
This tutorial gives you a simple introduction to Python’s NumPy library. You don’t need any prerequisites to follow the tutorial. My goal was to give a practical and fun NumPy introduction for absolute beginners with many examples.
💡 By reading through this tutorial, you will gain a basic understanding of the most important NumPy functionality. Moreover, I will give you references to further reading as well as “next steps”. Reading this tutorial takes between 20-30 minutes.
But never mind: Don’t fear to invest the time studying this tutorial. It’s an investment in your education and your coding efficiency. It’s my belief that the purpose of any good learning material is to save, not take, your time.
After finishing the tutorial, I realized that it became a >7000-word article. So I am in the process of publishing an extended version as an ebook right now.
Edit: in the meantime, I published a new NumPy textbook based on puzzle-based learning. You can download it for free here:

If you feel like it, I’d be super grateful if you share this Finxter tutorial with a friend so they can download the NumPy ebook too! 👍
NumPy Cheat Sheet (PDF)
Here’s another quick download for you before we get started: I created this cheating sheet to explain some important NumPy concepts to my coding students.

You can also download more Python-related cheat sheets here:
NumPy Video
I have also created a comprehensive NumPy video tutorial for beginners based on much of the content here:
So without further introduction, let’s dive into the NumPy library in Python.
What is NumPy?
💡 NumPy is a Python library that allows you to perform numerical calculations. Think about linear algebra in school (or university) – NumPy is the Python library for it. It’s about matrices and vectors – and doing operations on top of them.
At the heart of NumPy is a basic data type, called a NumPy array.
What is a NumPy Array?
💡 A NumPy array is a multi-dimensional matrix of numerical data values (integers or floats). Unlike Python lists that allow arbitrary data types, a NumPy array is used for numerical data values only.
NumPy is even more restrictive than focusing only on numerical data values. It normally comprises homogeneous data values. This means that a numpy array contains either integer or float values, but not both at the same time.
For example, you can create your first NumPy array as easily as this:
import numpy as np a = np.array([1, 2, 3])
We’ll discuss array creation and array operations in more detail later.
What Are NumPy Array Operations?
These data type restrictions allow NumPy to specialize in providing efficient linear algebra operations.
Operations: Among those operations are maximum, minimum, average, standard deviation, variance, dot product, matrix product, and many more.
NumPy implements these operations efficiently and in a rigorous consistent manner. By learning NumPy, you equip yourself with a powerful tool for data analysis on numerical multi-dimensional data.
But you may ask (and rightly so):
What is the Purpose of NumPy?
Fear of missing out on machine learning and data science?
Learning NumPy now is a great first step into the field of machine learning and data science. In machine learning, crucial algorithms and data structures rely on matrix computations.
🌍 Related Tutorial: NumPy Developer — Income and Opportunity
Most machine learning experts agree that Python is the top programming language for machine learning. Numpy is among the most popular libraries in Python (e.g. see this article) as one of the most important libraries for data science and machine learning.
For instance, searching for the keyword ‘numpy machine learning’ reveals more than 3 million results!

Compare this to the scikit-learn library that directly addresses machine learning:

As you can see, NumPy produces more results – even though it is not directly addressing machine learning (unlike scikit-learn).
No matter which library is more popular – NumPy is the 600-pound Gorilla in the machine learning and data science space. If you are serious about your career as a data scientist, you have to conquer NumPy now!
What Are Some Application Areas of NumPy?
But NumPy is not only important for machine learning and data science. More conservative areas rely on it, too. People use NumPy in maths, electrical engineering, high-performance computing, simulations, and many more areas.
Also, if you need to visualize data, you very much rely on the numpy library.
Here is an example from the official documentation of Python’s plotting library Matplotlib (slightly restyled ;)). You can see a small script that plots a linear, quadratic, and cubic function. It uses only two libraries: Matplotlib and … NumPy!
import numpy as np
import matplotlib.pyplot as plt
# evenly distributed data between 0 and 1
x = np.arange(0., 1., 0.1)
# xkcd-styled plot
plt.xkcd()
# linear, quadratic, and cubic plots
plt.plot(x, x, 'v-', x, x**2, 'x-', x, x**3, 'o-')
plt.savefig("functions.jpg")
plt.show()
Wherever you go in data science with Python, NumPy is already there!
What are the Limitations of NumPy?
The focus of NumPy is working with numerical data. It’s both: powerful and low-level (it provides basic functionality for high-level algorithms).
If you enter the machine learning and data science space, you want to master NumPy first. But eventually, you will use other libraries that operate on a higher level, such as Tensorflow and scikit-learn. Those libraries contain out-of-the-box machine learning functions such as training and inference algorithms. Have a look at them after reading this tutorial.
If you enter mathematical areas that are not close to linear algebra, you may want to shift your focus to other libraries that better suit your needs. Examples are matplotlib and pyqtgraph.
In any case, NumPy will help you understand more advanced libraries. To be frank, I had problems finding limitations of NumPy. Search the web – you won’t find many people complaining about numpy.
NumPy Quickstart – A Guided Example
In this section, I’ll only show you how to solve a day-to-day accounting task – which would usually take many lines of Python code – in a single line of code. I’ll also introduce you to some elementary functionalities of Python’s wildly important library for numerical computations and data science: NumPy.
At the heart of the NumPy library are NumPy arrays (in short: arrays). The NumPy array holds all your data to be manipulated, analyzed, and visualized.
And even higher-level data science libraries like Pandas use NumPy arrays implicitly or explicitly for their data analysis. You can think of a NumPy array as a Python list that can be nested, and which has some special properties and restrictions.
For instance, an array consists of one or more axes (think of it as “dimensions”).
Creating 1D, 2D, and 3D NumPy Arrays
Here is an example of one-dimensional, two-dimensional, and three-dimensional NumPy arrays:
import numpy as np
# 1D array
a = np.array([1, 2, 3])
print(a)
"""
[1 2 3]
"""
# 2D array
b = np.array([[1, 2],
[3, 4]])
print(b)
"""
[[1 2]
[3 4]]
"""
# 3D array
c = np.array([[[1, 2], [3, 4]],
[[5, 6], [7, 8]]])
print(c)
"""
[[[1 2]
[3 4]]
[[5 6]
[7 8]]]
"""
Creating a NumPy array is as simple as passing a normal Python list as an argument into the function np.array().
- You can see that a one-dimensional array corresponds to a simple list of numerical values.
- A two-dimensional array corresponds to a nested list of lists of numerical values.
- Finally, a three-dimensional array corresponds to a nested list of lists of lists of numerical values.
You can easily create higher-dimensional arrays with the same procedure.
👍 Rule of thumb: The number of opening brackets gives you the dimensionality of the NumPy array.
NumPy Arithmetic Operations
One of the advantages of NumPy arrays is that they have overloaded the basic arithmetic operators ‘+’, ‘-‘, ‘*’, and ‘/’. Semantically, think of these as “element-wise operations”.
For example, see how the following two-dimensional array operations perform:
import numpy as np
a = np.array([[1, 0, 0],
[1, 1, 1],
[2, 0, 0]])
b = np.array([[1, 1, 1],
[1, 1, 2],
[1, 1, 2]])
print(a + b)
"""
[[2 1 1]
[2 2 3]
[3 1 2]]
"""
print(a - b)
"""
[[ 0 -1 -1]
[ 0 0 -1]
[ 1 -1 -2]]
"""
print(a * b)
"""
[[1 0 0]
[1 1 2]
[2 0 0]]
"""
print(a / b)
"""
[[1. 0. 0. ]
[1. 1. 0.5]
[2. 0. 0. ]]
"""
Looking closely, you’ll find that each operation combines two NumPy arrays element-wise.
For example, the addition of two arrays results in a new array where each new value is the sum of the corresponding value of the first and the second array.
NumPy Statistical Operations
But NumPy provides a lot more capabilities for manipulating arrays.
- For example, the
np.max()function calculates the maximal value of all values in a NumPy array. - The
np.min()function calculates the minimal value of all values in a NumPy array. - And the
np.average()function calculates the average value of all values in a NumPy array.
Here is an example of those three operations:
import numpy as np
a = np.array([[1, 0, 0],
[1, 1, 1],
[2, 0, 0]])
print(np.max(a))
# 2
print(np.min(a))
# 0
print(np.average(a))
# 0.6666666666666666
The maximal value of all values in the NumPy array is 2, the minimum value is 0, and the average is (1+0+0+1+1+1+2+0+0)/9=2/3.
Example Problem Solving with NumPy Operations
Again, NumPy is much more powerful than that – but this is already enough to solve the following problem: “How to find the maximal after-tax income of a number of people, given their yearly salary and tax rates?”
Let’s have a look at this problem. Given is the salary data of Alice, Bob, and Tim. It seems like Bob has enjoyed the highest salary in the last three years. But is this really the case considering the individual tax rates of our three friends?
## Dependencies
import numpy as np
## Data: yearly salary in ($1000) [2017, 2018, 2019]
alice = [99, 101, 103]
bob = [110, 108, 105]
tim = [90, 88, 85]
salaries = np.array([alice, bob, tim])
taxation = np.array([[0.2, 0.25, 0.22],
[0.4, 0.5, 0.5],
[0.1, 0.2, 0.1]])
## One-liner
max_income = np.max(salaries - salaries * taxation)
## Result
print(max_income)
Take a guess: what’s the output of this code snippet?
In the code snippet, the first statements import the NumPy library into the namespace using the de-facto standard name for the NumPy library: np.
The following few statements create the data consisting of a two-dimensional NumPy array with three rows (one row for each person Alice, Bob, and Tim) and three columns (one column for each year 2017, 2018, and 2019). I created two matrices: salaries and taxation. The former holds the yearly incomes, while the latter holds the taxation rates for each person and year.
To calculate the after-tax income, you need to deduct the tax (as a Dollar amount) from the gross income stored in the array ‘salaries’. We use the overloaded NumPy operators ‘-‘ and ‘*’ to achieve exactly this. Again, both operators perform element-wise computations on the NumPy arrays.
💡 As a side-note, the element-wise multiplication of two matrices is called “Hadamard product”.
Let’s examine how the NumPy array looks like after deducing the taxes from the gross incomes:
print(salaries - salaries * taxation) """ [[79.2 75.75 80.34] [66. 54. 52.5 ] [81. 70.4 76.5 ]] """
You can see that the large income of Bob (see the second row of the NumPy array) vanishes after paying 40% and 50% of taxes.
In the one-liner, we print the maximal value of this resulting array. Per default, the np.max() function simply finds the maximal value of all values in the array. Thus, the maximal value is Tim’s $90,000 income in 2017 which is taxed only by 10% – the result of the one-liner is “81.”
Check out my new Python book Python One-Liners (Amazon Link).
If you like one-liners, you’ll LOVE the book. It’ll teach you everything there is to know about a single line of Python code. But it’s also an introduction to computer science, data science, machine learning, and algorithms. The universe in a single line of Python!

The book was released in 2020 with the world-class programming book publisher NoStarch Press (San Francisco).
Publisher Link: https://nostarch.com/pythononeliners
What are the Linear Algebra Basics You Need to Know?
NumPy is all about manipulating arrays. By learning NumPy, you will also learn and refresh your linear algebra skills from school. Only if you have very little knowledge about linear algebra, you should work through a quick tutorial before diving into the NumPy library. It’s always better to learn the concepts first and the tools later. NumPy is only a specific tool that implements the concepts of linear algebra.
Watch this awesome tutorial from Khan Academy. It will give you a quickstart into linear algebra and matrix operations.
If you cannot watch the video, here is an ultra-short tutorial:
At the center of linear algebra stands the solution of linear equations. Here is one of those equations:
y = 2x + 4
If you plot this equation, you get the following output:

As you can see, the equation y = 2x + 4 leads to a straight line on the space. This line helps you to read for any input x the corresponding output y.
Let me repeat this: You can get for any input x the corresponding output y.
As it turns out, this is the goal of any machine learning technique. You have a bunch of data values. You find a function that describes this bunch of data values. (We call this the learning phase.) Now you can use the learned function to “predict” the output value for any new input value. This works, even if you have never seen this input before. (We call this the inference phase.)
Linear algebra helps you solve equations to do exactly that.
Here is an example with some fake data. Say, you have learned the relationship between the work ethics (in number of hours worked per day) and hourly wage (in US-Dollar). Your learned relationship (in machine learning terms: model) is the above equation y = 2x + 4. The input x is the number of hours worked per day and the output y is the hourly waged.
With this model, you could predict how much your boss earns by observing how much he or she use to work. It’s a machine: you put in x and get out y. This is what machine learning is all about.
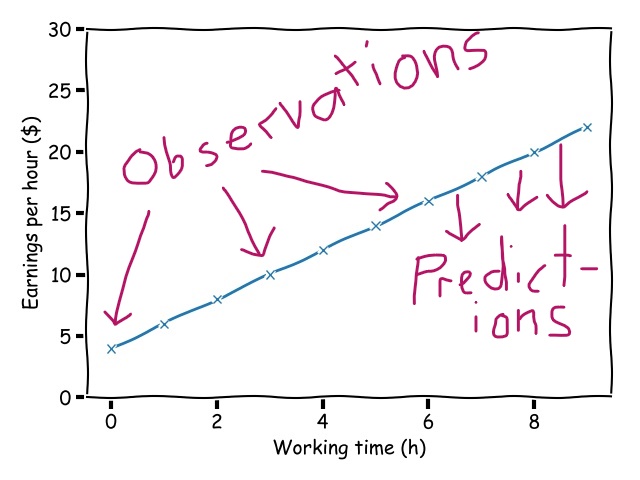
Here is the script that does this plot for us. We can learn something out of it.
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(0., 10., 1)
# [0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]
y = 2 * x + 4
# [ 4. 6. 8. 10. 12. 14. 16. 18. 20. 22.]
print(x)
print(y)
# xkcd-styled plot
plt.xkcd()
plt.plot(x, y, 'x-')
plt.xlabel("Working time (h)")
plt.ylabel("Earnings per hour ($)")
plt.ylim((0,30))
plt.tight_layout()
plt.savefig("simple_linear_equation_example.jpg")
plt.show()As you can see, before doing anything else in the script, we have to import the numpy library. You can do this with the statement ‘import numpy as np‘. Each time you want to call a numpy function, you will then use the name prefix ‘np‘ (e.g. np.average(x)). In theory, you can specify every other name prefix. But you should not do this. The prefix ‘np‘ has crystallized as a convention for naming the NumPy library and so every (more or less) experienced coder will expect this name.
After this initial import, we create a series of floating point values between 0 and 9. These values serve as the x values which we want to map to their respective function values y=f(x). The variable x holds a numpy array of those floating point values.
The variable y holds a numpy array of the same size. It’s our output – one for each observed x value. Do you see the basic arithmetic of how to get the y values?
The equation y = 2 * x + 4 seems to do the same thing as discussed in the previous equation. But as it turns out, the meaning is very different: x is not a numerical value, it is a numpy array!
When calculating y = 2 * x + 4, we are basically multiplying the numpy array with 2 and adding the constant 4 to it. These are basic mathematical operations on multi-dimensional (numpy) arrays, not numerical values.
Investigating these kinds of operations lies at the core of linear algebra. The numpy array in the example is called a one-dimensional matrix (or vector) of floating values. The matrix x consists of ten floating values between 0 and 9 (inclusive): [0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]. How do we know that the values in the array are of type float? We indicate this by writing a small dot '.' after the matrix values (it’s nothing but a short form of [0.0 1.0 2.0 … 9.0]).
The linear algebra magic of numpy calculates the respective y values. Then, we plot the result using the library matplotlib.
In the two-dimensional space shown in the plot, we work with one-dimensional arrays. Each numerical input value leads to an output value. One observation (e.g. “worked 4 hours per day”) leads to one prediction (e.g. “earned $12 per hour”). But real problems are far more complex than that.
Think about it, we have to consider a multitude of other factors to accurately predict the hourly wage of a person. For example, their education (number of years studied), their family (number of kids), their experience (number of years worked in the job), and so on.
In this case, each observation (input) is not a single factor as in the last plot but a collection of factors. We express a single input value as a one-dimensional matrix to account for the multiple relevant observations. Together, the observations within this one-dimensional matrix lead to a single output. Here is an example:

In the last example, we predicted each output based on a zero-dimensional matrix (= the float value: hours worked per day). In this example, we predict each output based on a one-dimensional matrix (with float values for experience, education, and family). Hence, each observation is already a one-dimensional matrix.
In the first plotting script, we lined up all the zero-dimensional observations to a one-dimensional matrix. In a similar fashion, we can now line up all the one-dimensional observations to a two-dimensional matrix. The following graphic shows you how to do this.

There are four observations in the graphic (with three factors for each observation): [4, 4, 3], [3, 3, 0], [4, 1, 4], [2, 12, 1] – each being a one-dimensional matrix. We collect those observations in a two-dimensional observation matrix. Each row of this matrix consists of one observation. Each column consists of all observations for a single factor. For example, the first row [4, 4, 3] stands for the first observation: [experience = 4, education = 4, family = 3]. The first column [4, 3, 4, 2] stands for all the observed values of the factor “experience”.
Now recap our goal: we want to calculate the y value (=hourly wage) based on the observed factors “x1 = experience”, “x2 = education”, and “x3 = family”. So let’s assume that a magic oracle (e.g. a machine learning algorithm) tells us that you can calculate the hourly wage by summing up those factors: y = x1 + x2 + x3. For example, the first observation leads to y = x1 + x2 + x3 = 4 + 4 + 3 = 11. In plain English: if you have four years of experience, four years of education, and 3 kids, you will earn $11 per hour.
Now, instead of using numerical values, we can also use the factor vectors as x1, x2, and x3 – and the equation still works. So instead of setting x1 = 4, x2 = 4, and x3 = 3, you can set x1 = [4, 3, 4, 2], x2 = [4, 3, 1, 12], and x3 = [3, 0, 4, 1]. Why should you do that? Because it allows you to calculate the predictions of ALL observation in a single step.

In each row, we calculate the prediction of one person. Each of the sum operands is a one-dimensional matrix (vector). As we are calculating the sum of the vectors (rather than the sum of the numerical values), we get a resulting vector [11, 6, 9, 15] that holds the predicted hourly wages of each of the four persons.
At this point, you have already learned how and why to add vectors (or one-dimensional matrices). It allows the computer to crunch large amounts of data (and predict hourly wages for a large number of persons). I would love to go more deeply into this topic but I just found a beautiful article that will teach you linear algebra in a visual manner. Check out this awesome blog article for further reading on this topic.
What are Arrays and Matrices in NumPy?
Are you confused about the terms matrices, arrays, vectors? Don’t despair. In NumPy, there is only one data structure: numpy arrays. A numpy array can be one-dimensional, two-dimensional, or 1000-dimensional. It’s one concept to rule them all.
The NumPy array is the core object of the whole library. You have to know it by heart before you can go on and understand the operations provided by the NumPy library. So what is the NumPy array?
It’s a data structure that stores a bunch of numerical values. But there are important restrictions of which values to store.
First, all numerical values have the same data type. In many NumPy tutorials, you will find the statement: “NumPy arrays are homogeneous”. This means the same thing: all values have the same type. In particular, these are the possible data types of a NumPy array:
- bool: The default boolean data type in Python (1 Byte).
- int: The default Python integer data type in Python (4 or 8 Bytes).
- float: The default float data type in Python (8 Bytes).
- complex: The default complex data type in Python (16 Bytes).
- np.int8: An integer data type (1 Byte).
- np.int16: An integer data type (2 Bytes).
- np.int32: An integer data type (4 Bytes).
- np.int64: An integer data type (8 Bytes).
- np.float16: A float data type (2 Bytes).
- np.float32: A float data type (4 Bytes).
- np.float64: A float data type (8 Bytes).
Here is an example that shows you how to create numpy arrays of different data types.
import numpy as np a = np.array([1, 2, 3], dtype=np.int16) print(a) # [1 2 3] print(a.dtype) # int16 b = np.array([1, 2, 3], dtype=np.float64) print(b) # [1. 2. 3.] print(b.dtype) # float64
In the example, we created two arrays.
The first array a is of data type np.int16. If we print the array, we can already see that the numbers are of type integer (there is no “dot” after the number). In specific, when printing out the dtype property of the array a, we get the result int16.
The second array b is of data type float64. So even if we pass a list of integers as a function argument, NumPy will convert the type to np.float64.
You should remember two things from this example:
- NumPy gives you control about the data, and
- The data in a NumPy array is homogeneous (= of the same type).
What are Axes and the Shape of a NumPy Array?
The second restriction of numpy arrays is the following. Numpy does not simply store a bunch of data values loosely (you can use lists for that). Instead, NumPy imposes a strict ordering to the data – it creates fixed-sized axes. Don’t confuse an axis with a dimension.
💡 A point in 3D space, e.g. [1, 2, 3] has three dimensions but only a single axis.
So what is an axis in NumPy? Think of it as the depth of your nested data. If you want to know the number of axes in NumPy, count the number of opening brackets ‘[‘ until you reach the first numerical value. Here is an example:
import numpy as np
a = np.array([1, 2, 3])
print(a.ndim)
# 1
b = np.array([[1, 2], [2, 3], [3, 4]])
print(b.ndim)
# 2
c = np.array([[[1, 2], [2, 3], [3, 4]],
[[1, 2], [2, 3], [3, 4]]])
print(c.ndim)
# 3We create three numpy arrays a, b, and c. For each array, we print the number of axes. How do we know this? Numpy stores the number of axes in the array property ndim. As you can see, counting the number of nested lists gives you the correct number of axes of your numpy array.
But there is another important information you will often need to know about your numpy array: the shape. The shape gives you not only the number of axes but also the number of elements in each axis (the dimensionality).
Here is an example:
import numpy as np
a = np.array([1, 2, 3])
print(a.shape)
# (3, )
b = np.array([[1, 2], [2, 3], [3, 4]])
print(b.shape)
# (3, 2)
c = np.array([[[1, 2], [2, 3], [3, 4]],
[[1, 2], [2, 3], [3, 4]]])
print(c.shape)
# (2, 3, 2)Study this example carefully. The shape property gives you three types of information about each array.
First, it shows you the number of axes per array – that is – the length of the tuple. Array a has one axis, array b has two axes, and array c has three axes.
Second, it shows you the length of each axis as the numerical value. For example, array a has one axis with three elements. Hence, the shape of the array is (3, ). Don’t get confused by this weird tuple notation. The reason why the NumPy shape operation does not return a tuple with a single element (3) is: Python converts it to a numerical value 3. This has the following benefit. If you access the first element of your shape object a.shape[0], the interpreter does not throw an exception this way.
Third, it shows you the ordering of the axes. Consider array c. It has three tuple values (2, 3, 2). Which tuple value is for which axis?
- The first tuple value is the number of elements in the first level of nested lists. In other words: how many elements are in the outermost list? The outermost list for c is
[X1, X2]where X1 and X2 are nested lists themselves. Hence, the first axis consists of two elements. - But what’s the number of elements for the second axis? Let’s check the axis X1. It has the shape
X1 = [Y1, Y2, Y3]where Y1, Y2, and Y3 are lists themselves. As there are three such elements, the result is 3 for the second tuple value. - Finally, you check the innermost axis Y1. It consists of two elements [1, 2], so there are two elements for the third axis.
💡 In summary, the axes are ordered from the outermost to the innermost nesting level. The number of axes is stored in the ndim property. The shape property shows you the number of elements on each axis.
How to Create and Initialize NumPy Arrays?
