

Install LlamaIndex with PIP
pip install llama-index
Note that we assume you’re using OpenAI API. If you don’t want to use OpenAI, LlamaIndex automatically uses Meta’s Llama model. However, this would require roughly 12GB of your memory across GPU and CPU (at the time of writing) and run the Llama LLM models locally.
🧑💻 Tip: I recommend you just go with the default: OpenAI’s powerful models that are not only easy to use but also the best-performing models in the space. And it costs only a few cents for simple queries and testing the waters.
You can also install LlamaIndex in your Jupyter notebook (e.g., Google Colab) by using the exclamation mark operator ! as a prefix like so:
!pip install llama-index
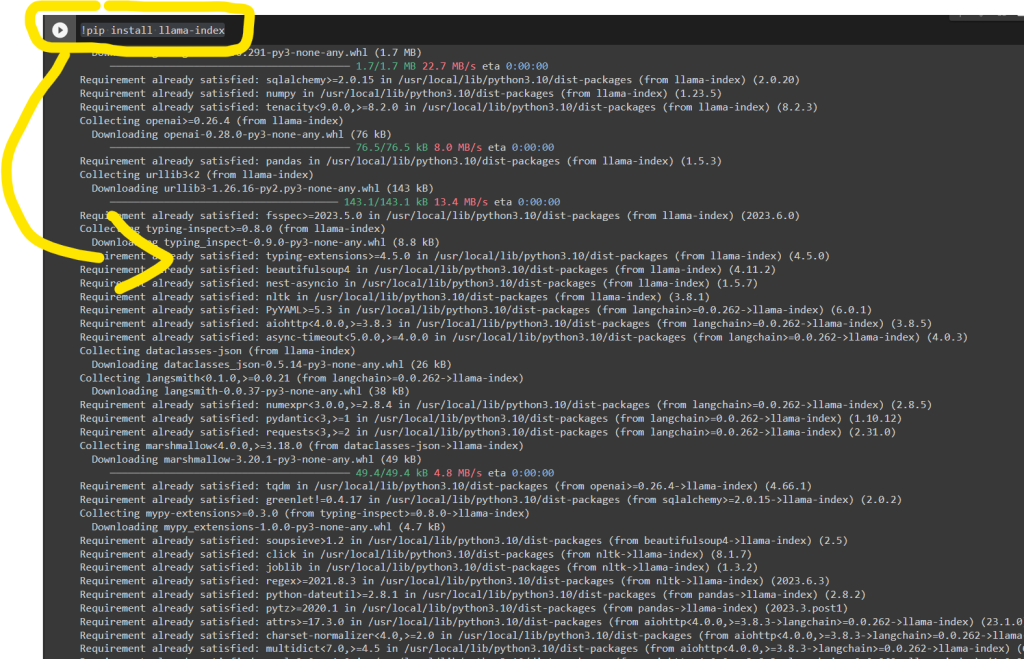
It will then automatically install the library and all dependencies within your Colab Notebook:
By the way, if you’re still unsure about the purpose of LlamaIndex or you feel a bit confused, check out our motivating article on the Finxter blog: 👇🦙

🦙 Recommended: LlamaIndex – What the Fuzz?
Load Any Document and Prompt It In Your Python Shell
Let’s load the content of Peter Thiel’s Wikipedia page, index it, and then query that indexed content to retrieve specific information. However, we’ll use natural language queries with OpenAI! 🤯🐍
Copy and paste the following code into your Python file or Jupyter Notebook — I recommend Google Colab:
import os
from llama_index import VectorStoreIndex, SimpleWebPageReader
# Your OpenAI key here:
os.environ["OPENAI_API_KEY"] = "sk-..."
# URL you want to load into your vector store here:
url = "https://en.wikipedia.org/wiki/Peter_Thiel"
# Load the URL into documents (multiple documents possible)
documents = SimpleWebPageReader(html_to_text=True).load_data([url])
# Create vector store from documents
index = VectorStoreIndex.from_documents(documents)
# Create query engine so we can ask it questions:
query_engine = index.as_query_engine()
# Ask as many questions as you want against the loaded data:
response_1 = query_engine.query("What's Peter's net worth?")
print(response_1)
response_2 = query_engine.query("How did he make money?")
print(response_2)The output:
Peter Thiel's estimated net worth is $9.7 billion.
He made money through his venture capital career, investing in companies like Palantir and Facebook. He also had financial support from friends and family when he established Thiel Capital Management.In-Depth Explanation
This code is designed to extract and query information from a given webpage using the module named llama_index. Here’s a step-by-step explanation:
Imports
import os from llama_index import VectorStoreIndex, SimpleWebPageReader
os: This is a standard Python module that provides a way to use operating system dependent functionality, like reading or writing to the environment.VectorStoreIndexandSimpleWebPageReader: These are imported from thellama_indexmodule.VectorStoreIndexis used to create a searchable index from documents andSimpleWebPageReaderis used to read web pages.
Setting the OpenAI API Key
os.environ["OPENAI_API_KEY"] = "sk-..."
This line sets the OpenAI API key in the environment variables. This suggests that the llama_index module or some other part of the code might be using OpenAI’s API for some operations.
If you need a tutorial on how to set up your OpenAI account with API access, it’s simple. Just follow this one:

💡 Recommended: OpenAI Python API – A Helpful Illustrated Guide in 5 Steps
URL to Load
url = "https://en.wikipedia.org/wiki/Peter_Thiel"
This sets the URL of the Wikipedia page for Peter Thiel, which will be loaded and processed. You can put any URL here. Think of the opportunities — you can load any URL on the web into the powerful brain that is GPT-4 and ask it any question about that URL! 🤯🤯🤯

🧑💻 Recommended: 10 OpenAI SaaS Ideas to Scale a One-Person AI Company
Loading the URL into Documents
documents = SimpleWebPageReader(html_to_text=True).load_data([url])
This line uses the SimpleWebPageReader class to load the content of the specified URL. The html_to_text=True argument suggests that the HTML content of the webpage will be converted to plain text. The result is stored in the documents variable.
💡 Note: Something important happens here: You load one URL’s content into the documents store. However, you could even load multiple (!) documents into the store to build the knowledge store associated with the giga brain that is GPT-4!
Creating a Vector Store from Documents
index = VectorStoreIndex.from_documents(documents)
This line creates a searchable index from the loaded documents using the VectorStoreIndex class.
If you struggle with understanding how the text is represented in a vector store that is understandable by a large language model, check out my explain article here:

💡 Recommended: What Are Embeddings in OpenAI?
Creating a Query Engine
query_engine = index.as_query_engine()
This line converts the index into a query engine, which allows you to ask questions and get answers based on the indexed content.
Querying the Data
response_1 = query_engine.query("What's Peter's net worth?")
print(response_1)
response_2 = query_engine.query("How did he make money?")
print(response_2)These lines query the indexed data using the query method of the query_engine. The first question asks about Peter Thiel’s net worth, and the second question asks how he made his money. The responses are then printed to the console.
You can add any question here – it’s like using SQL but in natural language and with a human-level understanding of the data!
Truly, prompting is the new programming!
💡 Recommended: 1 Billion Coders – Prompting Is The New Programming
Stay tuned and join 150k tech enthusiasts like you who are committed to sharpening their coding skills daily. Join us by downloading our Python cheat sheets here: 👇
To become a truly exponential coder, feel free to check out our full course on OpenAI mastery for coders:
Prompt Engineering with Python and OpenAI
You can check out the whole course on OpenAI Prompt Engineering using Python on the Finxter academy. We cover topics such as:
- Embeddings
- Semantic search
- Web scraping
- Query embeddings
- Movie recommendation
- Sentiment analysis
👨💻 Academy: Prompt Engineering with Python and OpenAI