

Don’t Be Mean, Be Median.
This article shows you how to calculate the average of a given list of numerical inputs in Python.
In case you’ve attended your last statistics course a few years ago, let’s quickly recap the definition of the average: sum over all values and divide them by the number of values.
So, how to calculate the average of a given list in Python?
Python 3.x doesn’t have a built-in method to calculate the average. Instead, simply divide the sum of list values through the number of list elements using the two built-in functions sum() and len(). You calculate the average of a given list in Python as sum(list)/len(list). The return value is of type float.
Here’s a short example that calculates the average income of income data $80000, $90000, and $100000:
income = [80000, 90000, 100000] average = sum(income) / len(income) print(average) # 90000.0
You can see that the return value is of type float, even though the list data is of type integer. The reason is that the default division operator in Python performs floating point arithmetic, even if you divide two integers.
Puzzle: Try to modify the elements in the list income so that the average is 80000.0 instead of 90000.0 in our interactive shell:
If you cannot see the interactive shell, here’s the non-interactive version:
# Define the list data income = [80000, 90000, 100000] # Calculate the average as the sum divided # by the length of the list (float division) average = sum(income) / len(income) # Print the result to the shell print(average) # Puzzle: modify the income list so that # the result is 80000.0
This is the absolute minimum you need to know about calculating basic statistics such as the average in Python. But there’s far more to it and studying the other ways and alternatives will actually make you a better coder. So, let’s dive into some related questions and topics you may want to learn!
Here’s your free PDF cheat sheet showing you all Python list methods on one simple page. Click the image to download the high-resolution PDF file, print it, and post it to your office wall:
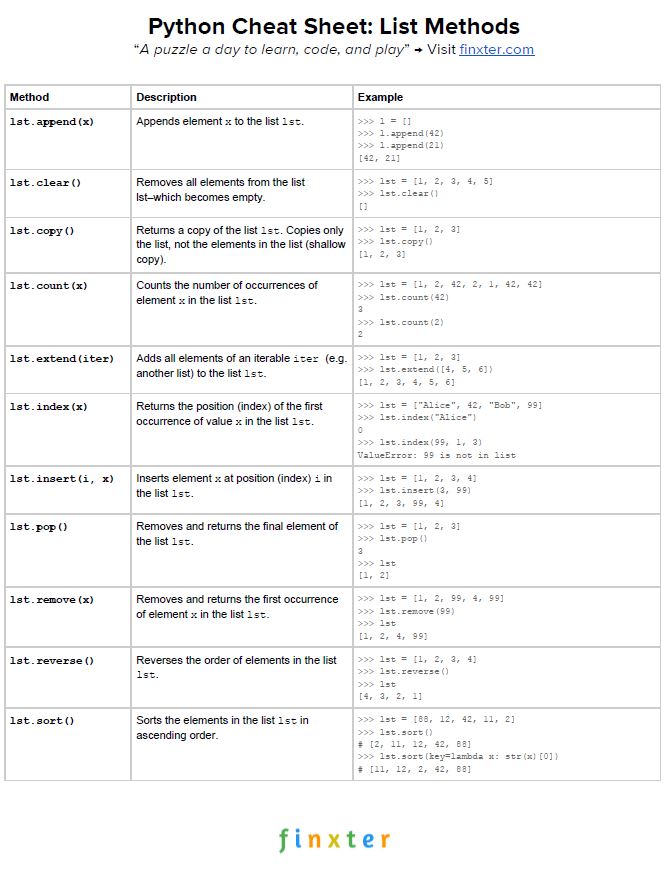
Python List Average Median
What’s the median of a Python list? Formally, the median is “the value separating the higher half from the lower half of a data sample” (wiki).

How to calculate the median of a Python list?
- Sort the list of elements using the
sorted()built-in function in Python. - Calculate the index of the middle element (see graphic) by dividing the length of the list by 2 using integer division.
- Return the middle element.
Together, you can simply get the median by executing the expression median = sorted(income)[len(income)//2].
Here’s the concrete code example:
income = [80000, 90000, 100000, 88000] average = sum(income) / len(income) median = sorted(income)[len(income)//2] print(average) # 89500.0 print(median) # 90000.0
Related tutorials:
Python List Average Mean
The mean value is exactly the same as the average value: sum up all values in your sequence and divide by the length of the sequence. You can use either the calculation sum(list) / len(list) or you can import the statistics module and call mean(list).
Here are both examples:
lst = [1, 4, 2, 3] # method 1 average = sum(lst) / len(lst) print(average) # 2.5 # method 2 import statistics print(statistics.mean(lst)) # 2.5
Both methods are equivalent. The statistics module has some more interesting variations of the mean() method (source):
| mean() | Arithmetic mean (“average”) of data. |
| median() | Median (middle value) of data. |
| median_low() | Low median of data. |
| median_high() | High median of data. |
| median_grouped() | Median, or 50th percentile, of grouped data. |
| mode() | Mode (most common value) of discrete data. |
These are especially interesting if you have two median values and you want to decide which one to take.
Python List Average Standard Deviation
Standard deviation is defined as the deviation of the data values from the average (wiki). It’s used to measure the dispersion of a data set. You can calculate the standard deviation of the values in the list by using the statistics module:
import statistics as s lst = [1, 0, 4, 3] print(s.stdev(lst)) # 1.8257418583505538
Python List Average Min Max
In contrast to the average, there are Python built-in functions that calculate the minimum and maximum of a given list. The min(list) method calculates the minimum value and the max(list) method calculates the maximum value in a list.
Here’s an example of the minimum, maximum and average computations on a Python list:
import statistics as s lst = [1, 1, 2, 0] average = sum(lst) / len(lst) minimum = min(lst) maximum = max(lst) print(average) # 1.0 print(minimum) # 0 print(maximum) # 2
Python List Average Sum
How to calculate the average using the sum() built-in Python method? Simple, divide the result of the sum(list) function call by the number of elements in the list. This normalizes the result and calculates the average of all elements in a list.
Again, the following example shows how to do this:
import statistics as s lst = [1, 1, 2, 0] average = sum(lst) / len(lst) print(average) # 1.0
Python List Average NumPy
Python’s package for data science computation NumPy also has great statistics functionality. You can calculate all basic statistics functions such as average, median, variance, and standard deviation on NumPy arrays. Simply import the NumPy library and use the np.average(a) method to calculate the average value of NumPy array a.
Here’s the code:
import numpy as np a = np.array([1, 2, 3]) print(np.average(a)) # 2.0
Python Average List of (NumPy) Arrays
NumPy’s average function computes the average of all numerical values in a NumPy array. When used without parameters, it simply calculates the numerical average of all values in the array, no matter the array’s dimensionality. For example, the expression np.average([[1,2],[2,3]]) results in the average value (1+2+2+3)/4 = 2.0.
However, what if you want to calculate the weighted average of a NumPy array? In other words, you want to overweight some array values and underweight others.
You can easily accomplish this with NumPy’s average function by passing the weights argument to the NumPy average function.
import numpy as np a = [-1, 1, 2, 2] print(np.average(a)) # 1.0 print(np.average(a, weights = [1, 1, 1, 5])) # 1.5
In the first example, we simply averaged over all array values: (-1+1+2+2)/4 = 1.0. However, in the second example, we overweight the last array element 2—it now carries five times the weight of the other elements resulting in the following computation: (-1+1+2+(2+2+2+2+2))/8 = 1.5.
Let’s explore the different parameters we can pass to np.average(...).
- The NumPy array which can be multi-dimensional.
- (Optional) The axis along which you want to average. If you don’t specify the argument, the averaging is done over the whole array.
- (Optional) The weights of each column of the specified axis. If you don’t specify the argument, the weights are assumed to be homogeneous.
- (Optional) The return value of the function. Only if you set this to True, you will get a tuple (average, weights_sum) as a result. This may help you to normalize the output. In most cases, you can skip this argument.
Here is an example how to average along the columns of a 2D NumPy array with specified weights for both rows.
[python]
import numpy as np
# daily stock prices
# [morning, midday, evening]
solar_x = np.array(
[[2, 3, 4], # today
[2, 2, 5]]) # yesterday
# midday – weighted average
print(np.average(solar_x, axis=0, weights=[3/4, 1/4])[1])
[/python]
What is the output of this puzzle?
*Beginner Level* (solution below)
You can also solve this puzzle in our puzzle-based learning app (100% FREE): Test your skills now!
Related article:
Python Average List of Dictionaries
Problem: Given is a list of dictionaries. Your goal is to calculate the average of the values associated to a specific key from all dictionaries.
Example: Consider the following example where you want to get the average value of a list of database entries (e.g., each stored as a dictionary) stored under the key 'age'.
db = [{'username': 'Alice', 'joined': 2020, 'age': 23},
{'username': 'Bob', 'joined': 2018, 'age': 19},
{'username': 'Alice', 'joined': 2020, 'age': 31}]
average = # ... Averaging Magic Here ...
print(average)The output should look like this where the average is determined using the ages (23+19+31)/3 = 24.333.
Solution: Solution: You use the feature of generator expression in Python to dynamically create a list of age values. Then, you sum them up and divide them by the number of age values. The result is the average of all age values in the dictionary.
db = [{'username': 'Alice', 'joined': 2020, 'age': 23},
{'username': 'Bob', 'joined': 2018, 'age': 19},
{'username': 'Alice', 'joined': 2020, 'age': 31}]
average = sum(d['age'] for d in db) / len(db)
print(average)
# 24.333333333333332Let’s move on to the next question: how to calculate the average of a list of floats?
Python Average List of Floats
Averaging a list of floats is as simple as averaging a list of integers. Just sum them up and divide them by the number of float values. Here’s the code:
lst = [1.0, 2.5, 3.0, 1.5] average = sum(lst) / len(lst) print(average) # 2.0
Python Average List of Tuples
Problem: How to average all values if the values are stored in a list of tuples?
Example: You have the list of tuples [(1, 2), (2, 2), (1, 1)] and you want the average value (1+2+2+2+1+1)/6 = 1.5.
Solution: There are three solution ideas:
- Unpack the tuple values into a list and calculate the average of this list.
- Use only list comprehension with nested for loop.
- Use a simple nested for loop.
Next, I’ll give all three examples in a single code snippet:
lst = [(1, 2), (2, 2), (1, 1)]
# 1. Unpacking
lst_2 = [*lst[0], *lst[1], *lst[2]]
print(sum(lst_2) / len(lst_2))
# 1.5
# 2. List comprehension
lst_3 = [x for t in lst for x in t]
print(sum(lst_3) / len(lst_3))
# 1.5
# 3. Nested for loop
lst_4 = []
for t in lst:
for x in t:
lst_4.append(x)
print(sum(lst_4) / len(lst_4))
# 1.5Unpacking: The asterisk operator in front of an iterable “unpacks” all values in the iterable into the outer context. You can use it only in a container data structure that’s able to catch the unpacked values.
List comprehension is a compact way of creating lists. The simple formula is [ expression + context ].
- Expression: What to do with each list element?
- Context: What list elements to select? It consists of an arbitrary number of for and if statements.
The example [x for x in range(3)] creates the list [0, 1, 2].
Python Average Nested List
Problem: How to calculate the average of a nested list?
Example: Given a nested list [[1, 2, 3], [4, 5, 6]]. You want to calculate the average (1+2+3+4+5+6)/6=3.5. How do you do that?
Solution: Again, there are three solution ideas:
- Unpack the tuple values into a list and calculate the average of this list.
- Use only list comprehension with nested for loop.
- Use a simple nested for loop.
Next, I’ll give all three examples in a single code snippet:
lst = [[1, 2, 3], [4, 5, 6]]
# 1. Unpacking
lst_2 = [*lst[0], *lst[1]]
print(sum(lst_2) / len(lst_2))
# 3.5
# 2. List comprehension
lst_3 = [x for t in lst for x in t]
print(sum(lst_3) / len(lst_3))
# 3.5
# 3. Nested for loop
lst_4 = []
for t in lst:
for x in t:
lst_4.append(x)
print(sum(lst_4) / len(lst_4))
# 3.5
Unpacking: The asterisk operator in front of an iterable “unpacks” all values in the iterable into the outer context. You can use it only in a container data structure that’s able to catch the unpacked values.
List comprehension is a compact way of creating lists. The simple formula is [ expression + context ].
- Expression: What to do with each list element?
- Context: What list elements to select? It consists of an arbitrary number of for and if statements.
The example [x for x in range(3)] creates the list [0, 1, 2].
Where to Go From Here
Python 3.x doesn’t have a built-in method to calculate the average. Instead, simply divide the sum of list values through the number of list elements using the two built-in functions sum() and len(). You calculate the average of a given list in Python as sum(list)/len(list). The return value is of type float.
If you keep struggling with those basic Python commands and you feel stuck in your learning progress, I’ve got something for you: Python One-Liners (Amazon Link).
In the book, I’ll give you a thorough overview of critical computer science topics such as machine learning, regular expression, data science, NumPy, and Python basics—all in a single line of Python code!
OFFICIAL BOOK DESCRIPTION: Python One-Liners will show readers how to perform useful tasks with one line of Python code. Following a brief Python refresher, the book covers essential advanced topics like slicing, list comprehension, broadcasting, lambda functions, algorithms, regular expressions, neural networks, logistic regression and more. Each of the 50 book sections introduces a problem to solve, walks the reader through the skills necessary to solve that problem, then provides a concise one-liner Python solution with a detailed explanation.