
[Spoiler] Which function filters a list faster: filter() vs list comprehension? For large lists with one million elements, filtering lists with list comprehension is 40% faster than the built-in filter() method.
To answer this question, I’ve written a short script that tests the runtime performance of filtering large lists of increasing sizes using the filter() and the list comprehension methods.
My thesis is that the list comprehension method should be slightly faster for larger list sizes because it leverages the efficient cPython implementation of list comprehension and doesn’t need to call an extra function.
Related Article:
I used my notebook with an Intel(R) Core(TM) i7-8565U 1.8GHz processor (with Turbo Boost up to 4.6 GHz) and 8 GB of RAM.
Try It Yourself:
import time
# Compare runtime of both methods
list_sizes = [i * 10000 for i in range(100)]
filter_runtimes = []
list_comp_runtimes = []
for size in list_sizes:
lst = list(range(size))
# Get time stamps
time_0 = time.time()
list(filter(lambda x: x%2, lst))
time_1 = time.time()
[x for x in lst if x%2]
time_2 = time.time()
# Calculate runtimes
filter_runtimes.append((size, time_1 - time_0))
list_comp_runtimes.append((size, time_2 - time_1))
# Plot everything
import matplotlib.pyplot as plt
import numpy as np
f_r = np.array(filter_runtimes)
l_r = np.array(list_comp_runtimes)
print(filter_runtimes)
print(list_comp_runtimes)
plt.plot(f_r[:,0], f_r[:,1], label='filter()')
plt.plot(l_r[:,0], l_r[:,1], label='list comprehension')
plt.xlabel('list size')
plt.ylabel('runtime (seconds)')
plt.legend()
plt.savefig('filter_list_comp.jpg')
plt.show()
The code compares the runtimes of the filter() function and the list comprehension variant to filter a list. Note that the filter() function returns a filter object, so you need to convert it to a list using the list() constructor.
Here’s the resulting plot that compares the runtime of the two methods. On the x axis, you can see the list size from 0 to 1,000,000 elements. On the y axis, you can see the runtime in seconds needed to execute the respective functions.
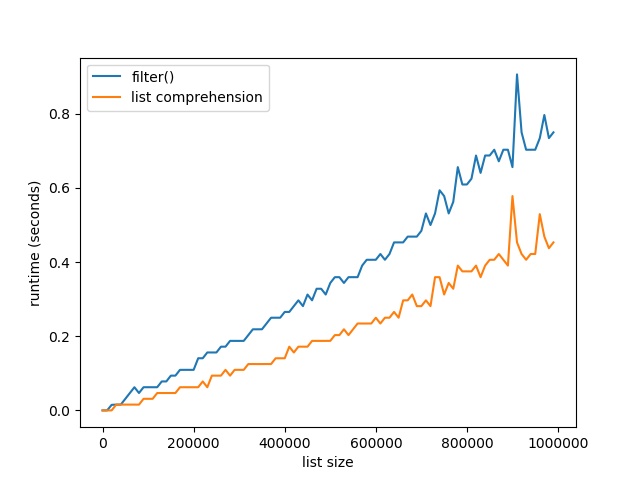
The resulting plot shows that both methods are extremely fast for a few tens of thousands of elements. In fact, they are so fast that the time() function of the time module cannot capture the elapsed time.
But as you increase the size of the lists to hundreds of thousands of elements, the list comprehension method starts to win:
For large lists with one million elements, filtering lists with list comprehension is 40% faster than the built-in filter() method.
The reason is the efficient implementation of the list comprehension statement. An interesting observation is the following though. If you don’t convert the filter function to a list, you get the following result:

Suddenly the filter() function has constant runtime of close to 0 seconds—no matter how many elements are in the list. Why is this happening?
The explanation is simple: the filter function returns an iterator, not a list. The iterator doesn’t need to compute a single element until it is requested to compute the next() element. So, the filter() function computes the next element only if it is required to do so. Only if you convert it to a list, it must compute all values. Otherwise, it doesn’t actually compute a single value beforehand.
Where to Go From Here
This tutorial has shown you the filter() function in Python and compared it against the list comprehension way of filtering: [x for x in list if condition]. You’ve seen that the latter is not only more readable and more Pythonic, but also faster. So take the list comprehension approach to filter lists!
If you love coding and you want to do this full-time from the comfort of your own home, you’re in luck:
I’ve created a free webinar that shows you how I started as a Python freelancer after my computer science studies working from home (and seeing my kids grow up) while earning a full-time income working only part-time hours.
Webinar: How to Become Six-Figure Python Freelancer?
Join 21,419 ambitious Python coders. It’s fun! ??