
There’s an element of confusion regarding the term “lists of lists” in Python. I wrote this most comprehensive tutorial on list of lists in the world to remove all those confusions by beginners in the Python programming language.
This multi-modal tutorial consists of:
- Source code to copy&paste in your own projects.
- Interactive code you can execute in your browser.
- Explanatory text for each code snippet.
- Screencapture videos I recorded to help you understand the concepts faster.
- Graphics and illustrated concepts to help you get the ideas quickly.
- References to further reading and related tutorials.
So, if you’re confused by lists of lists, read on—and resolve your confusion once and for all!
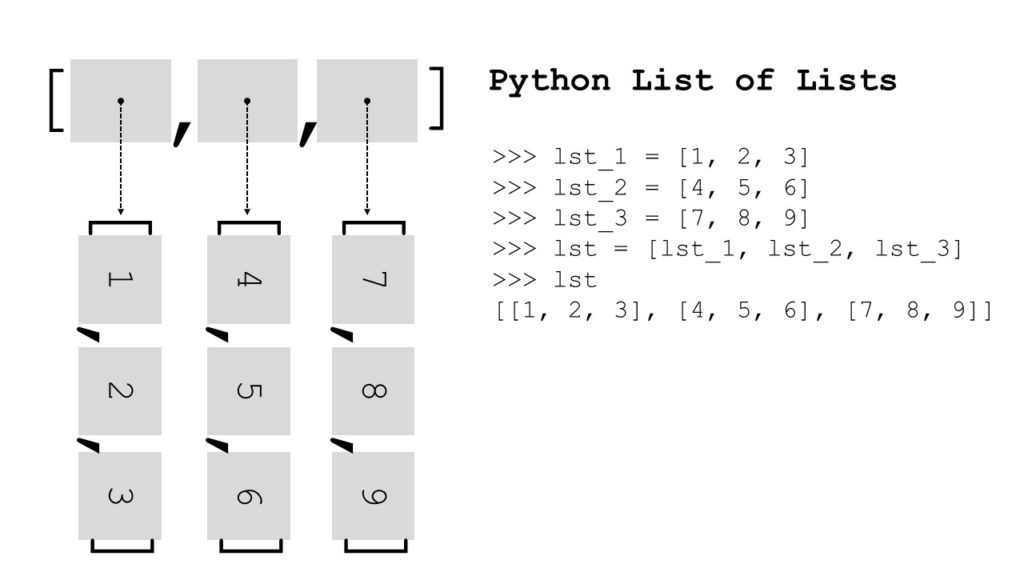
What’s a List of Lists?
Definition: A list of lists in Python is a list object where each list element is a list by itself. Create a list of list in Python by using the square bracket notation to create a nested list [[1, 2, 3], [4, 5, 6], [7, 8, 9]].
Do you want to develop the skills of a well-rounded Python professional—while getting paid in the process? Become a Python freelancer and order your book Leaving the Rat Race with Python on Amazon (Kindle/Print)!

Memory Analysis
It’s important that you understand that a list is only a series of references to memory locations.
By playing with the code visualizer, you’ll gain a deeper understanding of how Python works at its core:
Simply click the “Next” button to see how each line of code unfolds.
Create a List of Lists in Python
Create a list of lists by using the square bracket notation.
For example, to create a list of lists of integer values, use [[1, 2], [3, 4]]. Each list element of the outer list is a nested list itself.
lst = [[1, 2], [3, 4]]
There are many more advanced and programmtic ways to create and initialize a list of lists in Python—feel free to read our detailed guide on the Finxter blog:
🌍 Related Tutorial: Create and Initialize a List of Lists in Python
Convert List of Lists to One List
Say, you want to convert a list of lists [[1, 2], [3, 4]] into a single list [1, 2, 3, 4]. How to achieve this? There are different options:
- List comprehension
[x for l in lst for x in l]assuming you have a list of listslst. - Unpacking
[*lst[0], *lst[1]]assuming you have a list of two listslst. - Using the
extend()method of Python lists to extend all lists in the list of lists.
Find examples of all three methods in the following code snippet:
lst = [[1, 2], [3, 4]]
# Method 1: List Comprehension
flat_1 = [x for l in lst for x in l]
# Method 2: Unpacking
flat_2 = [*lst[0], *lst[1]]
# Method 3: Extend Method
flat_3 = []
for l in lst:
flat_3.extend(l)
## Check results:
print(flat_1)
# [1, 2, 3, 4]
print(flat_2)
# [1, 2, 3, 4]
print(flat_3)
# [1, 2, 3, 4]Due its simplicity and efficiency, the first list comprehension method is superior to the other two methods.
Convert List of Lists to Dictionary
For some applications, it’s quite useful to convert a list of lists into a dictionary.
- Databases: List of list is table where the inner lists are the database rows and you want to assign each row to a primary key in a new dictionary.
- Spreadsheet: List of list is two-dimensional spreadsheet data and you want to assign each row to a key (=row name).
- Data Analytics: You’ve got a two-dimensional matrix (=NumPy array) that’s initially represented as a list of list and you want to obtain a dictionary to ease data access.
There are three main ways to convert a list of lists into a dictionary in Python (source):
Let’s dive into each of those.
1. Dictionary Comprehension
Problem: Say, you’ve got a list of lists where each list represents a person and consists of three values for the person’s name, age, and hair color.
For convenience, you want to create a dictionary where you use a person’s name as a dictionary key and the sublist consisting of the age and the hair color as the dictionary value.
Solution: You can achieve this by using the beautiful (but, surprisingly, little-known) feature of dictionary comprehension in Python.
persons = [['Alice', 25, 'blonde'],
['Bob', 33, 'black'],
['Ann', 18, 'purple']]
persons_dict = {x[0]: x[1:] for x in persons}
print(persons_dict)
# {'Alice': [25, 'blonde'],
# 'Bob': [33, 'black'],
# 'Ann': [18, 'purple']}Explanation: The dictionary comprehension statement consists of the expression x[0]: x[1:] that assigns a person’s name x[0] to the list x[1:] of the person’s age and hair color.
Further, it consists of the context for x in persons that iterates over all “data rows”.
2. Generator Expression
A similar way of achieving the same thing is to use a generator expression in combination with the dict() constructor to create the dictionary.
persons = [['Alice', 25, 'blonde'],
['Bob', 33, 'black'],
['Ann', 18, 'purple']]
persons_dict = dict((x[0], x[1:]) for x in persons)
print(persons_dict)
# {'Alice': [25, 'blonde'],
# 'Bob': [33, 'black'],
# 'Ann': [18, 'purple']}This code snippet is almost identical to the one used in the “list comprehension” part. The only difference is that you use tuples rather than direct mappings to fill the dictionary.
3. For Loop
Of course, there’s no need to get fancy here.
