
The np.arange() function appears in 21% of the 35 million Github repositories that use the NumPy library! This illustrated tutorial shows you the ins and outs of the NumPy arange function. So let’s get started!
What’s the NumPy Arange Function?
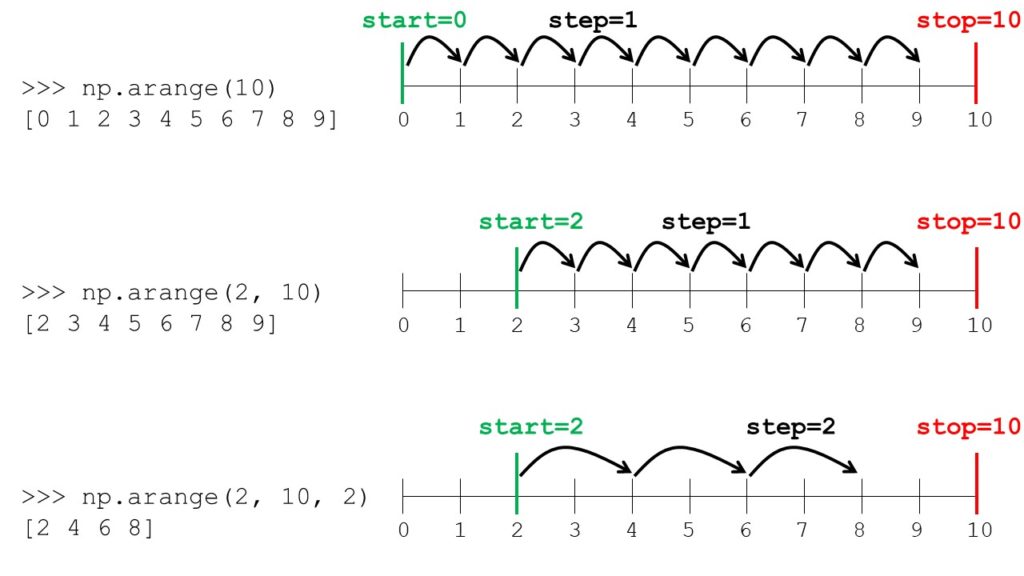
The np.arange([start,] stop[, step]) function creates a new NumPy array with evenly-spaced integers between start (inclusive) and stop (exclusive). The step size defines the difference between subsequent values. For example, np.arange(1, 6, 2) creates the NumPy array [1, 3, 5].
Have a look at the following graphic:
Video np.arange()
[Reading time: 4 minutes] – Or watch the video.
Syntax and Arguments of np.arange()
The NumPy arange() function (commonly misspelled: NumPy arrange) creates a NumPy array of evenly spaced numbers within a fixed interval.
| Argument | Type | Explanation |
|---|---|---|
start | int | Optional. Start of the interval (included). Default is 0. |
stop | int | Required. End of the interval (excluded). |
step | int | Optional. Step size (space) between two subsequent array values. Default is 1. |
dtype | dtype | Optional. The data type of the output array. Per default it’s inferred from input arguments. |
| Return Value | NumPy array of evenly-spaced values of dtype between start (included) and stop (excluded) with step size. |
Let’s explore these examples in the following code snippet that shows the four most important uses of the np.arange() function:
First, import the NumPy library:
import numpy as np
Now, you can use the np.arange() function to create sequences with equal step sizes in various ways. Go over the table and study the examples thoroughly:
| Example | Resulting NumPy Array |
|---|---|
np.arange(10) | array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) |
np.arange(2, 10) | array([2, 3, 4, 5, 6, 7, 8, 9]) |
np.arange(2, 10, 2) | array([2, 4, 6, 8]) |
np.arange(10, 0, -2) | array([10, 8, 6, 4, 2]) |
np.arange(10, 0, -1) | array([10, 9, 8, 7, 6, 5, 4, 3, 2, 1]) |
np.arange(5, 5) | array([], dtype=int32) |
np.arange(0, 5, 2, dtype=float) | array([0., 2., 4.]) |
np.arange(0, 5, 2, dtype=np.float32) | array([0., 2., 4.], dtype=float32) |
np.arange(6, 3, -0.5, dtype=np.float32) | array([6. , 5.5, 5. , 4.5, 4. , 3.5], dtype=float32) |
To master the NumPy arange function, read over the following basic function calls with different sets of arguments.
np.arange(stop)
Here’s the most basic example of the NumPy arange function. You only specify the stop argument. Like many other sequence operations, np.arange() starts at index 0. If you specify one stop argument, it is the same as setting the start argument to 0.
Let’s say, you want to represent the seven weekdays Monday-Sunday with seven sequential numbers 0-7.
>>> np.arange(7) array([0, 1, 2, 3, 4, 5, 6])
The result is a NumPy array with seven elements starting from the implicitly chosen index 0 (inclusive) and ending in the explicitly chosen index 7 (exclusive).
But what if we want to define a start index? Let’s say you feel anxious every Sunday evening because you hate going to work on Mondays for a big accountancy firm. First, you should get a new job as a programmer! Second, to stop working Mondays, we need to skip the start index 0.
np.arange(start, stop)
Your boss at the big accountancy firm has agreed to let you take every Monday off. Yay! Now we need to update the company records.
If you add a second argument to np.arange(start, stop), Python interprets the first one as the start index and the second one as the stop index.
>>> np.arange(1, 7) array([1, 2, 3, 4, 5, 6])
But what about the three-argument version.?
np.arange(start, stop, step)
Your new boss has asked you to fill in the days you want to work. You’d love to start your week on Tuesdays, but you’d also like more time off. So you say you’ll work every second day. Luckily, you have a solid salary as a programmer, so this isn’t a problem!
To do this, add a third argument to np.arange to set the step size. It is 2 in this case because you work every second day.
>>> np.arange(1, 7, 2) array([1, 3, 5])
Well done, now you only work on Tuesdays, Thursdays, and Saturdays! All programmers are lazy and you are lazy! It’s a perfect job for you.
But wait, there’s a problem… let’s move on to the four-argument function call to solve it.
np.arange(start, stop, step, dtype)
As you put your working days [1, 3, 5] into your company’s tracking system, it complains. Your NumPy array is formatted incorrectly. It expects all NumPy array values to be floats rather than integers. “What a design flaw for weekday data!”.
Thankfully, there is a simple fix. We need to use the fourth argument of np.arange() to set the data type (dtype) of the output array. The dtype argument accepts two kinds of data types. First, traditional language-specific data types such as float and integer. Second, NumPy-specific data types such as np.int16 or np.float32.
For instance, the NumPy-specific data types np.int16 or np.float32 allow for an integer value with 16 bits (=2 bytes) or a float value with 32 bits (=4 bytes). Keep in mind that more bits leads to higher overheads. But it gives you a greater range of numbers to work with (or greater precision in the case of floats). Here is a collection of dtypes you can use (check out this excellent post if you need more information about NumPy dtypes):
bool: The default boolean data type in Python (1 Byte).int: The default Python integer data type in Python (4 or 8 Bytes).float: The default float data type in Python (8 Bytes).complex: The default complex data type in Python (16 Bytes).np.int8: Integer (1 Byte).np.int16: Integer (2 Bytes).np.int32: Integer (4 Bytes).np.int64: Integer (8 Bytes).np.float16: Float (2 Bytes).np.float32: Float (4 Bytes).np.float64: Float (8 Bytes).
By default, NumPy chooses np.float64 and np.int64 for floats and integers. So only specify a different dtype if you want something other than those. At the start of your Python journey, it’s unlikely you will need to deeply understand the different dtypes. Once you start working on more complex problems, you will need this knowledge though.
Lastly, note that you can only spot differences once numbers get large. The largest np.int8 is 127 but the largest np.int16 is 32767. Yet, if you compare np.int8 127 and np.int16 127, they are the same.
>>> np.int8(127) == np.int16(127) True
Here is an example of the 4-argument version of np.arange():
>>> np.arange(1, 7, 2, dtype=np.float32) array([1., 3., 5.], dtype=float32)
You’ve completed the first part of the NumPy arange tutorial! But the one who prepares best wins. Let’s dive into some practice examples and attack the highest level of NumPy arange expertise!
Interactive Shell NumPy Arange
Can you solve the following basic puzzle about NumPy arange?
Exercise: Guess the output of this code snippet. Then, run the code snippet to check your result!
Examples
You have mastered all four different uses of the NumPy arange() function. To wrap things up, make sure to work through this more comprehensive list of examples:
>>> np.arange(10) array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> np.arange(2, 10, 3) array([2, 5, 8]) # Non-integer step sizes np.arange(1.5, 10., 1.5) array([1.5, 3., 4.5, 6., 7.5, 9. ]) # Create np.arange in reverse with a negative step size # Start is inclusive, end is exclusive so it stops at 2 >>> np.arange(10, 1, -1) array([10, 9, 8, 7, 6, 5, 4, 3, 2]) # Reversed and select every second value >>> np.arange(10, 1, -2) array([10, 8, 6, 4, 2]) # Reversed non-integer step size >>> np.arange(9.7, 9.2, -0.1) array([9.7, 9.6, 9.5, 9.4, 9.3]) # End being exclusive beats the start being inclusive >>> np.arange(1, 1, 1) array([], dtype=int64) >>> np.arange(1, 5, dtype=np.int16) array([1, 2, 3, 4], dtype=int16) >>> np.arange(1, 5, dtype=np.float32) array([1., 2., 3., 4.], dtype=float32)
I‘ve also added several NumPy arange puzzles to my puzzle-based learning app Finxter.com. Check it out to train yourself and become a master coder.
Finxter App: Test your skills now!
Questions np.arange()
Congratulations, you now know the most important details about the NumPy arange function. But you may still have a few questions. Let’s answer them one by one!
np.arange vs np.linspace – When Should I Use Which One?
Use np.arange() if you want to create integer sequences with evenly distributed integer values within a fixed interval.
Use np.linspace() if you have a non-integer step size. The np.linspace function handles the endpoints better. This prevents you from introducing unnecessary bugs into your code. One such bug is when you assume an endpoint is not in the NumPy array but it is because of floating-point arithmetic.
If you want to understand the NumPy linspace() function in detail, check out our blog article.
What Are Some np.arange() Use Cases?
NumPy is mostly about multi-dimensional matrices. It is common to create a 1D NumPy array with the NumPy arange function and to transform it immediately into a 2D array using the np.reshape() function. Below we create a 2D array with three rows and two columns from a 1D array.
np.arange(6).reshape((3, 2)) # array([[0, 1], # [2, 3], # [4, 5]])
np.arange vs range – What’s the Difference?
You’re probably familiar with the built-in range() function. We use it all the time to write for loops and list comprehensions.
>>> for i in range(5):
print(i)
0
1
2
3
4
# Square numbers from 0-4
>>> squares = [i**2 for i in range(5)]
>>> squares
[0, 1, 4, 9, 16]So can we do the same with np.arange? And even if we can, should we?
Let’s first see if it’s possible.
# Works the same as range()
>>> for i in np.arange(5):
print(i)
0
1
2
3
4
# Also works the same as range()
>>> np_squares = [i**2 for i in np.arange(5)]
>>> np_squares
[0, 1, 4, 9, 16]
# They're even identical!
>>> np_squares == squares
TrueSo it seems like we can do the same with both functions. But we’re working with a tiny amount of data. What happens if we work with much larger numbers?
np.arange vs range – How to Work with Big Data?
We’ll use iPython’s magic function %timeit to see how long our for loops take when using np.arange or range.
# Only works in iPython In [1]: %timeit for i in np.arange(1000000): pass 78.1 ms ± 4.9 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) In [2]: %timeit for i in range(1000000): pass 32.8 ms ± 899 µs per loop (mean ± std. dev. of 7 runs, 10 loops each) # range is more than twice as fast! In [3]: 78.1 / 32.8 Out[3]: 2.381...
This happens because the two functions work differently. The function range() is a generator function. It creates the next value when it needs to and stops once it has run out. This makes it very efficient. But np.arange creates an array of length 1,000,000 and stores it in memory. This is computationally expensive for Python and slows it down. Thus, if you are ever looping, you should use range(). It’s much faster.
However, there is a time when you should not use range.
How to Iterate Over Large NumPy Arrays
Let’s say you have a NumPy array, A, containing 1 million values. You want to create a new array, B, by performing a calculation on each element of A. For this example, we will add 1 to every element of A to get B.
First, we create an array of 1 million random numbers using the random module and a list comprehension. Check out our article to learn more about this built-in library.
>>> import random # Set seed so we can reproduce our results >>> random.seed(1) # Use list comprehension to generate random numbers >>> A = [random.random() for i in range(1000000)] # Convert to a numpy array >>> A = np.array(A) # Check first 5 values (you should have the same as me) >>> A[:5] [0.13436424411240122, 0.8474337369372327, 0.763774618976614, 0.2550690257394217, 0.49543508709194095]
Let’s first create B using a for loop:
>>> B = np.array([])
>>> for i in A:
B.append(i + 1)
# Check first 5 values - looks good
>>> B[:5]
[1.134364244112401, 1.8474337369372327, 1.7637746189766141, 1.2550690257394217, 1.4954350870919408]Let’s time it:
# Only works in iPython In [1]: B = np.array([]) # NumPy arrays don't have an .append() method so we use np.append() In [2]: %timeit for i in A: np.append(B, i+1) 6.91 s ± 628 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
That is rather slow. Can we make this any faster? As NumPy arrays are made up of lists, we can do this using a list comprehension. Let’s see if this improves the speed.
In [3]: %timeit B = np.array([i+1 for i in A]) 600 ms ± 19.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Wow! That’s 11.5x faster than using a for loop! But can we get even faster? Yes, we can and the answer is: vectorized computation.
Most of the time, the operation you want to perform can be done using functions. You should always use these as they have been optimised by the NumPy developers. Check out this Stack Overflow answer for an introduction. We can, and probably will, write a full article on this topic soon. But for now, check out Chapter 4 from Python for Data Analysis by Wes McKinney.
The fastest way to solve this is to use NumPy’s broadcasting property i.e. if we +1 to a NumPy array it ‘broadcasts’ this to all the elements of the array.
In [4]: %timeit B = A + 1 1.99 ms ± 386 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
This is 3,455x faster than using a for loop. It will take some time to get used to using vectorized computations. But once you get used to it, you will save a lot of time.
🌍 Recommended Finxter Tutorial: How to Iterate over a NumPy Array?
Summary
The np.arange([start,] stop[, step]) function creates a new NumPy array with evenly-spaced integers between start (inclusive) and stop (exclusive). The step size defines the difference between subsequent values.
Consider the following examples:
import numpy as np # np.arange(stop) >>> np.arange(10) array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) # np.arange(start, stop) >>> np.arange(2, 10) array([2, 3, 4, 5, 6, 7, 8, 9]) # np.arange(start, stop, step) >>> np.arange(2, 10, 2) array([2, 4, 6, 8]) # np.arange(start, stop, step, dtype) >>> np.arange(2, 10, 2, float) array([2., 4., 6., 8.])
The examples show all four variants of using np.arange() with one, two, three, or four arguments.
Where to Go From Here?
How to join the top earners in any field? Read more books!
Because I always find it difficult to find time to learn, I have written a new NumPy book that can be entirely consumed in small doses — for example as you drink your daily morning coffee.
Don’t miss out on this exciting new way of learning to code — it’s so much more fun! 🙂

Thanks for your nice post. However, I am prefering numpy linspace for the reasons given above.