
This tutorial shows you everything you need to know to help you master the essential count() method of the most fundamental container data type in the Python programming language.
Definition and Usage:
The list.count(x) method counts the number of occurrences of the element x in the list.
Here’s a short example:
>>> lst = [1, 2, 42, 2, 1, 42, 42] >>> lst.count(42) 3 >>> lst.count(2) 2
In the first line of the example, you create the list lst. You then count the number of times the integer values 42 and 2 appear in the list.
Code Puzzle — Try It Yourself:
Now you know the basics. Let’s deepen your understanding with a short code puzzle—can you solve it?
# Create list of strings
customers = ["Alice", "Bob", "Ann", "Alice", "Charles"]
# Count each customer in list and store in dictionary
d = {k:customers.count(k) for k in customers}
# Print everything
print(d)
# What's the output of this code puzzle?You can also solve this puzzle and track your Python skills on our interactive Finxter app.
Syntax: You can call this method on each list object in Python (Python versions 2.x and 3.x). Here’s the syntax:
list.count(value)
Arguments:
| Argument | Description |
|---|---|
value | Counts the number of occurrences of value in list. A value appears in the list if the == operator returns True. |
Return value: The method list.count(value) returns an integer value set to the number of times the argument value appears in the list. If the value does not appear in the list, the return value is 0.
Related article:
Here’s your free PDF cheat sheet showing you all Python list methods on one simple page. Click the image to download the high-resolution PDF file, print it, and post it to your office wall:
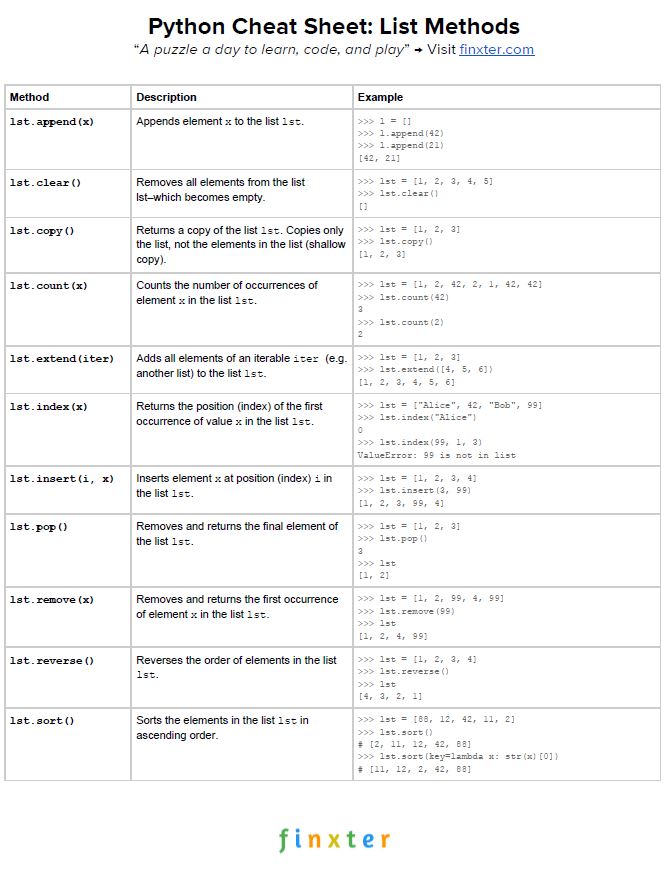
Python List Count Values
You’ve already seen how to count values in a given list. Here’s the minimal example to count how often value x=42 appears in a list of elements:
>>> [42, 42, 1, 2, 3, 42, 1, 3].count(42) 3
The value 42 appears three times in the list.
It’s important that you understand how the count method works. Say, you’re looking for the value in a given list. If list element x == value the counter is increased by one. The method does not count the number of times an element is referenced in memory!
Here’s an example:
>>> lst = [[1,1], [1,1], (1,1), 42, 1] >>> lst.count([1,1]) 2
The top-level list refers to two independent list objects [1, 1] in memory. Still, if you count the number of occurrences of a third list [1, 1], the method correctly determines that it appears two times. That’s because two list elements are equal to the list [1, 1].
Note that values x and y are considered equal if x==y. You can see this for integer lists in the following example:
>>> lst_1 = [1, 1] >>> lst_2 = [1, 1] >>> lst_1 == lst_2 True
To summarize, the list.count(value) method counts the number of times a list element is equal to value (using the == comparison). Here’s a reference implementation:
def count(lst, value):
''' Returns the number of times
a list element is equal to value'''
count = 0
for element in lst:
count += element == value
return count
lst = [1, 1, 1, 1, 2]
print(lst.count(1))
# 4
print(lst.count(2))
# 1
print(lst.count(3))
# 0
(Note that this is not the real cPython implementation. It’s just a semantically equivalent implementation of the list.count(value) method for educational purposes.)
Related articles:
Python List Count Runtime Complexity
The time complexity of the count(value) method is O(n) for a list with n elements. The standard Python implementation cPython “touches” all elements in the original list to check if they are equal to the value.
Again, have a look at the reference implementation where you can see these comparison operations element == value in the code:
def count(lst, value):
count = 0
for element in lst:
count += element == value
return countThus, the time complexity is linear in the number of list elements.
You can see a plot of the time complexity of the count() method for growing list size here:

The figure shows how the elapsed time of counting a dummy element -99 in lists with growing number of elements grows linear to the number of elements.
If you’re interested in the code I used to generate this plot with Matplotlib, this is it:
import matplotlib.pyplot as plt
import time
y = []
for i in [100000 * j for j in range(10,100)]:
lst = list(range(i))
t0 = time.time()
x = lst.count(-99)
t1 = time.time()
y.append(t1-t0)
plt.plot(y)
plt.xlabel("List elements (10**5)")
plt.ylabel("Time (sec)")
plt.show()
Python List Count Duplicates
How can you count the number of duplicates in a given list?
Problem: Let’s consider an element a duplicate if it appears at least two times in the list. For example, the list [1, 1, 1, 2, 2, 3] has two duplicates 1 and 2.
Solution: You create an empty set duplicates. Then you iterate over the original list and add each element to the set that has a count value of at least 2.
Here’s the code:
def find_dups(lst):
dups = set()
for el in lst:
if lst.count(el)>1:
dups.add(el)
return dups
print(find_dups([1, 1, 1, 2, 2, 3]))
# {1, 2}
print(find_dups(["Alice", "Bob", "Alice"]))
# {'Alice'}
print(find_dups([1, 2, 3]))
# set()Note that this algorithm has quadratic time complexity because for each element in the list, you need to count the number of times it appears in the list—each of those count operations has linear time complexity.
Related article:
Python List Count Unique Values and Strings
How can you count the number of unique values (or strings) in a given list?
Problem: A value is considered unique if it appears only once in the list.
Solution: You count each element in the list and take only those with list.count(element) == 1.
Here’s the code:
def find_uniques(lst):
uniques = set()
for el in lst:
if lst.count(el) == 1:
uniques.add(el)
return uniques
print(find_uniques([1, 1, 2, 3, 3]))
# {2}
print(find_uniques(["Alice", "Bob", "Alice"]))
# {'Bob'}This algorithm has quadratic time complexity because for each element in the list, you need to count the number of times it appears in the list—each of those count operations has linear time complexity.
Python List Count All Elements (Count to Dict)
How can you count all elements in a list and store the result in a dictionary?
Problem: Given is a list. You want to count each element in the list. Then, you want to store the result in a dictionary mapping the elements to their frequencies of appearance (counts). For example, the list [1, 1, 2, 2, 3] should lead to the dictionary {1:2, 2:2, 3:1}.
Solution: You solve this problem using dictionary comprehension. The key is the list element and the value is the frequency of this element in the list. You use the count() method to do this.
Here’s the code:
def count_to_dict(lst):
return {k:lst.count(k) for k in lst}
print(count_to_dict(["Alice", "Bob", "Ann", "Alice", "Charles"]))
# {'Alice': 2, 'Bob': 1, 'Ann': 1, 'Charles': 1}
print(count_to_dict([1, 1, 1, 2, 2, 3]))
# {1: 3, 2: 2, 3: 1}This algorithm has quadratic time complexity because for each element in the list, you need to count the number of times it appears in the list—each of those count operations has linear time complexity.
Related article:
Python List Count With Condition
How can you count elements under a certain condition in Python? For example, what if you want to count all even values in a list? Or all prime numbers? Or all strings that start with a certain character? There are multiple ways to accomplish this, let’s discuss them one by one.
Say, you have a condition for each element x. Let’s make it a function with the name condition(x). You can define any condition you want—just put it in your function. For example this condition returns True for all elements that are greater than the integer 10:
def condition(x):
return x > 10
print(condition(10))
# False
print(condition(2))
# False
print(condition(11))
# True
But you can also define more complicated conditions such as checking if they are prime numbers.
Python List Count If
How can you count the elements of the list IF the condition is met?
The answer is to use a simple generator expression sum(condition(x) for x in lst):
>>> def condition(x): return x>10 >>> lst = [10, 11, 42, 1, 2, 3] >>> sum(condition(x) for x in lst) 2
The result indicates that there are two elements that are larger than 10. You used a generator expression that returns an iterator of Booleans. Note that the Boolean True is represented by the integer value 1 and the Boolean False is represented by the integer value 0. That’s why you can simply calculate the sum over all Booleans to obtain the number of elements for which the condition holds.
Python List Count Greater / Smaller Than
If you want to determine the number of elements that are greater than or smaller than a specified value, just modify the condition in this example:
>>> def condition(x): return x>10 >>> lst = [10, 11, 42, 1, 2, 3] >>> sum(condition(x) for x in lst) 2
For example, to find the number of elements smaller than 5, use the condition x<5 in the generator expression:
>>> lst = [10, 11, 42, 1, 2, 3] >>> sum(x<5 for x in lst) 3
Python List Count Zero / Non-Zero
To count the number of zeros in a given list, use the list.count(0) method call.
To count the number of non-zeros in a given list, you should use conditional counting as discussed before:
def condition(x):
return x!=0
lst = [10, 11, 42, 1, 2, 0, 0, 0]
print(sum(condition(x) for x in lst))
# 5
Python List Count Lambda + Map
An alternative is to use a combination of the map and the lambda function.
Related articles:
- [Full Tutorial] Map Function: manipulates each element in an iterable.
- [Full Tutorial] Lambda Function: creates an anonymous function.
Here’s the code:
>>> sum(map(lambda x: x%2==0, [1, 2, 3, 4, 5])) 2
You count the number of even integers in the list.
- The lambda function returns a truth value for a given element
x. - The map function transforms each list element into a Boolean value (1 or 0).
- The sum function sums up the “1”s.
The result is the number of elements for which the condition evaluates to True.
Python List Count Regex / Count Matches
Given a list of strings. How can you check how many list elements match a certain regex pattern? (If you need a refresher on Python regular expressions, check out my ultimate guide on this blog – it’s really ultimate!)
- List
lstof string elements - Pattern
pto be matched against the strings in the list.
Solution: Use the concept of generator expressions with the ternary operator.
Related articles:
Here’s the code:
>>> import re >>> p = 'a...e' >>> lst = ['annie', 'alice', 'apex'] >>> sum(1 if re.match(p, x) else 0 for x in lst) 2
Python List Count Wildcard
Do you want to count all string occurrences of a given prefix (e.g. prefix "Sus" for strings "Susie", "Susy", "Susi")?
Solution: Again you can use the concept of generator expressions with the ternary operator.
Related articles:
Here’s the code for this one using the wildcard operator in a pattern to count all occurrences of this pattern in the list.
>>> import re >>> lst = ['Susi', 'Ann', 'Susanne', 'Susy'] >>> pattern = 'Sus.*' >>> frequency = sum(1 if re.match(pattern, x) else 0 for x in lst) >>> print(frequency) 3
The generator expression produces a bunch of 1s and 0s—the former if the list element starts with prefix 'Sus' and the latter if it doesn’t. By summing over all elements, you get the number of matches of the wildcard operator.
Python List Count Not Working
The list.count(value) method is very hard to break. Look what I tried to get an error:
>>> lst = [1, 1, 1, 2, 2, 3]
>>> lst.count(1)
3
>>> lst.count(2, 2)
Traceback (most recent call last):
File "<pyshell#19>", line 1, in <module>
lst.count(2, 2)
TypeError: count() takes exactly one argument (2 given)
>>> lst.count(4)
0
>>> lst.count("1")
0
>>> count(lst)
Traceback (most recent call last):
File "<pyshell#22>", line 1, in <module>
count(lst)
NameError: name 'count' is not defined
>>> You have to try really hard to break it. Just consider these tips:
- The
list.count(value)method takes exactly one argument: the value you want to count. If you define more or less arguments, there will be an error. - The
list.count(value)method is just that: a method of a list object. You need to call it on a list object. If you try to call it on another object, it will probably fail. If you try to use it just like that (without the list prefix, i.e.,count(value)), it will also fail. - The
list.count(value)will return 0 if you put in any object as an argument that does not evaluate toTruewhen compared to the list elements using the==comparison operator. So make sure that the object you want to count really evaluates toTrueif you compare it against some list elements. You may assume this but it could easily fail to do so.
Python List Reference Count
The Python garbage collector keeps track of the number of times each object in memory is referenced. You call this “reference counting”. All objects that have reference count of zero cannot be reached by your code and, thus, can be safely removed by the garbage collector.
It’s unrelated to Python lists with the one exception: each list element increases the reference count by one because a list really is an array of pointers to the list objects in memory in the cPython implementation.
Python List Count Tuples
How can you count the number of times a given tuple appears in a list?
Simply use the tuple as the input argument value for the list.count(value) method. Here’s an example:
>>> lst = [(1, 2), (1, 1), 99, "Alice", True, (1, 1)] >>> lst.count((1, 1)) 2
How can you count the number of tuples in a given list?
Use the type(x) method to check the type of a given variable x. Then compare the result with your desired data type (e.g. tuple).
Here’s an example:
>>> sum(type(x)==tuple for x in lst) 3
Related articles:
Python List Count and Sort
Given: list lst.
Problem: You want to count the number of occurrences of all values in the list and sort them by their frequency.
Example: for list elements [1, 1, 1, 1, 0, 0, 3, 1, 1, 3, 3, 3] you want to obtain their frequencies in a sorted manner:
6 times --> element 1 4 times --> element 3 2 times --> element 0
Solution: Use the collections.Counter(lst).most_common() method that does exactly that. You can find the documentation here.
import collections lst = [3, 2, 1, 1, 1, 2, 2, 3] print(collections.Counter(lst).most_common())
Generates output:
[(2, 3), (1, 3), (3, 2)]
Python List Count Slow
Do you want to improve performance of the list.count(value) method? It’s not easy because the runtime complexity is O(n) with n list elements.
There’s not much you can do about it. Of course, if you need to count the same element multiple times, you can use a cache dictionary to store its result. But this works only if the list has not changed.
You can also sort the list once which takes O(n log n) for n list elements. After that, you can call the implement a count method based on binary search with O(log n) runtime complexity. But if you need to count only a single element, this is not effective.
Interestingly, counting all elements in a list also has O(n) runtime complexity. Why? Because you’ll go over each element and add it to a dictionary if it doesn’t exist already (mapping the element to its counter value, initially 1). If it exists, you simply increment the counter by one.
In this excellent benchmark, you can find the performance of different counting methods. The Counter class seems to have best performance.
Python List Count vs Len
What’s the difference?
- The
list.count(x)method counts the number of occurrences of the elementxin thelist. - The
len(list)method returns the total number of elements in the list.
Here’s a minimal example:
>>> lst = [1, 2, 2, 2, 2] >>> lst.count(2) 4 >>> len(lst) 5
Python List count() Thread Safe
Do you have multiple threads that access your list at the same time? Then you need to be sure that the list operations (such as count()) are actually thread safe.
In other words: can you call the count()
The answer is yes (if you use the cPython implementation). The reason is Python’s global interpreter lock that ensures that a thread that’s currently working on its code will first finish its current basic Python operation as defined by the cPython implementation. Only if it terminates with this operation will the next thread be able to access the computational resource. This is ensured with a sophisticated locking scheme by the cPython implementation.
The only thing you need to know is that each basic operation in the cPython implementation is atomic. It’s executed wholly and at once before any other thread has the chance to run on the same virtual engine. Therefore, there are no race conditions. An example of such a race condition would be the following: the first thread reads a value from the list, the second thread overwrites the value, and the first thread overwrites the value again invalidating the second thread’s operation.
All cPython operations are thread-safe. But if you combine those operations into higher-level functions, those are not generally thread safe as they consist of many (possibly interleaving) operations.
Where to Go From Here?
The list.count(x) method counts the number of times the element x appears in the list.
You’ve learned the ins and outs of this important Python list method.
If you keep struggling with those basic Python commands and you feel stuck in your learning progress, I’ve got something for you: Python One-Liners (Amazon Link).
In the book, I’ll give you a thorough overview of critical computer science topics such as machine learning, regular expression, data science, NumPy, and Python basics—all in a single line of Python code!
OFFICIAL BOOK DESCRIPTION: Python One-Liners will show readers how to perform useful tasks with one line of Python code. Following a brief Python refresher, the book covers essential advanced topics like slicing, list comprehension, broadcasting, lambda functions, algorithms, regular expressions, neural networks, logistic regression and more. Each of the 50 book sections introduces a problem to solve, walks the reader through the skills necessary to solve that problem, then provides a concise one-liner Python solution with a detailed explanation.