You can also use a regular for loop and define the dictionary elements one by one within a simple for loop.
Here’s the alternative code:
persons = [['Alice', 25, 'blonde'],
['Bob', 33, 'black'],
['Ann', 18, 'purple']]
persons_dict = {}
for x in persons:
persons_dict[x[0]] = x[1:]
print(persons_dict)
# {'Alice': [25, 'blonde'],
# 'Bob': [33, 'black'],
# 'Ann': [18, 'purple']}
Again, you map each person’s name to the list consisting of its age and hair color.
Convert List of Lists to NumPy Array
Problem: Given a list of lists in Python. How to convert it to a 2D NumPy array?
Example: Convert the following list of lists
[[1, 2, 3], [4, 5, 6]]
into a NumPy array
[[1 2 3] [4 5 6]]
Solution: Use the np.array(list) function to convert a list of lists into a two-dimensional NumPy array.
Here’s the code:
# Import the NumPy library import numpy as np # Create the list of lists lst = [[1, 2, 3], [4, 5, 6]] # Convert it to a NumPy array a = np.array(lst) # Print the resulting array print(a) ''' [[1 2 3] [4 5 6]] '''
How to Convert a List of Lists to a NumPy Array With Different Number of Elements
Problem: Given a list of lists. The inner lists have a varying number of elements. How to convert them to a NumPy array?
Example: Say, you’ve got the following list of lists:
[[1, 2, 3], [4, 5], [6, 7, 8]]
What are the different approaches to convert this list of lists into a NumPy array?
Solution: There are three different strategies you can use. (source)
(1) Use the standard np.array() function.
# Import the NumPy library import numpy as np # Create the list of lists lst = [[1, 2, 3], [4, 5], [6, 7, 8]] # Convert it to a NumPy array a = np.array(lst) # Print the resulting array print(a) ''' [list([1, 2, 3]) list([4, 5]) list([6, 7, 8])] '''
This creates a NumPy array with three elements—each element is a list type. You can check the type of the output by using the built-in type() function:
>>> type(a) <class 'numpy.ndarray'>
(2) Make an array of arrays.
# Import the NumPy library import numpy as np # Create the list of lists lst = [[1, 2, 3], [4, 5], [6, 7, 8]] # Convert it to a NumPy array a = np.array([np.array(x) for x in lst]) # Print the resulting array print(a) ''' [array([1, 2, 3]) array([4, 5]) array([6, 7, 8])] '''
This is more logical than the previous version because it creates a NumPy array of 1D NumPy arrays (rather than 1D Python lists).
(3) Make the lists equal in length.
# Import the NumPy library import numpy as np # Create the list of lists lst = [[1, 2, 3], [4, 5], [6, 7, 8, 9]] # Calculate length of maximal list n = len(max(lst, key=len)) # Make the lists equal in length lst_2 = [x + [None]*(n-len(x)) for x in lst] print(lst_2) # [[1, 2, 3, None], [4, 5, None, None], [6, 7, 8, 9]] # Convert it to a NumPy array a = np.array(lst_2) # Print the resulting array print(a) ''' [[1 2 3 None] [4 5 None None] [6 7 8 9]] '''
You use list comprehension to “pad” None values to each inner list with smaller than maximal length.
Read More: See the original article on this blog for a more detailed version of this content.
Convert List of Lists to Dataframe
Problem: You’re given a list of lists. Your goal is to convert it into a Pandas Dataframe.
Example: Say, you want to compare salary data of different companies and job descriptions.
You’ve obtained the following salary data set as a nested list of list:
salary = [['Google', 'Machine Learning Engineer', 121000],
['Google', 'Data Scientist', 109000],
['Google', 'Tech Lead', 129000],
['Facebook', 'Data Scientist', 103000]]How can you convert this into a Pandas Dataframe?
Solution: The straight-forward solution is to use the pandas.DataFrame() constructor that creates a new Dataframe object from different input types such as NumPy arrays or lists.
Here’s how to do it for the given example:
import pandas as pd
salary = [['Google', 'Machine Learning Engineer', 121000],
['Google', 'Data Scientist', 109000],
['Google', 'Tech Lead', 129000],
['Facebook', 'Data Scientist', 103000]]
df = pd.DataFrame(salary)This results in the following Dataframe:
print(df)
'''
0 1 2
0 Google Machine Learning Engineer 121000
1 Google Data Scientist 109000
2 Google Tech Lead 129000
3 Facebook Data Scientist 103000
'''An alternative is the pandas.DataFrame.from_records() method that generates the same output:
df = pd.DataFrame.from_records(salary)
print(df)
'''
0 1 2
0 Google Machine Learning Engineer 121000
1 Google Data Scientist 109000
2 Google Tech Lead 129000
3 Facebook Data Scientist 103000
'''If you want to add column names to make the output prettier, you can also pass those as a separate argument:
import pandas as pd
salary = [['Google', 'Machine Learning Engineer', 121000],
['Google', 'Data Scientist', 109000],
['Google', 'Tech Lead', 129000],
['Facebook', 'Data Scientist', 103000]]
df = pd.DataFrame(salary, columns=['Company', 'Job', 'Salary($)'])
print(df)
'''
Company Job Salary($)
0 Google Machine Learning Engineer 121000
1 Google Data Scientist 109000
2 Google Tech Lead 129000
3 Facebook Data Scientist 103000
'''If the first list of the list of lists contains the column name, use slicing to separate the first list from the other lists:
import pandas as pd
salary = [['Company', 'Job', 'Salary($)'],
['Google', 'Machine Learning Engineer', 121000],
['Google', 'Data Scientist', 109000],
['Google', 'Tech Lead', 129000],
['Facebook', 'Data Scientist', 103000]]
df = pd.DataFrame(salary[1:], columns=salary[0])
print(df)
'''
Company Job Salary($)
0 Google Machine Learning Engineer 121000
1 Google Data Scientist 109000
2 Google Tech Lead 129000
3 Facebook Data Scientist 103000
'''Slicing is a powerful Python feature and before you can master Pandas, you need to master slicing.
Related Tutorial:
Summary: To convert a list of lists into a Pandas DataFrame, use the pd.DataFrame() constructor and pass the list of lists as an argument. An optional columns argument can help you structure the output.
Related article:
Convert List of Lists to List of Tuples
If you’re in a hurry, here’s the short answer:
Use the list comprehension statement [tuple(x) for x in list] to convert each element in your list to a tuple. This works also for list of lists with varying number of elements.
But there’s more to it and studying the two main method to achieve the same objective will make you a better coder. So keep reading:
Method 1: List Comprehension + tuple()
Problem: How to convert a list of lists into a list of tuples?
Example: You’ve got a list of lists [[1, 2], [3, 4], [5, 6]] and you want to convert it into a list of tuples [(1, 2), (3, 4), (5, 6)].

Solution: There are different solutions to convert a list of lists to a list of tuples. Use list comprehension in its most basic form:
lst = [[1, 2], [3, 4], [5, 6]] tuples = [tuple(x) for x in lst] print(tuples) # [(1, 2), (3, 4), (5, 6)]
This approach is simple and effective.
List comprehension defines how to convert each value (x in the example) to a new list element. As each list element is a new tuple, you use the constructor tuple(x) to create a new tuple from the list x.
If you have three list elements per sublist, you can use the same approach with the conversion:
lst = [[1, 2, 1], [3, 4, 3], [5, 6, 5]] tuples = [tuple(x) for x in lst] print(tuples) # [(1, 2, 1), (3, 4, 3), (5, 6, 5)]
You can see the execution flow in the following interactive visualization (just click the “Next” button to see what’s happening in the code):
And if you have a varying number of list elements per sublist, this approach still works beautifully:
lst = [[1], [2, 3, 4], [5, 6, 7, 8]] tuples = [tuple(x) for x in lst] print(tuples) # [(1,), (2, 3, 4), (5, 6, 7, 8)]
You see that an approach with list comprehension is the best way to convert a list of lists to a list of tuples. But are there any alternatives?
Method 2: Map Function + tuple()
An alternative is to use the map function that applies a specified function on each element of an iterable.
💡 Guido van Rossum, the creator of Python, didn’t like the map() function as it’s less readable (and less efficient) than the list comprehension version. Feel free to read a detailed discussion on how exactly he argued in my blog article.
So, without further ado, here’s how you can convert a list of lists into a list of tuples using the map() function:
lst = [[1], [2, 3, 4], [5, 6, 7, 8]] tuples = list(map(tuple, lst)) print(tuples) # [(1,), (2, 3, 4), (5, 6, 7, 8)]
The first argument of the map() function is the tuple function name.
This tuple() function converts each element on the given iterable lst (the second argument) into a tuple.
The result of the map() function is an iterable so you need to convert it to a list before printing it to the shell because the default string representation of an iterable is not human-readable.
Related Articles
- How to Convert a List of Lists to a List of Tuples
- How to Convert a List of Tuples to a List of Lists
- How to Convert a List of Lists to a Pandas Dataframe
- How to Convert a List of Lists to a NumPy Array
- How to Convert a List of Lists to a Dictionary in Python
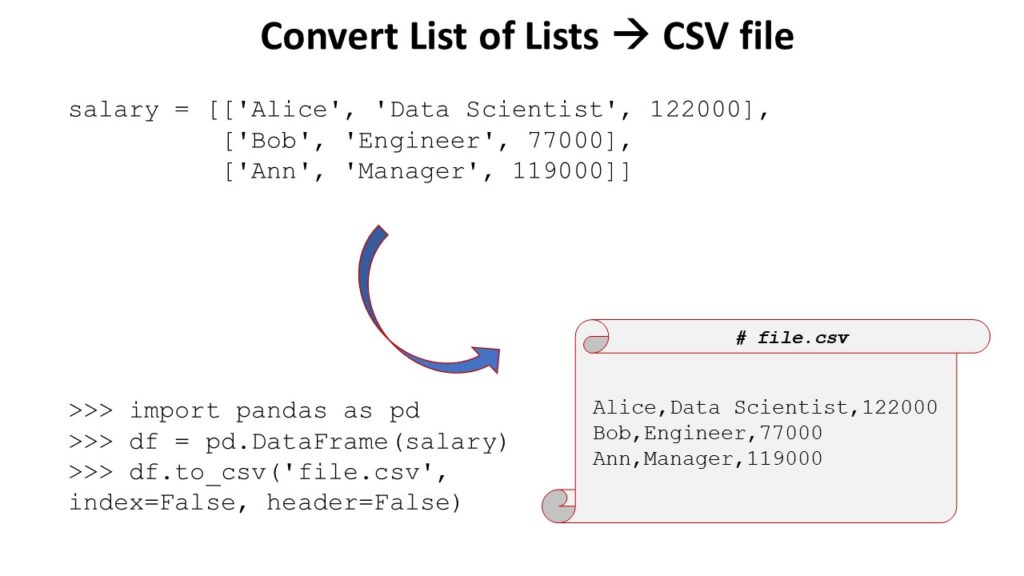
Convert List of Lists to CSV File
Problem: How to convert a list of lists to a csv file?
Example: Given is a list of list—for example salary data of employees in a given company:
salary = [['Alice', 'Data Scientist', 122000],
['Bob', 'Engineer', 77000],
['Ann', 'Manager', 119000]]Your goal is to write the content of the list of lists into a comma-separated-values (CSV) file format.
Your outfile should look like this:
# file.csv
Alice,Data Scientist,122000
Bob,Engineer,77000
Ann,Manager,119000Solution: There are four simple ways to convert a list of lists to a CSV file in Python.
- CSV: Import the
csvmodule in Python, create a csv writer object, and write the list of lists to the file in using thewriterows()method on the writer object. - Pandas: Import the pandas library, create a Pandas DataFrame, and write the DataFrame to a file using the DataFrame method
DataFrame.to_csv('file.csv'). - NumPy: Import the NumPy library, create a NumPy array, and write the output to a CSV file using the
numpy.savetxt('file.csv', array, delimiter=',')method. - Python: Use a pure Python implementation that doesn’t require any library by using the Python file I/O functionality.
My preference is method 2 (Pandas) because it’s simplest to use and most robust for different input types (numerical or textual).
Method 1: Python’s CSV Module
You can convert a list of lists to a CSV file in Python easily—by using the csv library.
This is the most customizable of all four methods.
salary = [['Alice', 'Data Scientist', 122000],
['Bob', 'Engineer', 77000],
['Ann', 'Manager', 119000]]
# Method 1
import csv
with open('file.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerows(salary)Output:
# file.csv
Alice,Data Scientist,122000
Bob,Engineer,77000
Ann,Manager,119000In the code, you first open the file using Python’s standard open() command. Now, you can write content to the file object f.
Next, you pass this file object to the constructor of the CSV writer that implements some additional helper method—and effectively wraps the file object providing you with new CSV-specific functionality such as the writerows() method.
You now pass a list of lists to the writerows() method of the CSV writer that takes care of converting the list of lists to a CSV format.
You can customize the CSV writer in its constructor (e.g., by modifying the delimiter from a comma ',' to a whitespace ' ' character).
Have a look at the specification to learn about advanced modifications.
Method 2: Pandas DataFrame to_csv()
You can convert a list of lists to a Pandas DataFrame that provides you with powerful capabilities such as the to_csv() method.
