
Overview
This article will be a tutorial on how to merge two pandas dataframes.

Often data might be stored in multiple places. Two or more dataframes containing different data but with a common denominator, and there is a need to merge these dataframes to get all the data into one dataframe
Pandas offer a handy method for accomplishing this task — the .merge() method.
Let’s have a look at the method and its parameters.

This part is obtained from the official pandas documentation[1]. Please see it for the complete information regarding allowed inputs for the method.
The second part of this guide will use a pandas method named .merge_asof() to merge data between dates and times, which can often be beneficial when working with different datasets.
Background
Let’s get into it and merge two dataframes.
The data used for this article is data containing information about some stocks from the S&P 500. The data is imported from CSV files.
One file has info on the current price of the stock. While the other file contains information regarding some financial ratios that are often used to evaluate a company.
# Import the necessary libraries
import pandas as pd
# Import data from CSV files to dataframes and display it
df_price = pd.read_csv('stock_data_price.csv')
df_key = pd.read_csv('stock_data_key.csv')
display(df_price, df_key)
As seen in the output above, the dataframes have the column ‘Ticker’ in common.
Let’s merge the dataframes based on that column. Note that some values are missing in the dataframe with the financial ratios.
# Perform a merge and display the new dataframe df_merged = df_price.merge(df_key, on='Ticker') display(df_merged)

By default, the merge method performs an 'inner' merge.
That means the merge looks at the df_price dataframe and then takes the matching rows of the df_key dataframe based on the 'Ticker' column.
That worked very well for this example since every ticker was present in both dataframes.
So, the dataframes merged nicely, and the desired output was obtained. In the upcoming examples, one of the dataframes will be decimated to show different types of merges.
Differenct Types of Merges
If the second dataframe containing the financial ratios numbers was to be cut in half and only had data about some of the companies that it previously did, like this.
# Slicing out every second row of the key figures dataframe df_key = df_key.iloc[1::2] display(df_key)

Now the default 'inner' merge will create the output.
# Merging with the new sliced second dataframe df_merged = df_price.merge(df_key, on='Ticker') display(df_merged)

As seen, only the rows that match and are present in both the dataframes are included in the resulting dataframe.
If all the rows from both dataframes should be included, the 'how' parameter of the merge method needs to be specified.
Let’s set it to perform an 'outer' merge.
# Outer merge of the dataframes
df_merged = df_price.merge(df_key,
on='Ticker',
how='outer')
display(df_merged)
Now, all the rows from both the dataframes will be included in the output.
Other options are to merge on 'left' or 'right', which will produce dataframes where either all the rows from the left dataframe are included, or all the rows from the right dataframe are included.
Note that since the financial ratios for many of the stocks are now missing, those columns will be filled with NaN.
# Left merge of the dataframes
df_left_merge = df_price.merge(df_key,
on='Ticker',
how='left')
display(df_left_merge)
# Right merge of the dataframes
df_right_merge = df_price.merge(df_key,
on='Ticker',
how='right')
display(df_right_merge)
Adding Suffixes to the Output Dataframe
The pandas merge method offers an excellent way of labeling the resulting dataframes column.
Sometimes columns have the same name in both dataframes, and after the merge, it isn’t apparent to know what is what.
The parameter suffixes of the merge method offer the possibility to solve this problem.
For this example, the dataframe with the financial ratios has also added the price column and now looks like this.

Now, both dataframes contain a column with the same name. If a merge is done now, both the price columns will be included.
The merge method will by default add the ending '_x' and '_y' to these columns, like this.
# Merging dataframes which both has the price column
df_merge_suffixes = df_price.merge(df_key,
on='Ticker')
display(df_merge_suffixes)
We see the default suffixes that have been added.
However, these are not very informative. It would be much better to have suffixes referring to which dataframe the data originated from. Liks this:
# Merging dataframes which both has the price column, adding suffixes
df_merge_suffixes = df_price.merge(df_key,
on='Ticker',
suffixes=('_price', '_key'))
display(df_merge_suffixes)
In this example, the effectiveness of using suffixes is not that apparent since both columns contain the same data.
It is beneficial, though if you have dataframes containing columns using the same name, but with different data, and there is a need to separate these.
How to Merge Between Dates and Times Using .merge_asof()
Often there might be a need to merge data, not on the exact value, but a value close by instead. That is common when working with dates and times.
The timestamp of each dataframe might not match exactly, but the values on the corresponding row before or after are close enough and can be used for the output. It sounds a bit messy but it’ll become more apparent when presented with examples below.
To do this in practice, stock data will once again be used. But this time, two dataframes with some information about a stock for one day of trading will be used. One shows the price of a stock, and one reveals that stock’s trading volume.
# Display the dataframes containing information about price and volume display(df_price, df_vol)
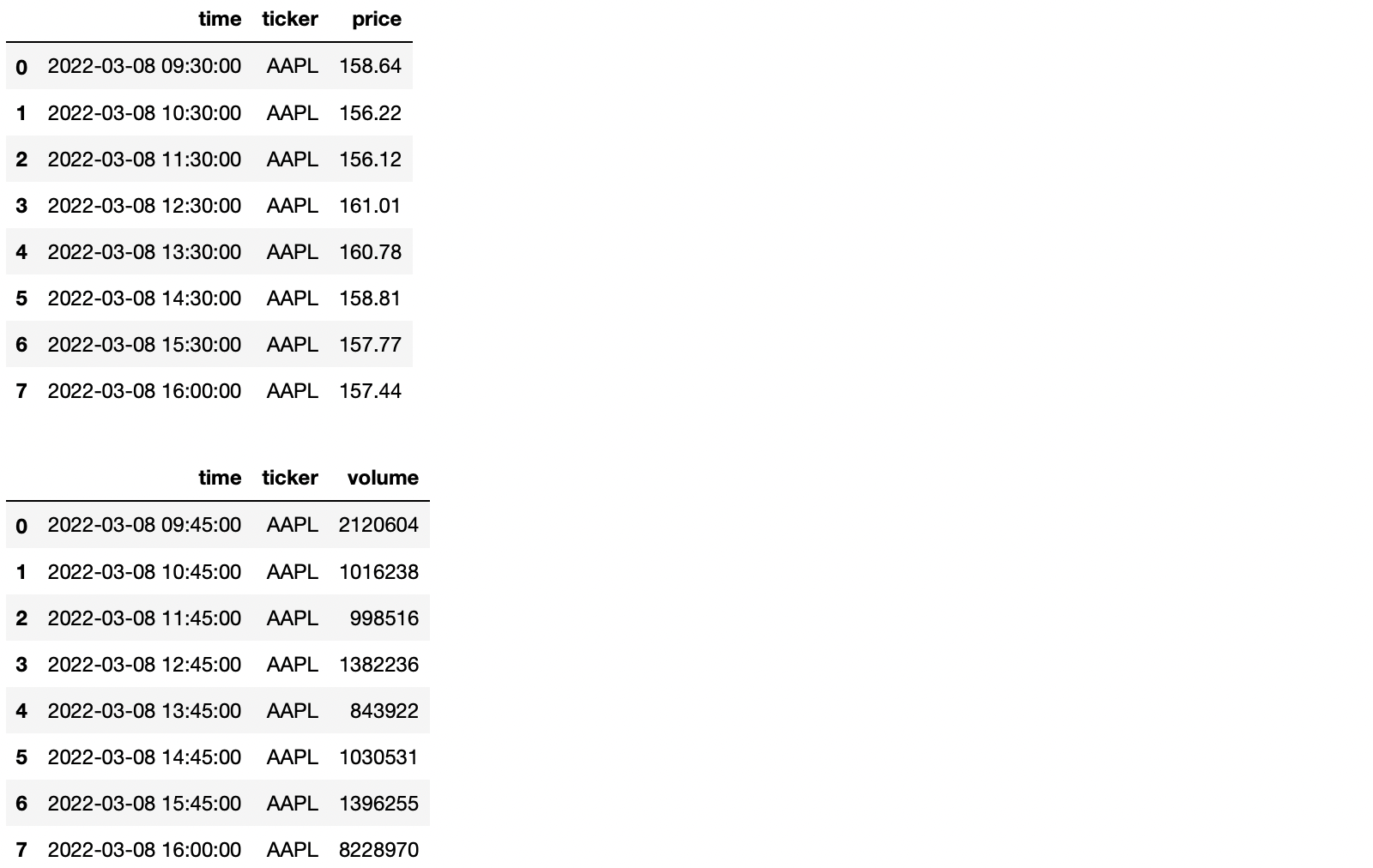
As seen, the times when the data points were sampled do not match. That will be a problem if we merge them together using the time column.
Luckily pandas has a method called .merge_asof() that will take care of this problem.

See the official documentation for the complete information regarding the method[2].
Let’s use the .merge_asof() method to merge the two dataframes.
# Merge the dataframes on time using .merge_asof() and forward fill
merged_df = pd.merge_asof(df_price, df_vol,
on='time',
by='ticker',
direction='forward')
display(merged_df)
So the .merge_asof() method allows for a merger of the dataframes based on the ‘time’ column.
In this case, the df_price dataframe was passed as the first argument, and therefore, its timestamps are used for the output.
What the merge_asof does is that it looks for the matching row that is closest in time and uses that value.
For this output, the direction parameter merge_asof() was set to 'forward'.
That means that when the merge is performed, it will look for the closest value in time ahead. So, for example, the 11:30:00 volume value is the value from 11:45:00 in the original df_vol dataframe.
.merge_asof() uses 'backward fill' by default, meaning that it will fill the value with the closest value in time backward.
Let’s set it to 'backward' and see what happens.
# Merge the dataframes on time using backward fill
df_merged = pd.merge_asof(df_price, df_vol,
on='time',
by='ticker',
direction='backward')
display(df_merged)
The value at 11:30:00 is instead filled by the value at 10:45:00 from the original dataframe since that value is the closest going backward in time.
Also, note that the first row for 09:30:00 has a NaN value for the volume column. Since there is no value to be found going backward in time and therefore .merge_asof() assigns NaN as default.
So this is a good way of filling data in between times if they do not match exactly.
But what if the value from the timestamp before or after, depending on which direction we merge on, is too far off in time?
Maybe the value is useless after 15 minutes and does not provide value. The .merge_asof() method has a great way of dealing with this.
As can be seen above, the method has a tolerance parameter. That can be set to a specific time that the closest timestamp must be within. Let’s see it.
# Merge the dataframes on time using tolerance
df_merged = pd.merge_asof(df_price, df_vol,
on='time',
by='ticker',
direction='backward',
tolerance=pd.Timedelta('10m'))
display(df_merged)
Since all the timestamps from the df_vol dateframe are off by 15 minutes in time except for one, and the tolerance is set to 10 minutes, we end up with a dataframe containing only one volume value.
The last timestamp is 16:00:00 for both dataframes, which is a perfect match, hence within the 10-minute tolerance set up.
Conclusion
That was a brief guide on how to merge dataframes using the .merge() method and how to merge dataframes in-between times using the .merge_asof() method.
Merging data in pandas is a vast topic, and there is a lot to learn and explore about it. I hope this guide provides some hands-on examples that will help you get started and then take it from there.
Happy merging and all the best!
References: