
The Pandas DataFrame has several Re-indexing/Selection/Label Manipulations methods. When applied to a DataFrame, these methods evaluate, modify the elements and return the results.
Preparation
Before any data manipulation can occur, one (1) new library will require installation:
- The Pandas library enables access to/from a DataFrame.
To install this library, navigate to an IDE terminal. At the command prompt ($), execute the code below. For the terminal used in this example, the command prompt is a dollar sign ($). Your terminal prompt may be different.
$ pip install pandas
Hit the <Enter> key on the keyboard to start the installation process.
If the installations were successful, a message displays in the terminal indicating the same.
Feel free to view the PyCharm installation guide for the required library.
Add the following code to the top of each code snippet. This snippet will allow the code in this article to run error-free.
import pandas as pd
💡 Note: To follow along with the examples below, click here to download the finxters.csv file of auto-generated dummy user data. Move this file to the current working directory.
DataFrame equals()
The equals() method compares two (2) DataFrames/Series against each other to determine if they have an identical shape and elements. If identical return True, otherwise return False.
The syntax for this method is as follows:
DataFrame.equals(other)
| Parameter | Description |
|---|---|
other | A DataFrame or Series to compare. |
For this example, we have two (2) DataFrames containing grades for three (3) students.
df_scores1 = pd.DataFrame({'Micah': [91, 58, 73],
'Bob': [53, 87, 46],
'Chloe': [60, 54, 61]})
df_scores2 = pd.DataFrame({'Micah': [91, 58, 73],
'Bob': [53, 87, 46],
'Chloe': [60, 54, 61]})
result = df_scores1.equals(df_scores2)
print(result)
print(df_scores1.shape)
print(df_scores2.shape)- Line [1-2] creates two (2) DataFrames.
- Line [3] compares
df_scores1againstdf_scores2testing the shape and elements. The outcome saves toresult(True/False). - Line [4] outputs the result to the terminal.
- Line [5-6] confirms the shape of the DataFrames is equal by outputting the results to the terminal.
Output
True (3, 3) (3, 3)
DataFrame filter()
The filter() method returns a subset of a DataFrame/Series rows/columns based on index label(s). This method does not filter a DataFrame/Series on the contents. The filter applies to the specific label(s) of the selected index. The return value is a subset of the callable.
The syntax for this method is as follows:
DataFrame.filter(items=None, like=None, regex=None, axis=None)
| Parameter | Description |
|---|---|
items | A filter list of columns to include in the result. |
like | A filter string of columns (ex: like='FID') to include in the result. |
regex | A regex string to filter columns (ex: regex='e$') to include in the result. |
axis | If zero (0) or index is selected, apply to each column. Default 0. If one (1) apply to each row.. |
For this method, various scenarios below highlight its capabilities.
This example uses the items parameter to filter the DataFrame and return the result.
Code – Example 1
df_fxs = pd.read_csv('finxters.csv')
result = df_fxs.filter(items=['Username', 'Rank'])
print(result.head())- Line [1] reads in the comma-separated CSV file and saves it to
df_fxs. - Line [2] filters
df_fxsto include only the columns matching theitemlabels (Username and Rank). These columns (and associated values) save toresult. - Line [3] outputs the first five (5) rows (
head()) to the terminal.
Output
| Username | Rank | |
| 0 | wildone92 | Authority |
| 1 | AmyP | Beginner |
| 2 | 1998_pete | Basic Knowledge |
| 3 | TheCoder | Experienced Learner |
| 4 | AliceM | Authority |
This example uses the like parameter to filter the DataFrame and return the result.
Code – Example 2
df_fxs = pd.read_csv('finxters.csv')
result = df_fxs.filter(like='FID', axis=1)
print(result.head())- Line [1] reads in the comma-separated CSV file and saves it to
df_fxs. - Line [2] filters
df_fxsto include only the columns matching thelikelabel ('FID'). This column (and associated values) save toresult. - Line [3] outputs the first five (5) rows (
head()) to the terminal.
Output
| FID | |
| 0 | 30022145 |
| 1 | 30022192 |
| 2 | 30022331 |
| 3 | 30022345 |
| 4 | 30022359 |
This example uses the regex parameter to filter the DataFrame and return the result.
Code – Example 3
df_fxs = pd.read_csv('finxters.csv')
result = df_fxs.filter(regex='e$', axis=1)
print(result.head())- Line [1] reads in the comma-separated CSV file and saves it to
df_fxs. - Line [2] filters
df_fxsto include only the columns matching theregexlabel (First_Name, Last_Name and Username). These columns (and associated values) save toresult. - Line [3] outputs the first five (5) rows (
head()) to the terminal.
Output
| First_Name | Last_Name | Username | |
| 0 | Steve | Hamilton | wildone92 |
| 1 | Amy | Pullister | AmyP |
| 2 | Peter | Dunn | 1998_pete |
| 3 | Marcus | Williams | TheCoder |
| 4 | Alice | Miller | AliceM |
Note: Each column name in the output ends with the letter e.
DataFrame first()
The first() method retrieves and returns the first set number of rows (periods) based on the value entered. The index must be a date value to return the appropriate results.
The syntax for this method is as follows:
DataFrame.first(offset)
| Parameter | Description |
|---|---|
offset | This parameter is the date period of the data to display (ex: 1M, 2D). |
For this example, the blood pressure for three (3) patients over a two (2) month period is retrieved.
r = pd.date_range('2021-01-01', periods=3, freq='1M')
df = pd.DataFrame({'Patient-1': [123, 120, 144],
'Patient-2': [129, 125, 90],
'Patient-3': [101, 95, 124]},index=r)
result = df.first('1M')
print(result)- Line [1] sets up the following:
- The date range start date (
'2021-01-01'). - The number of periods (
3). - The frequency (
'1M'). This statement equates to 1 Month.
- The date range start date (
- Line [2] creates a DataFrame containing:
- Three (3) patient names containing three (3) elements of data for each patient.
- Line [3] saves the first month period to
result. - Line [4] outputs the result to the terminal.
Output
| Patient-1 | Patient-2 | Patient-3 | |
| 2022-01-31 | 123 | 129 | 101 |
| 2022-02-28 | 120 | 125 | 95 |
💡 Note: The date range for the selected frequency references the last day of the month.
DataFrame last()
The last() method retrieves and returns the last set number of rows (periods) based on the value entered. The index must be a date value for this method to return the expected results.
The syntax for this method is as follows:
DataFrame.last(offset)
| Parameter | Description |
|---|---|
offset | This parameter is the date period of the data to display (ex: 1M, 2D). |
For this example, the blood pressure for three (3) patients over a two (2) month period is retrieved.
r = pd.date_range('2021-01-01', periods=3, freq='1M')
df = pd.DataFrame({'Patient-1': [123, 120, 144],
'Patient-2': [129, 125, 90],
'Patient-3': [101, 95, 124]},index=r)
result = df.last('1M')
print(result)- Line [1] sets up the following:
- The
daterange start date ('2021-01-01'). - The number of periods (
3). - The frequency (
'1M'). This statement equates to 1 Month.
- The
- Line [2] creates a DataFrame containing:
- Three (3) patient names containing three (3) elements of data for each patient.
- Line [3] saves the output to
result. - Line [4] outputs the result to the terminal.
Output
| Patient-1 | Patient-2 | Patient-3 | |
| 2022-03-31 | 144 | 90 | 125 |
💡 Note: The date range for the selected frequency references the last day of the month.
DataFrame head() and tail()
These methods display n numbers of records (top or bottom). These methods are useful when you are accessing large amounts of data.
If no parameter is entered, by default, five (5) rows display.
- The
head()method returns the top five (5) rows of the DataFrame. - The
tail()method returns the bottom five (5) rows of the DataFrame
If a parameter is entered in one of the above methods, n number of rows (top/bottom) will display.
As you will note, the head() method was accessed many times during this article. Both methods are must-haves in your knowledge base.
The syntax for these methods is as follows:
DataFrame.head(n=5) DataFrame.tail(n=5)
| Parameter | Description |
|---|---|
n | An integer value indicating the number of rows to display. By default, five (5) rows display. |
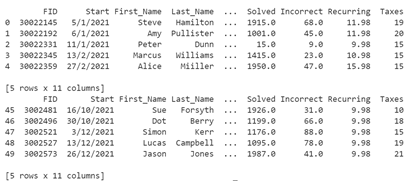
For this example, the first five (5) records from the DataFrame and the last five (5) records (tail) from the same DataFrame display.
df_fxs = pd.read_csv('finxters.csv')
print(df_fxs.head())
print(df_fxs.tail())Output
Further Learning Resources
This is Part 8 of the DataFrame method series.
Also, have a look at the Pandas DataFrame methods cheat sheet!