This is the easiest method and it allows you to avoid importing yet another library (I use Pandas in many Python projects anyways).
salary = [['Alice', 'Data Scientist', 122000],
['Bob', 'Engineer', 77000],
['Ann', 'Manager', 119000]]
# Method 2
import pandas as pd
df = pd.DataFrame(salary)
df.to_csv('file2.csv', index=False, header=False)Output:
# file2.csv
Alice,Data Scientist,122000
Bob,Engineer,77000
Ann,Manager,119000You create a Pandas DataFrame—which is Python’s default representation of tabular data. Think of it as an Excel spreadsheet within your code (with rows and columns).
The DataFrame is a very powerful data structure that allows you to perform various methods. One of those is the to_csv() method that allows you to write its contents into a CSV file.
You set the index and header arguments of the to_csv() method to False because Pandas, per default, adds integer row and column indices 0, 1, 2, ….
Again, think of them as the row and column indices in your Excel spreadsheet. You don’t want them to appear in the CSV file so you set the arguments to False.
If you want to customize the CSV output, you’ve got a lot of special arguments to play with. Check out this article for a comprehensive list of all arguments.
Related article: Pandas Cheat Sheets to Pin to Your Wall
Method 3: NumPy savetext()
NumPy is at the core of Python’s data science and machine learning functionality. Even Pandas uses NumPy arrays to implement critical functionality.
You can convert a list of lists to a CSV file by using NumPy’s savetext() function and passing the NumPy array as an argument that arises from conversion of the list of lists.
This method is best if you have numerical data only—otherwise, it’ll lead to complicated data type conversions which are not recommended.
a = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
# Method 3
import numpy as np
a = np.array(a)
np.savetxt('file3.csv', a, delimiter=',')Output:
# file3.csv
1.000000000000000000e+00,2.000000000000000000e+00,3.000000000000000000e+00
4.000000000000000000e+00,5.000000000000000000e+00,6.000000000000000000e+00
7.000000000000000000e+00,8.000000000000000000e+00,9.000000000000000000e+00The output doesn’t look pretty: it stores the values as floats.
But no worries, you can reformat the output using the format argument fmt of the savetxt() method (more here).
However, I’d recommend you stick to method 2 (Pandas) to avoid unnecessary complexity in your code.
Related:
- [Get Your Book] Coffee Break NumPy and become a data science master.
Method 4: Pure Python Without External Dependencies
If you don’t want to import any library and still convert a list of lists into a CSV file, you can use standard Python implementation as well: it’s not complicated and efficient.
However, if possible you should rely on libraries that do the job for you.
This method is best if you won’t or cannot use external dependencies.
salary = [['Alice', 'Data Scientist', 122000],
['Bob', 'Engineer', 77000],
['Ann', 'Manager', 119000]]
# Method 4
with open('file4.csv','w') as f:
for row in salary:
for x in row:
f.write(str(x) + ',')
f.write('\n')Output:
# file4.csv
Alice,Data Scientist,122000,
Bob,Engineer,77000,
Ann,Manager,119000,In the code, you first open the file object f. Then you iterate over each row and each element in the row and write the element to the file—one by one.
After each element, you place the comma to generate the CSV file format. After each row, you place the newline character '\n'.
💡 Note: To get rid of the trailing comma, you can check if the element x is the last element in the row within the loop body and skip writing the comma if it is.
Related Tutorial: Join the Finxter community and download your 8+ Python cheat sheets to refresh your code understanding.
Sort List of Lists by Key
Every computer scientist loves sorting things. In this section, I’ll show you how you can modify the default Python sorting behavior with the key argument.
Definition and Usage: To customize the default sorting behavior of the list.sort() and sorted() method, use the optional key argument by passing a function that returns a comparable value for each element in the list.
Syntax: You can call this method on each list object in Python (Python versions 2.x and 3.x).
Here’s the syntax:
list.sort(key=None, reverse=False)
| Argument | Description |
|---|---|
key | (Optional. Default None.) Pass a function that takes a single argument and returns a comparable value. The function is then applied to each element in the list. Then, the method sorts based on the key function results rather than the elements themselves. |
reverse | (Optional. Default False.) The order of the list elements. If False, sorting is in ascending order. If True, it’s in descending order. |
Related articles:
- Python List Methods [Overview]
- Python List
sort()– The Ultimate Guide - Python Lists – Everything You Need to Know to Get Started
The list.sort() method takes another function as an optional key argument that allows you to modify the default sorting behavior.
The key function is then called on each list element and returns another value based on which the sorting is done. Hence, the key function takes one input argument (a list element) and returns one output value (a value that can be compared).
Here’s an example:
>>> lst = [[1, 2], [3, 2], [3, 3, 4], [1, 0], [0, 1], [4, 2]] >>> lst.sort() >>> lst [[0, 1], [1, 0], [1, 2], [3, 2], [3, 3, 4], [4, 2]] >>> lst.sort(key=lambda x:x[0]) >>> lst [[0, 1], [1, 0], [1, 2], [3, 2], [3, 3, 4], [4, 2]] >>> lst.sort(key=lambda x:x[1]) >>> lst [[1, 0], [0, 1], [1, 2], [3, 2], [4, 2], [3, 3, 4]]
You can see that in the first two examples, the list is sorted according to the first inner list value.
In the third example, the list is sorted according to the second inner list value.
You achieve this by defining a key function key=lambda x: x[1] that takes one list element x (a list by itself) as an argument and transforms it into a comparable value x[1] (the second list value).
Related article:
Sort List of Lists by First Element
Both the list sort() method and the sorted() built-in Python function sort a list of lists by their first element.
Here’s an example:
lst = [[1, 2, 3],
[3, 2, 1],
[2, 2, 2]]
lst.sort()
print(lst)
# [[1, 2, 3],
# [2, 2, 2],
# [3, 2, 1]]The default sorting routine takes the first list element of any inner list as a decision criteria. Only if the first element would be the same for two values, the second list element would be taken as a tiebreaker.
Sort List of Lists Lexicographically
Problem: Given a list of lists. Sort the list of strings in lexicographical order!
💡 Lexicographical order is to sort by the first inner list element. If they are the same, you sort by the second inner list element, and so on.
Example:
We want to sort the following list where the first elements ot the inner list are the same:
[[1, 2, 3], [3, 2, 1], [2, 2, 2], [2, 0, 3]] -->
[[1, 2, 3], [2, 0, 3], [2, 2, 2], [3, 2, 1]]Solution: Use the list.sort() method without argument to solve the list in lexicographical order.
lst = [[1, 2, 3],
[3, 2, 1],
[2, 2, 2],
[2, 0, 3]]
lst.sort()
print(lst)
'''
[[1, 2, 3],
[2, 0, 3],
[2, 2, 2],
[3, 2, 1]]
'''Sort List of Lists By Length
Problem: Given a list of lists. How can you sort them by length?
Example: You want to sort your list of lists [[2, 2], [4], [1, 2, 3, 4], [1, 2, 3]] by length—starting with the shortest list.
Thus, your target result is [[4], [2, 2], [1, 2, 3], [1, 2, 3, 4]]. How to achieve that?
Solution: Use the len() function as key argument of the list.sort() method like this: list.sort(key=len).
As the len() function is a Python built-in function, you don’t need to import or define anything else.
Here’s the code solution:
lst = [[2, 2], [4], [1, 2, 3, 4], [1, 2, 3]] lst.sort(key=len) print(lst)
The output is the list sorted by length of the string:
[[4], [2, 2], [1, 2, 3], [1, 2, 3, 4]]
You can also use this technique to sort a list of strings by length.
List Comprehension Python List of Lists
You’ll learn three ways how to apply list comprehension to a list of lists:
- to flatten a list of lists
- to create a list of lists
- to iterate over a list of lists
Additionally, you’ll learn how to apply nested list comprehension. So let’s get started!
Python List Comprehension Flatten List of Lists
Problem: Given a list of lists. How to flatten the list of lists by getting rid of the inner lists—and keeping their elements?
Example: You want to transform a given list into a flat list like here:
lst = [[2, 2], [4], [1, 2, 3, 4], [1, 2, 3]] # ... Flatten the list here ... print(lst) # [2, 2, 4, 1, 2, 3, 4, 1, 2, 3]

Solution: Use a nested list comprehension statement [x for l in lst for x in l] to flatten the list.
lst = [[2, 2], [4], [1, 2, 3, 4], [1, 2, 3]] # ... Flatten the list here ... lst = [x for l in lst for x in l] print(lst) # [2, 2, 4, 1, 2, 3, 4, 1, 2, 3]
Explanation: In the nested list comprehension statement [x for l in lst for x in l], you first iterate over all lists in the list of lists (for l in lst).
Then, you iterate over all elements in the current list (for x in l). This element, you just place in the outer list, unchanged, by using it in the “expression” part of the list comprehension statement [x for l in lst for x in l].
Python List Comprehension Create List of Lists
Problem: How to create a list of lists by modifying each element of an original list of lists?
Example: You’re given the list
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
You want to add one to each element and create a new list of lists:
[[2, 3, 4], [5, 6, 7], [8, 9, 10]]
Solution: Use two nested list comprehension statements, one to create the outer list of lists, and one to create the inner lists.
lst = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] new = [[x+1 for x in l] for l in lst] print(new) # [[2, 3, 4], [5, 6, 7], [8, 9, 10]]
Explanation: The main idea is to use as “expression” of the outer list comprehension statement a list comprehension statement by itself.
Remember, you can create any object you want in the expression part of your list comprehension statement. Read more here.
Print List of Lists Without Brackets
Problem: Given a list of lists, print it one row per line—without brackets.
Example: Consider the following example list:
lst = [[1, 2, 3], [4, 5, 6]]
You want to print the list of lists with a newline character after each inner list:
1 2 3 4 5 6
Solution: Use a for loop and a simple print statement in which you unpack all inner list elements using the asterisk operator.
Here’s an example::
lst = [[1, 2, 3], [4, 5, 6]]
for x in lst:
print(*x)
The output has the desired form:
1 2 3 4 5 6
Explanation: The asterisk operator “unpacks” all values in the inner list x into the print statement.
You must know that the print statement also takes multiple inputs and prints them, whitespace-separated, to the shell.
Related articles:
Print List of Lists With Newline & Align Columns
Problem: How to print a list of lists with a new line after each list so that the columns are aligned?
Example: Say, you’re going to print the list of lists.
[['Alice', 'Data Scientist', 121000], ['Bob', 'Java Dev', 99000], ['Ann', 'Python Dev', 111000]]
How to align the columns?
Alice 'Data Scientist', 121000], Bob 'Java Dev', 99000], Ann 'Python Dev', 111000]]
Solution: Use the following code snippet to print the list of lists and align all columns (no matter how many characters each string in the list of lists occupies).
# Create the list of lists
lst = [['Alice', 'Data Scientist', '121000'],
['Bob', 'Java Dev', '99000'],
['Ann', 'Python Dev', '111000']]
# Find maximal length of all elements in list
n = max(len(x) for l in lst for x in l)
# Print the rows
for row in lst:
print(''.join(x.ljust(n + 2) for x in row))The output is the desired:
Alice Data Scientist 121000 Bob Java Dev 99000 Ann Python Dev 111000
Explanation:
- First, you determine the length
n(in characters) of the largest string in the list of lists using the statementmax(len(x) for l in lst for x in l). The code uses a nested for loop in a generator expression to achieve this. - Second, you iterate over each list in the list of lists (called
row). - Third, you create a string representation with columns aligned by ‘padding’ each row element so that it occupies
n+2characters of space. The missing characters are filled with empty spaces.
You can see the code in action in the following memory visualizer. Just click “Next” to see which objects are created in memory if you run the code in Python:
Related articles: You may need to refresh your understanding of the following Python features used in the code:
Python List of Lists Enumerate
Say, you’ve given the following code that uses the enumerate function on a list of lists:
lst = [['Alice', 'Data Scientist', '121000'],
['Bob', 'Java Dev', '99000'],
['Ann', 'Python Dev', '111000']]
for i,l in enumerate(lst):
print('list ' + str(i) + ': ' + str(len(l)) + ' elements')
The output is:
list 0: 3 elements list 1: 3 elements list 2: 3 elements
The enumerate() function creates an iterator of (index, element) pairs for all elements in a given list.
If you have a list of lists, the list elements are list themselves.
So, the enumerate function generates (index, list) pairs. You can use them in the loop body—for example, to print the length of the i-th list elements.
Remove Empty – Python List of Lists
How can you remove all empty lists from a list of lists?
Say, you’ve got a list of lists [[1, 2, 3], [1, 2], [], [], [], [1, 2, 3, 4], [], []] and you want all empty lists removed to obtain the list of lists [[1, 2, 3], [1, 2], [1, 2, 3, 4]].
Solution: Use list comprehension [x for x in list if x] to filter the list and remove all lists that are empty.
lst = [[1, 2, 3], [1, 2], [], [], [], [1, 2, 3, 4], [], []] print([x for x in lst if x]) # [[1, 2, 3], [1, 2], [1, 2, 3, 4]]
The condition if x evaluates to False only if the list x is empty. In all other cases, it evaluates to True and the element is included in the new list.
Remove Duplicates – Python List of Lists
What’s the best way to remove duplicates from a Python list of lists?
This is a popular coding interview question at Google, Facebook, and Amazon. In the following, I’ll show you how (and why) it works—so keep reading!
Method 1: Naive Method
Algorithm:
- Go over each element and check whether this element already exists in the list.
- If so, remove it.
The problem is that this method has quadratic time complexity because you need to check for each element if it exists in the list (which is n * O(n) for n elements).
lst = [[1, 1], [0, 1], [0, 1], [1, 1]]
dup_free = []
for x in lst:
if x not in dup_free:
dup_free.append(x)
print(dup_free)
# [[1, 1], [0, 1]]Method 2: Temporary Dictionary Conversion
Algorithm: A more efficient way in terms of time complexity is to create a dictionary out of the elements in the list to remove all duplicates and convert the dictionary back to a list.
This preserves the order of the original list elements.
lst = [[1, 1], [0, 1], [0, 1], [1, 1]] # 1. Convert into list of tuples tpls = [tuple(x) for x in lst] # 2. Create dictionary with empty values and # 3. convert back to a list (dups removed) dct = list(dict.fromkeys(tpls)) # 4. Convert list of tuples to list of lists dup_free = [list(x) for x in lst] # Print everything print(dup_free) # [[1, 1], [0, 1], [0, 1], [1, 1]]
All of the following four sub-methods are linear-runtime operations.
Therefore, the algorithm has linear runtime complexity and is more efficient than the naive approach (method 1).
- Convert into a list of tuples using list comprehension
[tuple(x) for x in lst]. Tuples are hashable and can be used as dictionary keys—while lists can not! - Convert the list of tuples to a dictionary with
dict.fromkeys(tpls)to map tuples to dummy values. Each dictionary key can exist only once so duplicates are removed at this point. - Convert the dictionary into a list of tuples with
list(...). - Convert the list of tuples into a list of lists using list comprehension
[list(x) for x in lst].

Each list element (= a list) becomes a tuple which becomes a new key to the dictionary.
For example, the list [[1, 1], [0, 1], [0, 1]] becomes the list [(1, 1), (0, 1), (0, 1)] the dictionary {(1, 1):None, .(0, 1):None}
All elements that occur multiple times will be assigned to the same key. Thus, the dictionary contains only unique keys—there cannot be multiple equal keys.
As dictionary values, you take dummy values (per default).
Then, you convert the dictionary back to a list of lists, throwing away the dummy values.
Do Python Dictionaries Preserve the Ordering of the Keys?
Surprisingly, the dictionary keys in Python preserve the order of the elements. So, yes, the order of the elements is preserved. (source)
This is surprising to many readers because countless online resources like this one argue that the order of dictionary keys is not preserved.
They assume that the underlying implementation of the dictionary key iterables uses sets—and sets are well-known to be agnostic to the ordering of elements.
But this assumption is wrong. The built-in Python dictionary implementation in cPython preserves the order.
Here’s an example, feel free to create your own examples and tests to check if the ordering is preserved.
lst = ['Alice', 'Bob', 'Bob', 1, 1, 1, 2, 3, 3]
dic = dict.fromkeys(lst)
print(dic)
# {'Alice': None, 'Bob': None, 1: None, 2: None, 3: None}You see that the order of elements is preserved so when converting it back, the original ordering of the list elements is still preserved:
print(list(dic)) # ['Alice', 'Bob', 1, 2, 3]
However, you cannot rely on it because any Python implementation could, theoretically, decide not to preserve the order (notice the “COULD” here is 100% theoretical and does not apply to the default cPython implementation).
If you need to be certain that the order is preserved, you can use the ordered dictionary library. In cPython, this is just a wrapper for the default dict implementation.
Method 3: Set Conversion
Given a list of lists, the goal is to remove all elements that exist more than once in the list.
Sets in Python allow only a single instance of an element. So by converting the list to a set, all duplicates are removed.
In contrast to the naive approach (checking all pairs of elements if they are duplicates) that has quadratic time complexity, this method has linear runtime complexity.
Why?
Because the runtime complexity of creating a set is linear in the number of set elements. Now, you convert the set back to a list, and voilà, the duplicates are removed.
lst = list(range(10)) + list(range(10)) lst = list(set(lst)) print(lst) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # Does this also work for tuples? Yes! lst = [(10,5), (10,5), (5,10), (3,2), (3, 4)] lst = list(set(lst)) print(lst) # [(3, 4), (10, 5), (5, 10), (3, 2)]
However, converting a list to a set doesn’t guarantee to preserve the order of the list elements. The set loses all ordering information.
Also, you cannot create a set of lists because lists are non-hashable data types:
>>> set([[1,2], [1,1]])
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
set([[1,2], [1,1]])
TypeError: unhashable type: 'list'But we can find a simple workaround to both problems as you’ll see in the following method.
Linear-Runtime Method with Set to Remove Duplicates From a List of Lists
This third approach uses a set to check if the element is already in the duplicate-free list.
As checking membership on sets is much faster than checking membership on lists, this method has linear runtime complexity as well (membership has constant runtime complexity).
lst = [[1, 1], [0, 1], [0, 1], [1, 1]]
dup_free = []
dup_free_set = set()
for x in lst:
if tuple(x) not in dup_free_set:
dup_free.append(x)
dup_free_set.add(tuple(x))
print(dup_free)
# [[1, 1], [0, 1]]This approach of removing duplicates from a list while maintaining the order of the elements has linear runtime complexity as well.
And it works for all programming languages without you having to know implementation details about the dictionary in Python. But, on the other hand, it’s a bit more complicated.
Related articles:
- How to Remove Duplicates From a List of Lists in Python?
- Python List Remove
- The Ultimate Guide to Python Dictionaries!
- Remove Duplicates From Python Lists
- Python List of Lists
Reverse – Python List of Lists
The list.reverse() reverses the order of the elements in the list. If you want to create a new list with reversed elements, use slicing with negative step size list[::-1].
Here’s a short example:
>>> lst = [1, 2, 3, 4] >>> lst.reverse() >>> lst [4, 3, 2, 1]
In the first line of the example, you create the list lst. You then reverse the order of the elements in the list and print it to the shell.
Flat Reverse
But if you use the list.reverse() method on a list of lists, you obtain only a “flat” reverse—only the outer list is reversed but not the inner lists.
lst = [[1, 2], [1, 2, 3, 4]] lst.reverse() print(lst) # [[1, 2, 3, 4], [1, 2]]
So the order of the two inner lists is now reversed but not the order of their list elements.
Deep Reverse
What if you want not only to reverse a list but running a deep reverse where all nested lists are also reversed in a recursive manner?
Here’s how you can do it:
def deep_reverse(lst):
''' Reverses a nested list in place'''
# Reverse top-level list
lst.reverse()
# Recursively reverse all nested lists
for element in lst:
if isinstance(element, list):
deep_reverse(element)
lst = [[1, 2], [1, 2, 3, 4]]
deep_reverse(lst)
print(lst)
# [[4, 3, 2, 1], [2, 1]]Not only the first-level list is reversed but also the second-level list. The code is loosely inspired from this article.
