your K-Means model is fitted, you can use four attributes that speak for themselves:
km.cluster_centers_: provides the coordinates of each centroidkm.labels_provides the cluster number of each datapoint (indexing starts at 0 like lists)km.inertia_: yields the sum of squared distances of samples to their closest centroidkm.n_iter_: provides the number of epochs run
If you want to try it but do not have a dataset ready, you can generate your own points thanks to sklearn make_blob feature!
Here is an example output in 2D, with a PCA dimensionality reduction as you can see on the x and y axes:
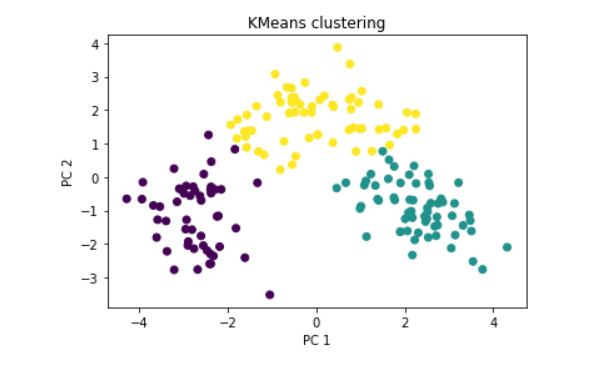
I showed you the attributes, what about the methods available?
The most useful one probably is the .predict(new_datapoint) method, that returns an integer corresponding to the cluster (number) estimated by the model.
How to Pick the Best Number of Clusters
Wait, this is all very nice if I know what to expect in terms of number of clusters, as i can then input this number, but what if I have no idea how many clusters to expect?
Then use the elbow method. It means graph the evolution of the inertia according to the number of clusters, and pick the number of clusters after which decrease in inertia becomes marginal:
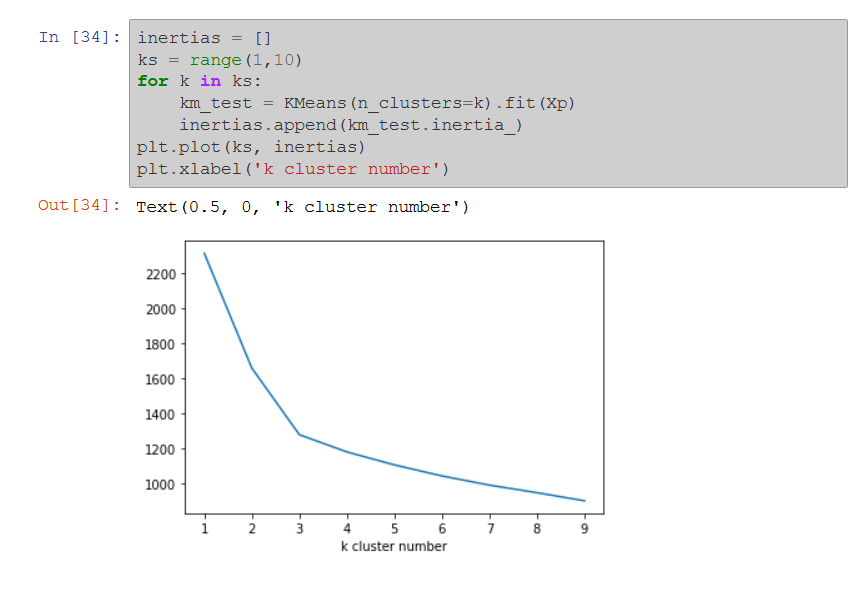
In the above example, the ideal number of clusters seems to be 3. The graph is elbow-shaped, hence the name.
K-Means with NLP: Displaying a Wordcloud
Assuming you used a K-Means algorithm within a Natural Language Processing task, after preprocessing and vectorizing the words, you may be in need of a visual way to present your output.
Indeed, sometimes the number of clusters will be high and displaying labels in a grid will not be that impactful.
Then comes into play the wordcloud module, enabling you to generate easily pretty, colourful wordclouds for instant understanding.
Just pip install wordcloud and use
plt.imshow( Wordcloud().generate(your_text) )
See documentation for parameters.

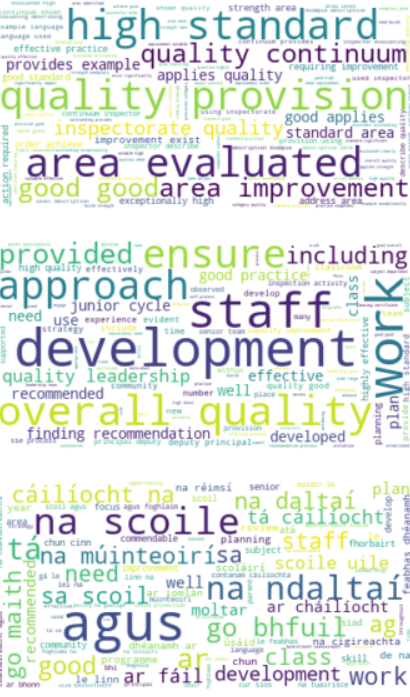
In my example shown above, I was dealing with Irish PDF reports, and in each report part of the content was written in Gaelic.
Guess what the algo found? Look at the bottom cluster!
This illustrates the “unsupervised” characteristic: I did not tell it there was another language, and yet it found it and isolated it by itself!
Where to Go From Here?
I hope you enjoyed this article. To go deeper into the topics, do check the documentation and experiment yourself:
- PCA analysis
- More clustering techniques: https://scikit-learn.org/stable/modules/clustering.html
- More ideas to implement this algorithm : https://dzone.com/articles/10-interesting-use-cases-for-the-k-means-algorithm
Any comments? Let us know!