There are many ways to create and initialize numpy arrays. You have already seen some of them in the previous examples. But the easiest way to create a numpy array is via the function np.array(s). You simply put in a sequence s of homogeneous numerical values and voilà – you get your NumPy array.
Here is an example:
import numpy as np a = np.array([1, 2, 3]) print(a) # [1 2 3] b = np.array((1, 2, 3)) print(b) # [1 2 3] c = np.array([1.0, 2.0, 3.0]) print(c) # [1. 2. 3.]
In the example, we create three arrays a, b, and c. The sequence argument for array a is a list of integer values. The sequence argument for array b is a tuple of integer values. Both produce the same NumPy array of integer values. The sequence argument for array c is a list of floats. As you can see, the result is a NumPy array of float values.
But how can you create multi-dimensional arrays? Simply pass a sequence of sequences as arguments to create a two-dimensional array. Pass a sequence of sequences of sequences to create a three-dimensional array and so on.
Here is an example:
import numpy as np
# 2D numpy array
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a.shape)
# 3D numpy array
b = np.array([[[1, 2], [3, 4], [5, 6]],
[[1, 2], [3, 4], [5, 6]]])
print(b.shape)Puzzle: What is the output of this code snippet?
Answer: The puzzle prints two shape objects. The shape of array a is (2, 3) because the first axis has two elements and the second axis has three elements. The shape of array b is (2, 3, 2) because the first axis has two elements (sequences of sequences), the second axis has three elements (sequences), and the third axis has two elements (integers).
Having at least one floating type element, the whole numpy array is converted to a floating type array. The reason is that numpy arrays have homogeneously typed data. Here is an example of such a situation:
import numpy as np a = np.array([[1, 2, 3.0], [4, 5, 6]]) print(a) # [[1. 2. 3.] # [4. 5. 6.]]
Now, let’s move on to more automated ways to create NumPy arrays. For the toy examples given above, you can simply type in the whole array. But what if you want to create huge arrays with thousands of values?
You can use NumPy’s array creation routines called ones(shape) and zeros(shape).
All you have to do is specify the shape tuple you have seen in the last paragraphs. Suppose you want a 5-dimensional array with 1000 values per dimension, initialized with 0.0 values. Using these routines, you would simply call: np.zeros((1000, 1000, 1000, 1000, 1000)). Let’s not print this to the shell! 😉
As it turns out, this simple array creation routine overwhelms your computer’s memory capacity. The Python interpreter throws an error when you try to create a NumPy array of this size. Why? Because you told him to create 1000 * 1000 * 1000 * 1000 * 1000 = 10**15 or 1000 trillion (!) integer numbers. That’s the curse of high dimensionality!
Anyways, here are examples of how to create NumPy arrays by using the functions ones() and zeros().
a = np.zeros((10, 10, 10, 10, 10)) print(a.shape) # (10, 10, 10, 10, 10) b = np.zeros((2,3)) print(b) # [[0. 0. 0.] # [0. 0. 0.]] c = np.ones((3, 2, 2)) print(c) # [[[1. 1.] # [1. 1.]] # # [[1. 1.] # [1. 1.]] # # [[1. 1.] # [1. 1.]]] print(c.dtype) # float64
You can see that the data types are implicitly converted to floats. Floating point numbers are the default numpy array data type (on my computer: the np.float64 type).
But what if you want to create a NumPy array of integer values?
You can specify the data type of the numpy array as a second argument to the ones() or zeros() functions. Here is an example:
import numpy as np a = np.zeros((2,3), dtype=np.int16) print(a) # [[0 0 0] # [0 0 0]] print(a.dtype) # int16
Finally, there is one way to create numpy arrays which is also very common: the numpy arange function. I have written a whole article about the arange function – check it out to dig deeper into array creation in NumPy!
If you prefer video, have a quick look at my video from this blog post:
💡 Here is a quick summary of np.arange(): The numpy function np.arange(start[, stop[, step]) creates a new NumPy array with evenly spaced numbers between start (inclusive) and stop (exclusive) with the given step size. For example, np.arange(1, 6, 2) creates the numpy array [1 3 5].
The following detailed example shows you how to do this:
import numpy as np a = np.arange(2, 10) print(a) # [2 3 4 5 6 7 8 9] b = np.arange(2, 10, 2) print(b) # [2 4 6 8] c = np.arange(2, 10, 2, dtype=np.float64) print(c) # [2. 4. 6. 8.]
Note that you can also specify the dtype argument as for any other array creation routine in numpy.
But keep in mind the following. If you want to create an evenly spaced sequence of float values in a specific interval, don’t use the numpy arange function.
The documentation discourages this because it’s improper handling of boundaries. Instead, the official numpy tutorial recommends using the numpy linspace() function instead.
💡 The np.linspace() function works like the np.arange() function. But there is one important difference: instead of defining the step size, you define the number of elements in the interval between the start and stop values.
Here is an example:
import numpy as np a = np.linspace(0.5, 9.5, 10) print(a) # [0.5 1.5 2.5 3.5 4.5 5.5 6.5 7.5 8.5 9.5] b = np.linspace(0.5, 9.5, 5) print(b) # [0.5 2.75 5. 7.25 9.5 ]
This is everything you need to know about array creation to get started with NumPy.
If you feel that you have mastered the array creation routines, go on to the next important topic in Python’s NumPy library.
How Do Indexing and Slicing Work in Python?
Indexing and slicing in NumPy are very similar to indexing and slicing in Python. If you have mastered slicing in Python, understanding slicing in NumPy is easy.
To this end, I have written the most comprehensive slicing ebook “Coffee Break Python Slicing“.

In the next paragraphs, you will get a short introduction into indexing in Python. After this, I will shortly explain slicing in Python. Having understood indexing and slicing in Python, you will then learn about indexing and slicing in numpy.
Let’s look at an example to explain indexing in Python. Suppose, we have a string ‘universe’. The indices are simply the positions of the characters of this string.
| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Character | u | n | i | v | e | r | s | e |
The first character has index 0, the second character has index 1, and the i-th character has index i-1.
Now, let’s dive into slicing in Python.
The idea of slicing is simple. You carve out a subsequence from a sequence by defining the start index and the end index. While indexing retrieves only a single character, slicing retrieves a whole substring within an index range.
For slicing, use the bracket notation with the start and end position identifiers. For example, word[i:j] returns the substring starting from index i (included) and ending in index j (excluded).
You can also skip the position identifier before or after the slicing colon. This indicates that the slice starts from the first or last position, respectively. For example, word[:i] + word[i:] returns the same string as word.
Here is an example.
x = 'universe' print(x[2:4])
The result is the string ‘iv’. We start from the character on position 2 (the third character) and end the slice at position 4 (excluded from the slice).
For the sake of completeness, let me shortly explain the advanced slicing notation [start:end:step]. The only difference to the previous notation is that you also specify the step size. For example, the expression 'python'[:5:2] returns every second character up to the fourth character, i.e., the string 'pto'. See the following example.
x = 'universe' print(x[2::2])
The result is the string ‘ies’. You start from the third character (included) and select every other character until you reach the end of the string.
Let’s dig a bit deeper into slicing to make sure that you are getting it by 100%.
I have searched Quora to find all the little problems new Python coders are facing with slicing. I will answer six common questions next.
1) How to Skip Slicing Indices (e.g. s[::2])?
The Python interpreter assumes certain default values for s[start:stop:step]. They are: start=0, stop=len(s), and step=1 (in the slice notation: s[::]==s[0:len(s):1]).
2) When to Use the Single Colon Notation (e.g. s[:]) and When Double Colon Notation (e.g. s[::2])?
A single colon (e.g. s[1:2]) allows for two arguments, the start and the end index. A double colon (e.g. s[1:2:2]) allows for three arguments, the start index, the end index, and the step size. If the step size is set to the default value 1, we can use the single colon notation for brevity.
3) What Does a Negative Step Size Mean (e.g. s[5:1:-1])?
This is an interesting feature in Python. A negative step size indicates that we are not slicing from left to right, but from right to left. Hence, the start index should be larger or equal than the end index (otherwise, the resulting sequence is empty).
4) What are the default indices when using a negative step size (e.g. s[::-1])?
In this case, the default indices are not start=0 and end=len(s) but the other way round: start=len(s)-1 and end=-1. Note that the start index is still included and the end index still excluded from the slice. Because of that, the default end index is -1 and not 0.
5) How Does List Slicing Work?
Slicing works the same for all sequence types. For lists, consider the following example:
l = [1, 2, 3, 4] print(l[2:]) # [3, 4]
Slicing of tuples works in a similar way.
6) Why is the Last Index Excluded from the Slice?
The last index is excluded because of two reasons. The first reason is language consistency, e.g. the range function also does not include the end index. The second reason is clarity – here’s an example of why it makes sense to exclude the end index from the slice.
customer_name = 'Hubert' k = 3 # maximal size of database entry x = 1 # offset db_name = customer_name[x:x+k]
Now suppose the end index would be included. In this case, the total length of the db_name substring would be k + 1 characters. This would be very counter-intuitive.
Now you are able to understand indexing and slicing in NumPy. If you still need some background, check out my article/video combination on the Finxter blog:
Related Article: Introduction to Slicing in Python
How Does Indexing and Slicing Work in NumPy?
In NumPy, you have to differentiate between one-dimensional arrays and multi-dimensional arrays because slicing works differently for both.
💡 One-dimensional NumPy arrays are similar to numerical lists in Python, so you can use slicing in NumPy as you used slicing for lists.