Zip Python List of Lists
The zip() function takes a number of iterables and aggregates them to a single one by combining the i-th values of each iterable into a tuple.
For example, zip together lists [1, 2, 3] and [4, 5, 6] to [(1,4), (2,5), (3,6)].
Problem: Passing a list of lists into the zip function doesn’t work because the zip function requires an arbitrary number of iterables (and not iterables of iterables).
Example: Say, you want to zip a list of lists:
>>> zip([[1, 2], [3, 4], [5, 6]]) [[1, 3, 5], [2, 4, 6]]
🛑 ATTENTION: THIS CODE DOESN’T ACCOMPLISH THIS!
Solution: Unpack the lists in the list of lists using the “unpacking” asterisk operator *.
>>> list(zip(*[[1, 2], [3, 4], [5, 6]])) [(1, 3, 5), (2, 4, 6)]
Think of it this way: the asterisk operator removes the “outer” bracket of the list and passes all inner lists as arguments.
Note that you also convert the zip object returned by the zip function to a list using the list(...) constructor.
Unpack Python List of Lists
You’ve already seen an example of unpacking a list of lists in the previous section (the zip function):
>>> list(zip(*[[1, 2], [3, 4], [5, 6]])) [(1, 3, 5), (2, 4, 6)]
The zip function expects a number of iterables but a list of lists is only a single iterable.
To solve this issue, you unpack the inner lists into the zip function to use them as argument for the iterables. This way, zip() runs with three iterable arguments: [1, 2], [3, 4], and [5, 6].
Related article: The Unpacking Operator (Asterisk)
Average – Python List of Lists
Problem: You have a list of lists and you want to calculate the average of the different columns.
Example: Given the following list of lists with four rows and three columns.
data = [[0, 1, 0],
[1, 1, 1],
[0, 0, 0],
[1, 1, 0]]You want to have the average values of the three columns:
[average_col_1, average_col_2, average_col_3]
Method 1: Average in Python (No Library)
A simple one-liner with list comprehension in combination with the zip() function on the unpacked list to transpose the list of lists does the job in Python.
data = [[0, 1, 0],
[1, 1, 1],
[0, 0, 0],
[1, 1, 0]]
# Method 1: Pure Python
res = [sum(x) / len(x) for x in zip(*data)]
print(res)
# [0.5, 0.75, 0.25]Do you love Python one-liners? I do for sure—I’ve even written a whole book about it with San Francisco Publisher NoStarch. Click to check out the book in a new tab:

You can visualize the code execution and memory objects of this code in the following tool (just click “Next” to see how one step of the code unfolds).
Method 2: Average with NumPy Library
You create a NumPy array out of the data and pass it to the np.average() function.
data = [[0, 1, 0],
[1, 1, 1],
[0, 0, 0],
[1, 1, 0]]
# Method 2: NumPy
import numpy as np
a = np.array(data)
res = np.average(a, axis=0)
print(res)
# [0.5 0.75 0.25]The axis argument of the average function defines along which axis you want to calculate the average value.
- If you want to average columns, define
axis=0. - If you want to average rows, define
axis=1. - If you want to average over all values, skip this argument.
Method 3: Mean Statistics Library + Map()
Just to show you another alternative, here’s one using the map() function and our zip(*data) trick to transpose the “matrix” data.
data = [[0, 1, 0],
[1, 1, 1],
[0, 0, 0],
[1, 1, 0]]
# Method 3: Statistics + Map()
import statistics
res = map(statistics.mean, zip(*data))
print(list(res))
# [0.5, 0.75, 0.25]The map(function, iterable) function applies function to each element in iterable.
As an alternative, you can also use list comprehension as shown in method 1 in this tutorial.
💡 In fact, Guido van Rossum, the creator of Python and Python’s benevolent dictator for life (BDFL), prefers list comprehension over the map() function.
Python Sum List of Lists
Problem: Given a list of lists representing a data matrix with n rows and m columns. How to sum over the columns of this matrix?
In the following, you’re going to learn different ways to accomplish this in Python.
Let’s ensure that you’re on the same page. Here’s a graphical representation of the list of lists and what you want to achieve:

Example: Given the following code.
# Your list of lists
data = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
# ... Algorithm here ...
print(res)
# OUTPUT: [12, 15, 18]Next, you’ll learn three different methods to sum over the columns.
Related articles:
Flat Copy – Python List of Lists
Before you can truly understand the copy() method in Python, you must understand the concept of a “shallow copy” or “flat copy”.
In object-oriented languages such as Python, everything is an object. The list is an object and the elements in the list are objects, too.
A shallow copy of the list creates a new list object—the copy—but it doesn’t create new list elements but simply copies the references to these objects.

You can see that the list below is only a shallow copy pointing to the same elements as the original list.
In Python, the list.copy() method only produces a shallow copy which has much faster runtime complexity.
Here’s an example showing exact this scenario:
lst = [[1, 0], [2, 2], [0, 0]] lst_copy = lst.copy() lst_copy[2].append(42) print(lst[2])
Changing the third list element of the copied list impacts the third list element of the original list.
Thus, the output is:
[0, 0, 42]
You can see a live execution visualization in the following great tool to visualize the memory usage of this Python snippet at every stage of the execution. Just click “Next” to see how the memory unfolds:
Hint: If you copy a list of lists using the list.copy() method, be aware that any change you’re performing on a list in the copied list of lists is visible in the original list.
If you aren’t okay with that, check out the following section about deep copies of Python lists:
Deep Copy – Python List of Lists
Having understood the concept of a shallow copy, it’s now easy to understand the concept of a deep copy
Read my article deep vs shallow copy to gain a deeper understanding.
- A shallow copy only copies the references of the list elements.
- A deep copy copies the list elements themselves which can lead to a highly recursive behavior because the list elements may be lists themselves that need to be copied deeply and so on.
Here’s a simple deep copy of the same list as shown previously:

In contrast to the shallow copy, the list [1, 2] is copied separately for the deep copy list. If one changes this nested list in the original list, the change would not be visible at the deep copy. (Because the nested list of the deep copy list is an independent object in memory.)
Note that in a deep copy, the string object must not be copied. Why? Because strings are immutable so you cannot change them (and, thus, there will be no dirty “side effects” seen by other copies of the list pointing to the same object in memory).
To get a deep copy in Python, import the copy module and use the deepcopy() method:
import copy lst = [[1, 0], [2, 2], [0, 0]] lst_copy = copy.deepcopy(lst) lst_copy[2].append(42) print(lst[2]) # [0, 0]
Again, visualize the execution flow of the following code snippet right here in your browser by clicking “Next”:
Related Articles:
How to Filter a Python List of Lists?
Short answer: To filter a list of lists for a condition on the inner lists, use the list comprehension statement [x for x in list if condition(x)] and replace condition(x) with your filtering condition that returns True to include inner list x, and False otherwise.
Lists belong to the most important data structures in Python—every master coder knows them by heart! Surprisingly, even intermediate coders don’t know the best way to filter a list—let alone a list of lists in Python. This tutorial shows you how to do the latter!
Problem: Say, you’ve got a list of lists. You want to filter the list of lists so that only those inner lists remain that satisfy a certain condition. The condition is a function of the inner list—such as the average or sum of the inner list elements.

Example: Given the following list of lists with weekly temperature measurements per week—and one inner list per week.
# Measurements of a temperature sensor (7 per week)
temperature = [[10, 8, 9, 12, 13, 7, 8], # week 1
[9, 9, 5, 6, 6, 9, 11], # week 2
[10, 8, 8, 5, 6, 3, 1]] # week 3How to filter out the colder weeks with average temperature value <8? This is the output you desire:
print(cold_weeks) # [[9, 9, 5, 6, 6, 9, 11], [10, 8, 8, 5, 6, 3, 1]]
There are two semantically equivalent methods to achieve this: list comprehension and the map() function. Let’s explore both variants next:
# Measurements of a temperature sensor (7 per week)
temperature = [[10, 8, 9, 12, 13, 7, 8], # week 1
[9, 9, 5, 6, 6, 9, 11], # week 2
[10, 8, 8, 5, 6, 3, 1]] # week 3
# How to filter weeks with average temperature <8?
# Method 1: List Comprehension
cold_weeks = [x for x in temperature if sum(x)/len(x)<8]
print(cold_weeks)
# [[9, 9, 5, 6, 6, 9, 11], [10, 8, 8, 5, 6, 3, 1]]
# Method 2: Map()
cold_weeks = list(filter(lambda x: sum(x) / len(x) < 8, temperature))
print(cold_weeks)
# [[9, 9, 5, 6, 6, 9, 11], [10, 8, 8, 5, 6, 3, 1]]
Related articles:
- How to Filter a Python List of Lists?
- List Comprehension — Python List of Lists
- Filter() vs List Comprehension
- Nested List Comprehension
- The Ultimate Guide to Python Lists
- List Comprehension
Group By – Python List of Lists
This tutorial shows you how to group the inner lists of a Python list of lists by common element.
Problem: Given a list of lists. Group the elements by common element and store the result in a dictionary (key = common element).

Example: Say, you’ve got a database with multiple rows (the list of lists) where each row consists of three attributes: Name, Age, and Income. You want to group by Name and store the result in a dictionary. The dictionary keys are given by the Name attribute. The dictionary values are a list of rows that have this exact Name attribute.
Solution: Here’s the data and how you can group by a common attribute (e.g., Name).
# Database:
# row = [Name, Age, Income]
rows = [['Alice', 19, 45000],
['Bob', 18, 22000],
['Ann', 26, 88000],
['Alice', 33, 118000]]
# Create a dictionary grouped by Name
d = {}
for row in rows:
# Add name to dict if not exists
if row[0] not in d:
d[row[0]] = []
# Add all non-Name attributes as a new list
d[row[0]].append(row[1:])
print(d)
# {'Alice': [[19, 45000], [33, 118000]],
# 'Bob': [[18, 22000]],
# 'Ann': [[26, 88000]]}You can see that the result is a dictionary with one key per name ('Alice', 'Bob', and 'Ann'). Alice appears in two rows of the original database (list of lists). Thus, you associate two rows to her name—maintaining only the Age and Income attributes per row.
The strategy how you accomplish this is simple:
- Create the empty dictionary.
- Go over each row in the list of lists. The first value of the row list is the Name attribute.
- Add the Name attribute
row[0]to the dictionary if it doesn’t exist, yet—initializing the dictionary to the empty list. Now, you can be sure that the key exist in the dictionary. - Append the sublist slice
[Age, Income]to the dictionary value so that this becomes a list of lists as well—one list per database row. - You’ve now grouped all database entries by a common attribute (=Name).
So far, so good. But what if you want to perform some aggregation on the grouped database rows? Read my detailed article on the Finxter blog to master this!
Summary
Congratulations! This in-depth tutorial has shown you everything you need to know to handle Python list of lists (nested lists). It’s important to see that Python list of lists work just like Python lists with other objects. The creators of Python made sure that lists of lists follow the same rules as all other list of objects. This is true for sorting, copying, the max function, or slicing—the inner list objects are just that: objects.
More Finxter Tutorials
Learning is a continuous process and you’d be wise to never stop learning and improving throughout your life. 👑
What to learn? Your subconsciousness often knows better than your conscious mind what skills you need to reach the next level of success.
I recommend you read at least one tutorial per day (only 5 minutes per tutorial is enough) to make sure you never stop learning!
💡 If you want to make sure you don’t forget your habit, feel free to join our free email academy for weekly fresh tutorials and learning reminders in your INBOX.
Also, skim the following list of tutorials and open 3 interesting ones in a new browser tab to start your new — or continue with your existing — learning habit today! 🚀
Python Basics:
- Python One Line For Loop
- Import Modules From Another Folder
- Determine Type of Python Object
- Convert String List to Int List
- Convert Int List to String List
- Convert String List to Float List
- Convert List to NumPy Array
- Append Data to JSON File
- Filter List Python
- Nested List
Python Dependency Management:
- Install PIP
- How to Check Your Python Version
- Check Pandas Version in Script
- Check Python Version Jupyter
- Check Version of Package PIP
Python Debugging:
Fun Stuff:
- 5 Cheat Sheets Every Python Coder Needs to Own
- 10 Best Python Puzzles to Discover Your True Skill Level
- How to $1000 on the Side as a Python Freelancer
Thanks for learning with Finxter!
Programming Humor – Python

Where to Go From Here?
Enough theory. Let’s get some practice!
Coders get paid six figures and more because they can solve problems more effectively using machine intelligence and automation.
To become more successful in coding, solve more real problems for real people. That’s how you polish the skills you really need in practice. After all, what’s the use of learning theory that nobody ever needs?
You build high-value coding skills by working on practical coding projects!
Do you want to stop learning with toy projects and focus on practical code projects that earn you money and solve real problems for people?
🚀 If your answer is YES!, consider becoming a Python freelance developer! It’s the best way of approaching the task of improving your Python skills—even if you are a complete beginner.
If you just want to learn about the freelancing opportunity, feel free to watch my free webinar “How to Build Your High-Income Skill Python” and learn how I grew my coding business online and how you can, too—from the comfort of your own home.