Here are a few examples that should be familiar to you from the last section of this tutorial. Go over them slowly. Try to explain to yourself why these particular slicing instances produce the respective results.
import numpy as np a = np.arange(0, 10) print(a) # [0 1 2 3 4 5 6 7 8 9] print(a[:]) # [0 1 2 3 4 5 6 7 8 9] print(a[1:]) # [1 2 3 4 5 6 7 8 9] print(a[1:3]) # [1 2] print(a[1:-1]) # [1 2 3 4 5 6 7 8] print(a[::2]) # [0 2 4 6 8] print(a[1::2]) # [1 3 5 7 9] print(a[::-1]) # [9 8 7 6 5 4 3 2 1 0] print(a[:1:-2]) # [9 7 5 3] print(a[-1:1:-2]) # [9 7 5 3]
I want to highlight the last two examples here. Have you really understood why a[-1:1:-2] is exactly the same as a[:1:-2]? If you have read the last section about Python’s slicing thoroughly, you may remember that the default start index for negative step sizes is -1.
But in contrast to regular slicing, NumPy is a bit more powerful. See the next example of how NumPy handles an assignment of a value to an extended slice.
import numpy as np l = list(range(10)) l[::2] = 999 # Throws error --> assign iterable to extended slice a = np.arange(10) a[::2] = 999 print(a) # [999 1 999 3 999 5 999 7 999 9]
Regular Python’s slicing method is not able to implement the user’s intention as NumPy. In both cases, it is clear that the user wants to assign 999 to every other element in the slice. NumPy has no problems implementing this goal.
Let’s move on to multi-dimensional slices.
? For multi-dimensional slices, you can use one-dimensional slicing for each axis separately. You define the slices for each axis, separated by a comma.
Here are a few examples. Take your time to thoroughly understand each of them.
import numpy as np a = np.arange(16) a = a.reshape((4,4)) print(a) # [ 0 1 2 3] # [ 4 5 6 7] # [ 8 9 10 11] # [12 13 14 15]] print(a[:, 1]) # Second column: # [ 1 5 9 13] print(a[1, :]) # Second row: # [4 5 6 7] print(a[1, ::2]) # Second row, every other element # [4 6] print(a[:, :-1]) # All columns except last one # [[ 0 1 2] # [ 4 5 6] # [ 8 9 10] # [12 13 14]] print(a[:-1]) # Same as a[:-1, :] # [[ 0 1 2 3] # [ 4 5 6 7] # [ 8 9 10 11]]
As you can see in the above examples, slicing multi-dimensional numpy arrays is easy – if you know numpy arrays and how to slice them. The most important information to remember is that you can slice each axis separately. If you don’t specify the slice notation for a specific axis, the interpreter applies the default slicing (i.e., the colon :).
I will skip a detailed explanation of the NumPy dot notation — just know that you can “fill in” the remaining default slicing colons by using three dots. Here is an example:
import numpy as np a = np.arange(3**3) a = a.reshape((3, 3, 3)) print(a) ##[[[ 0 1 2] ## [ 3 4 5] ## [ 6 7 8]] ## ## [[ 9 10 11] ## [12 13 14] ## [15 16 17]] ## ## [[18 19 20] ## [21 22 23] ## [24 25 26]]] print(a[0, ..., 0]) # Select the first element of axis 0 # and the first element of axis 2. Keep the rest. # [0 3 6] # Equal to a[0, :, 0]
Having mentioned this detail, I will introduce a very important and beautiful feature for NumPy indexing. This is critical for your success in NumPy so stay with me for a moment.
Instead of defining the slice to carve out a sequence of elements from an axis, you can select an arbitrary combination of elements from the numpy array.
How? Simply specify a Boolean array with exactly the same shape. If the Boolean value at position (i,j) is True, the element will be selected, otherwise not. As simple as that.
Here is an example.
import numpy as np
a = np.arange(9)
a = a.reshape((3,3))
print(a)
# [[0 1 2]
# [3 4 5]
# [6 7 8]]
b = np.array(
[[ True, False, False],
[ False, True, False],
[ False, False, True]])
print(a[b])
# Flattened array with selected values from a
# [0 4 8]The matrix b with shape (3,3) is a parameter of a’s indexing scheme. Beautiful, isn’t it?
Let me highlight an important detail. In the example, you select an arbitrary number of elements from different axes.
How is the Python interpreter supposed to decide about the final shape?
For example, you may select four rows for column 0 but only 2 rows for column 1 – what’s the shape here? There is only one solution: the result of this operation has to be a one-dimensional numpy array.
If you need to have a different shape, feel free to use the np.reshape() operation to bring your NumPy array back into your preferred format.
Where to Go From Here?
Congratulations, you made it through this massive NumPy tutorial. This is one of the largest NumPy tutorials on the web. Mastering Python’s NumPy library is a critical step on your path to becoming a better Python coder and acquiring your data science and machine learning skills. Your invested time working through this tutorial will amortize a hundredfold during your career.
Join our free email academy here: