

The most important collection data type in Python is the list data type. You’ll use lists basically in all your future projects. So take your time and invest a good hour or so to study this guide carefully.
Overview — Creating a List in Python
There are many ways of creating a list in Python. Let’s get a quick overview in the following table:
| Code | Description |
|---|---|
[] | Square bracket: Initializes an empty list with zero elements. You can add elements later. |
[x1, x2, x3, … ] | List display: Initializes an empty list with elements x1, x2, x3, … For example, [1, 2, 3] creates a list with three integers 1, 2, and 3. |
[expr1, expr2, ... ] | List display with expressions: Initializes a list with the result of the expressions expr1, expr2, … For example, [1+1, 2-1] creates the list [2, 1]. |
[expr for var in iter] | List comprehension: applies the expression expr to each element in an iterable. |
list(iterable) | List constructor that takes an iterable as input and returns a new list. |
You can play with some examples in our interactive Python shell:
Exercise: Use list comprehension to create a list of square numbers.
Python List Methods
| Method | Description |
|---|---|
lst.append(x) | Appends element x to the list lst. |
| Removes all elements from the list lst–which becomes empty. |
lst.copy() | Returns a copy of the list lst. Copies only the list, not the elements in the list (shallow copy). |
lst.count(x) | Counts the number of occurrences of element x in the list lst. |
lst.extend(iter) | Adds all elements of an iterable iter(e.g. another list) to the list lst. |
lst.index(x) | Returns the position (index) of the first occurrence of value x in the list lst. |
lst.insert(i, x) | Inserts element x at position (index) i in the list lst. |
lst.pop() | Removes and returns the final element of the list lst. |
lst.remove(x) | Removes and returns the first occurrence of element x in the list lst. |
lst.reverse() | Reverses the order of elements in the list lst. |
lst.sort() | Sorts the elements in the list lst in ascending order. |
Go ahead and try the Python list methods yourself:
Puzzle: Can you figure out all outputs of this interactive Python script?
Here’s your free PDF cheat sheet showing you all Python list methods on one simple page. Click the image to download the high-resolution PDF file, print it, and post it to your office wall:
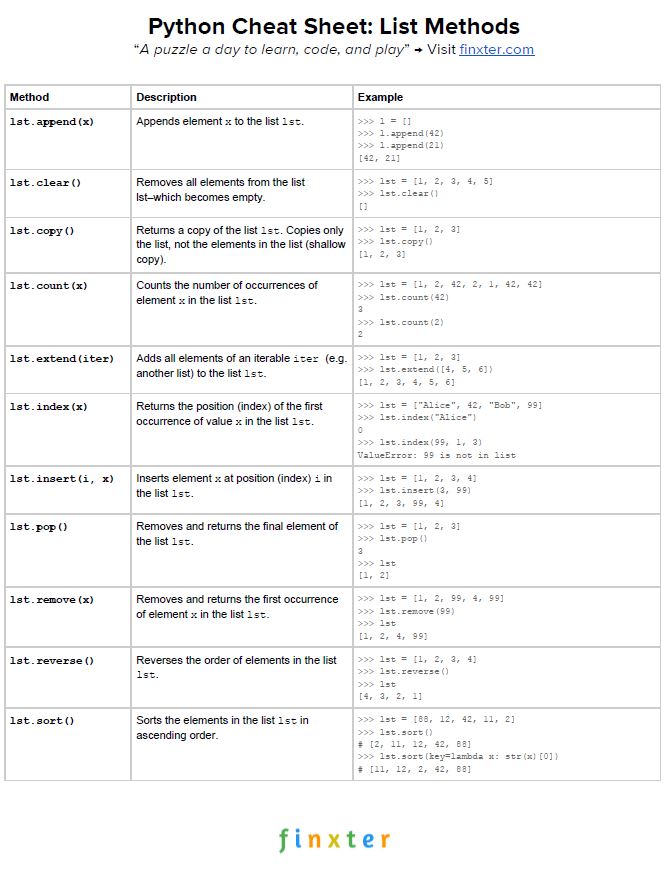
If you’ve studied the table carefully, you’ll know the most important list methods in Python. Let’s have a look at some examples of above methods:
>>> l = [] >>> l.append(2) >>> l [2] >>> l.clear() >>> l [] >>> l.append(2) >>> l [2] >>> l.copy() [2] >>> l.count(2) 1 >>> l.extend([2,3,4]) >>> l [2, 2, 3, 4] >>> l.index(3) 2 >>> l.insert(2, 99) >>> l [2, 2, 99, 3, 4] >>> l.pop() 4 >>> l.remove(2) >>> l [2, 99, 3] >>> l.reverse() >>> l [3, 99, 2] >>> l.sort() >>> l [2, 3, 99]
Action Steps:
- Master Python Sets (with Harry Potter Examples)
- Master Python Dictionaries (the ultimate blog tutorial)
- Join my free email computer science academy for continuous improvement in Python
What’s the Runtime Complexity of Other Python List Methods?
Here’s the table based on the official Python wiki:
| Operation | Average Case | Amortized Worst Case |
| copy() | O(n) | O(n) |
| append() | O(1) | O(1) |
| pop() | O(1) | O(1) |
| pop(i) | O(k) | O(k) |
| insert() | O(n) | O(n) |
| list[i] | O(1) | O(1) |
| list[i] = x | O(1) | O(1) |
| remove(x) | O(n) | O(n) |
| for i in list | O(n) | O(n) |
| list[i:j] | O(k) | O(k) |
| del list[i:j] | O(n) | O(n) |
| list[i:j] = y | O(k+n) | O(k+n) |
| extend() | O(k) | O(k) |
| sort() | O(n log n) | O(n log n) |
| […] * 10 | O(nk) | O(nk) |
x in lst | O(n) | |
| min(lst), max(lst) | O(n) | |
| len(lst) | O(1) | O(1) |
The Python list is implemented using a C++ array. This means that it’s generally slow to modify elements at the beginning of each list because all elements have to be shifted to the right. If you add an element to the end of a list, it’s usually fast. However, resizing an array can become slow from time to time if more memory has to be allocated for the array.
Python Slicing Lists
Slicing is a Python-specific concept for carving out a range of values from sequence types such as lists or strings.
Try It Yourself:
Slicing is one of the most popular Python features. To master Python, you must master slicing first. Any non-trivial Python code base relies on slicing. In other words, the time you invest now in mastering slicing will be repaid a hundredfold during your career.
Here’s a 10-min video version of this article–that shows you everything you need to know about slicing:
[Intermezzo] Indexing Basics
To bring everybody on the same page, let me quickly explain indices in Python by example. Suppose, we have a string ‘universe’. The indices are simply the positions of the characters of this string.
| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Character | u | n | i | v | e | r | s | e |
The first character has index 0, the second character has index 1, and the i-th character has index i-1.
Quick Introduction Slicing
The idea of slicing is simple. You carve out a subsequence from a sequence by defining the start and end indices. But while indexing retrieves only a single character, slicing retrieves a whole substring within an index range.
Use the bracket notation for slicing with the start and end position identifiers. For example, word[i:j] returns the substring starting from index i (included) and ending in index j (excluded). Forgetting that the end index is excluded is a common source of bugs.
You can also skip the position identifier before or after the slicing colon. This indicates that the slice starts from the first or last position, respectively. For example, word[:i] + word[i:] returns the same string as word.
Python puzzle 1: What is the output of this code snippet?
x = 'universe' print(x[2:4])
The Step Size in Slicing
For the sake of completeness, let me quickly explain the advanced slicing notation [start:end:step]. The only difference to the previous notation is that it allows you to specify the step size as well. For example, the command 'python'[:5:2] returns every second character up to the fourth character, i.e., the string 'pto'.
Python puzzle 2: What is the output of this code snippet?
x = 'universe' print(x[2::2])
Overshooting Indices in Slicing
Slicing is robust even if the end index shoots over the maximal sequence index. Just remember that nothing unexpected happens if slicing overshoots sequence indices. Here is an example.
word = "galaxy" print(word[4:50])
Summary Python Slicing
Short recap, the slice notation s[start:end:step] carves out a substring from s. The substring consists of all characters between the two characters at the start index (inclusive) and the end index (exclusive). An optional step size indicates how many characters are left out from the original sequence. Here is an example:
s = 'sunshine' print(s[1:5:2]) #'us' print(s[1:5:1]) #'unsh'
Ok, so let’s train slicing a little bit. Solve the following puzzle in your head (and check the solution below).
Python Puzzle 3: What is the output of this code snippet?
# (Shakespeare) s = "All that glitters is not gold" print(s[9:-9]) print(s[::10]) print(s[:-4:-1])
Let’s go a bit deeper into slicing to make sure that you are getting it 100%.
I have searched Quora to find all the little problems new Python coders are facing with slicing. I will answer six common questions next.
1) How to skip slicing indices (e.g. s[::2])?
The Python interpreter assumes certain default values for s[start:stop:step]. They are: start=0, stop=len(s), and step=1 (in the slice notation: s[::]==s[0:len(s):1]).
2) When to use the single colon notation (e.g. s[:]) and when double colon notation (e.g. s[::2])?
A single colon (e.g. s[1:2]) allows for two arguments, the start and the end index. A double colon (e.g. s[1:2:2]) allows for three arguments, the start index, the end index, and the step size. If the step size is set to the default value 1, we can use the single colon notation for brevity.
3) What does a negative step size mean (e.g. s[5:1:-1])?
This is an interesting feature in Python. A negative step size indicates that we are not slicing from left to right, but from right to left. Hence, the start index should be larger or equal than the end index (otherwise, the resulting sequence is empty).
4) What are the default indices when using a negative step size (e.g. s[::-1])?
In this case, the default indices are not start=0 and end=len(s) but the other way round: start=len(s)-1 and end=-1. Note that the start index is still included and the end index still excluded from the slice. Because of that, the default end index is -1 and not 0.
5) We have seen many examples for string slicing. How does list slicing work?
Slicing works the same for all sequence types. For lists, consider the following example:
l = [1, 2, 3, 4] print(l[2:]) # [3, 4]
Slicing tuples works in a similar way.
6) Why is the last index excluded from the slice?
The last index is excluded because of two reasons. The first reason is language consistency, e.g. the range function also does not include the end index. The second reason is clarity, e.g., here’s an example why it makes sense to exclude the end index from the slice.
customer_name = 'Hubert' k = 3 # maximal size of database entry x = 1 # offset db_name = customer_name[x:x+k]
Now suppose the end index would be included. In this case, the total length of the db_name substring would be k + 1 characters. This would be very counter-intuitive.
Let’s learn about all the Python list methods, starting with one of the most important ones.
Python List append()
How can you add more elements to a given list? Use the append() method in Python. This tutorial shows you everything you need to know to help you master an essential method of the most fundamental container data type in the Python programming language.
Definition and Usage
The list.append(x) method—as the name suggests—appends element x to the end of the list.
Here’s a short example:
>>> l = [] >>> l.append(42) >>> l [42] >>> l.append(21) >>> l [42, 21]
In the first line of the example, you create the list l. You then append the integer element 42 to the end of the list. The result is the list with one element [42]. Finally, you append the integer element 21 to the end of that list which results in the list with two elements [42, 21].
Syntax
You can call this method on each list object in Python. Here’s the syntax:
list.append(element)
Arguments
| Argument | Description |
|---|---|
element | The object you want to append to the list. |
Code Puzzle
Now you know the basics. Let’s deepen your understanding with a short code puzzle—can you solve it?
# Puzzle nums = [1, 2, 3] nums.append(nums[:]) print(len(nums)) # What's the output of this code snippet?
You can check out the solution on the Finxter app. (I know it’s tricky!)
Examples
Let’s dive into a few more examples:
>>> lst = [2, 3] >>> lst.append(3) >>> lst.append([1,2]) >>> lst.append((3,4)) >>> lst [2, 3, 3, [1, 2], (3, 4)]
You can see that the append() method also allows for other objects. But be careful: you cannot append multiple elements in one method call. This will only add one new element (even if this new element is a list by itself). Instead, to add multiple elements to your list, you need to call the append() method multiple times.
Python List append() At The Beginning
What if you want to use the append() method at the beginning: you want to “append” an element just before the first element of the list.
Well, you should work on your terminology for starters. But if you insist, you can use the insert() method instead.
Here’s an example:
>>> lst = [1, 2, 3] >>> lst.insert(0, 99) >>> lst [99, 1, 2, 3]
The insert(i, x) method inserts an element x at position i in the list. This way, you can insert an element to each position in the list—even at the first position. Note that if you insert an element at the first position, each subsequent element will be moved by one position. In other words, element i will move to position i+1.
Python List append() Multiple or All Elements
But what if you want to append not one but multiple elements? Or even all elements of a given iterable. Can you do it with append()? Well, let’s try:
>>> l = [1, 2, 3] >>> l.append([4, 5, 6]) >>> l [1, 2, 3, [4, 5, 6]]
The answer is no—you cannot append multiple elements to a list by using the append() method. But you can use another method: the extend() method:
>>> l = [1, 2, 3] >>> l.extend([1, 2, 3]) >>> l [1, 2, 3, 1, 2, 3]
You call the extend() method on a list object. It takes an iterable as an input argument. Then, it adds all elements of the iterable to the list, in the order of their occurrence.
Python List append() vs extend()
I shot a small video explaining the difference and which method is faster, too:
The method list.append(x) adds element x to the end of the list.
The method list.extend(iter) adds all elements in iter to the end of the list.
The difference between append() and extend() is that the former adds only one element and the latter adds a collection of elements to the list.
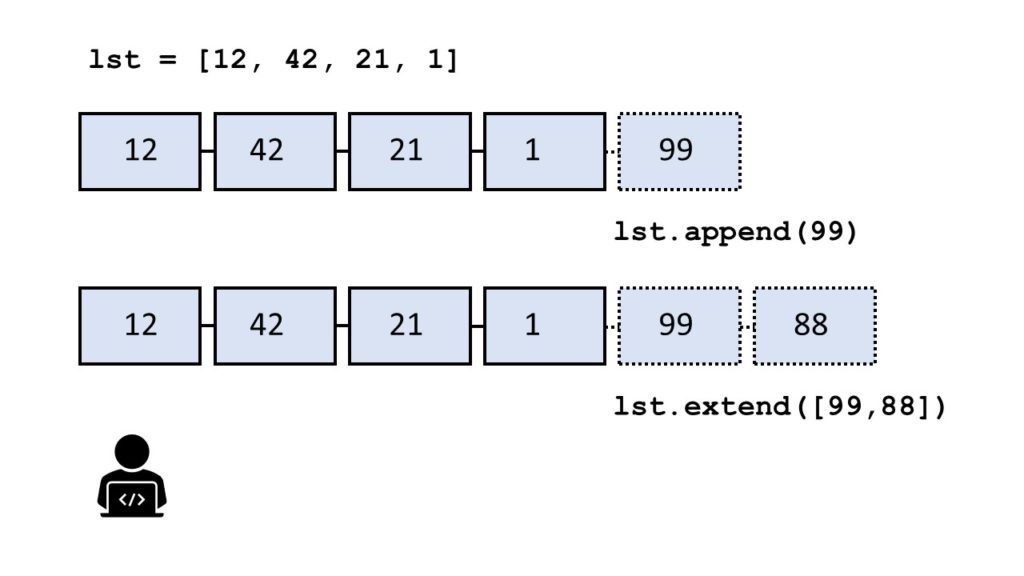
You can see this in the following example:
>>> l = [] >>> l.append(1) >>> l.append(2) >>> l [1, 2] >>> l.extend([3, 4, 5]) >>> l [1, 2, 3, 4, 5]
In the code, you first add integer elements 1 and 2 to the list using two calls to the append() method. Then, you use the extend method to add the three elements 3, 4, and 5 in a single call of the extend() method.
Which method is faster — extend() vs append()?
To answer this question, I’ve written a short script that tests the runtime performance of creating large lists of increasing sizes using the extend() and the append() methods.
Our thesis is that the extend() method should be faster for larger list sizes because Python can append elements to a list in a batch rather than by calling the same method again and again.
I used my notebook with an Intel(R) Core(TM) i7-8565U 1.8GHz processor (with Turbo Boost up to 4.6 GHz) and 8 GB of RAM.
Then, I created 100 lists with both methods, extend() and append(), with sizes ranging from 10,000 elements to 1,000,000 elements. As elements, I simply incremented integer numbers by one starting from 0.
Here’s the code I used to measure and plot the results: which method is faster—append() or extend()?
import time
def list_by_append(n):
'''Creates a list & appends n elements'''
lst = []
for i in range(n):
lst.append(n)
return lst
def list_by_extend(n):
'''Creates a list & extends it with n elements'''
lst = []
lst.extend(range(n))
return lst
# Compare runtime of both methods
list_sizes = [i * 10000 for i in range(100)]
append_runtimes = []
extend_runtimes = []
for size in list_sizes:
# Get time stamps
time_0 = time.time()
list_by_append(size)
time_1 = time.time()
list_by_extend(size)
time_2 = time.time()
# Calculate runtimes
append_runtimes.append((size, time_1 - time_0))
extend_runtimes.append((size, time_2 - time_1))
# Plot everything
import matplotlib.pyplot as plt
import numpy as np
append_runtimes = np.array(append_runtimes)
extend_runtimes = np.array(extend_runtimes)
print(append_runtimes)
print(extend_runtimes)
plt.plot(append_runtimes[:,0], append_runtimes[:,1], label='append()')
plt.plot(extend_runtimes[:,0], extend_runtimes[:,1], label='extend()')
plt.xlabel('list size')
plt.ylabel('runtime (seconds)')
plt.legend()
plt.savefig('append_vs_extend.jpg')
plt.show()The code consists of three high-level parts:
- In the first part of the code, you define two functions
list_by_append(n)andlist_by_extend(n)that take as input argument an integer list sizenand create lists of successively increasing integer elements using theappend()andextend()methods, respectively. - In the second part of the code, you compare the runtime of both functions using 100 different values for the list size
n. - In the third part of the code, you plot everything using the Python matplotlib library.
Here’s the resulting plot that compares the runtime of the two methods append() vs extend(). On the x axis, you can see the list size from 0 to 1,000,000 elements. On the y axis, you can see the runtime in seconds needed to execute the respective functions.

The resulting plot shows that both methods are extremely fast for a few tens of thousands of elements. In fact, they are so fast that the time() function of the time module cannot capture the elapsed time.
But as you increase the size of the lists to hundreds of thousands of elements, the extend() method starts to win:
For large lists with one million elements, the runtime of the extend() method is 60% faster than the runtime of the append() method.
The reason is the already mentioned batching of individual append operations.
However, the effect only plays out for very large lists. For small lists, you can choose either method. Well, for clarity of your code, it would still make sense to prefer extend() over append() if you need to add a bunch of elements rather than only a single element.
Python List append() vs insert()
The difference between the append() and the insert() method is the following:
- the
append(x)method adds new elementxto the end of the list, and - the
insert(i, x)method adds new elementxat positioniin the list. It shifts all subsequent elements one position to the right.
Here’s an example showing both append() and insert() methods in action:
>>> l = [1, 2, 3] >>> l.append(99) >>> l [1, 2, 3, 99] >>> l.insert(2, 42) >>> l [1, 2, 42, 3, 99]
Both methods help you add new elements to the list. But you may ask:
Which is faster, append() or insert()?
All things being equal, the append() method is significantly faster than the insert() method.
Here’s a small script that shows that the append() method has a huge performance advantage over the insert() method when creating a list with 100,000 elements.
import time
l1 = []
l2 = []
t1 = time.time()
for i in range(100000):
l1.append(i)
t2 = time.time()
for i in range(100000):
l2.insert(0,i)
t3 = time.time()
print("append(): " + str(t2 - t1) + " seconds")
print("insert(): " + str(t3 - t2) + " seconds")
# OUTPUT:
# append(): 0.015607357025146484 seconds
# insert(): 1.5420396327972412 secondsThe experiments were performed on my notebook with an Intel(R) Core(TM) i7-8565U 1.8GHz processor (with Turbo Boost up to 4.6 GHz) and 8 GB of RAM.
Python List append() vs concatenate
So you have two or more lists and you want to glue them together. This is called list concatenation. How can you do that?
These are six ways of concatenating lists (detailed tutorial here):
- List concatenation operator
+ - List
append()method - List
extend()method - Asterisk operator
* Itertools.chain()- List comprehension
a = [1, 2, 3]
b = [4, 5, 6]
# 1. List concatenation operator +
l_1 = a + b
# 2. List append() method
l_2 = []
for el in a:
l_2.append(el)
for el in b:
l_2.append(el)
# 3. List extend() method
l_3 = []
l_3.extend(a)
l_3.extend(b)
# 4. Asterisk operator *
l_4 = [*a, *b]
# 5. Itertools.chain()
import itertools
l_5 = list(itertools.chain(a, b))
# 6. List comprehension
l_6 = [el for lst in (a, b) for el in lst]Output:
''' l_1 --> [1, 2, 3, 4, 5, 6] l_2 --> [1, 2, 3, 4, 5, 6] l_3 --> [1, 2, 3, 4, 5, 6] l_4 --> [1, 2, 3, 4, 5, 6] l_5 --> [1, 2, 3, 4, 5, 6] l_6 --> [1, 2, 3, 4, 5, 6] '''
What’s the best way to concatenate two lists?
If you’re busy, you may want to know the best answer immediately. Here it is:
To concatenate two lists l1, l2, use the l1.extend(l2) method which is the fastest and the most readable.
To concatenate more than two lists, use the unpacking (asterisk) operator [*l1, *l2, ..., *ln].
However, you should avoid using the append() method for list concatenation because it’s neither very efficient nor concise and readable.
Python List append() If Not Exists
A common question is the following:
How can you add or append an element to a list, but only if it doesn’t already exist in the list?
When ignoring any performance issues, the answer is simple: use an if condition in combination with the membership operation element in list and only append() the element if the result is False. As an alternative, you can also use the negative membership operation element not in list and add the element if the result is True.
Example: Say, you want to add all elements between 0 and 9 to a list of three elements. But you don’t want any duplicates. Here’s how you can do this:
lst = [1, 2, 3]
for element in range(10):
if element not in lst:
lst.append(element) Resulting list:
[1, 2, 3, 0, 4, 5, 6, 7, 8, 9]
You add all elements between 0 and 9 to the list but only if they aren’t already present. Thus, the resulting list doesn’t contain duplicates.
But there’s a problem: this method is highly inefficient!
In each loop iteration, the snippet element not in lst searches the whole list for the current element. For a list with n elements, this results in n comparisons, per iteration. As you have n iterations, the runtime complexity of this code snippet is quadratic in the number of elements.
Can you do better?
Sure, but you need to look beyond the list data type: Python sets are the right abstraction here. If you need to refresh your basic understanding of the set data type, check out my detailed set tutorial (with Harry Potter examples) on the Finxter blog.
Why are Python sets great for this? Because they don’t allow any duplicates per design: a set is a unique collection of unordered elements. And the runtime complexity of the membership operation is not linear in the number of elements (as it’s the case for lists) but constant!
Example: Say, you want to add all elements between 0 and 9 to a set of three elements. But you don’t want any duplicates. Here’s how you can do this with sets:
s = {1, 2, 3}
for element in range(10):
s.add(element)
print(s)
Resulting set:
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}The set doesn’t allow for duplicate entries so the elements 1, 2, and 3 are not added twice to the set.
You can even make this code more concise:
s = {1, 2, 3}
s = s.union(range(10))
print(s)Output:
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}The union method creates a new set that consists of all elements in both operands.
Now, you may want to have a list as a result and not a set. The solution is simple: convert the resulting set to a list by using the list(set) conversion method. This has linear runtime complexity and if you call it only once, it doesn’t change the overall runtime complexity of the code snippet (it remains linear in the number of set elements).
Problem: what if you want to maintain the order information and still add all elements that are not already in the list?
The problem with the previous approach is that by converting the list to a set, the order of the list is lost. In this case, I’d advise you to do the following: use two data structures, a list and a set. You use the list to add new elements and keep the order information. You use the set to check membership (constant rather than linear runtime complexity). Here’s the code:
lst = [1, 2, 3]
s = set(lst)
for element in range(10):
if element not in s:
s.add(element)
lst.append(element)
print(lst)Resulting list:
[1, 2, 3, 0, 4, 5, 6, 7, 8, 9]
You can see that the resulting list doesn’t contain any duplicates but the order information is maintained. At the same time, the runtime complexity of the code is linear because each loop iteration can be completed in constant time.
The trade-off is that you have to maintain two data structures which results in double the memory overhead. This nicely demonstrates the common inverse relationship between memory and runtime overhead.
Python List append() Return New List
If you use the lst.append(element) operation, you add the element to the existing list lst. But what if you want to create a new list where the element was added?
The answer is simply to use the list concatenation operation lst + [element] which creates a new list each time it is used. The original list lst will not be affected by the list concatenation operation.
Here’s an example that shows that the append() method only modifies an existing list:
>>> lst_1 = [1, 2, 3] >>> lst_2 = lst_1.append(4) >>> lst_1 [1, 2, 3, 4]
And here’s the example that shows how to create a new list as you add a new element 4 to a list:
>>> lst_3 = [1, 2, 3] >>> lst_4 = lst_3 + [4] >>> lst_3 [1, 2, 3]
By using the list concatenation operation, you can create a new list rather than appending the element to an existing list.
Python List append() Time Complexity, Memory, and Efficiency
Time Complexity: The append() method has constant time complexity O(1). Adding one element to the list requires only a constant number of operations—no matter the size of the list.
Space Complexity: The append() method has constant space complexity O(1). The operation itself needs only a constant number of bytes for the involved temporary variables. The memory overhead does not depend on the size of the list. Note that the list itself does have linear space complexity: you need O(n) bytes to represent n elements in the list.
Efficiency Considerations: The append() method is as efficient as possible. In terms of the asymptotic behavior of the time complexity, there’s no way to improve upon the append() method—even if you’d use other data structures such as sets or binary trees. However, if you need to add multiple elements to the list, you can get some constant factor improvements by using the extend() method rather than the append() method. The former takes an iterable as an argument so you can add many elements at once in a single batch. This is more efficient and can lead to 50% performance improvements in practical settings. If you’re interested in the most performant ways to add multiple elements to a list, you can see extensive performance tests in this tutorial on the Finxter blog.
Python List append() at Index
Do you want to append an element at a certain position? This is called insertion and you can do it with the list.insert(i, x) method that inserts element x at position i of the list. All subsequent elements will be shifted to the right (their index increases by one). The time complexity of the insert() method is O(1).
Here’s an example:
>>> lst = [99, 42, 101] >>> lst.insert(2, 7) >>> lst [99, 42, 7, 101]
The code inserts element 7 at position 2 of the list. Element 101 previously held position 2 so it now holds position 3.
If you want to insert an element and create a new list by doing so, I’d recommend to use Python slicing. Check out this in-depth blog tutorial that’ll show you everything you need to know about slicing. You can also get your free slicing book “Coffee Break Python Slicing”.
Here’s the code that shows how to create a new list after inserting an element at a certain position:
>>> lst = [33, 44, 55] >>> lst[:2] + [99] + lst[2:] [33, 44, 99, 55]
Again, you’re using list concatenation to create a new list with element 99 inserted at position 2. Note that the slicing operations lst[:2] and lst[2:] create their own shallow copy of the list.
Python List append() Error
Actually, there isn’t a lot of things you can do wrong by using the append() method.
1) One common error happens when you assume that the append() method creates a new list. This is not the case: there’s no return value for the append() method. It simply appends an element to an existing list.
2) Another error can happen if you try to append an element to a list but the list is not yet created. Of course, you can only call the method if you properly initialized the list object.
3) Yet another error happens if you try to use the append() method with too many arguments. The append() method takes only one argument: the element to be appended. If you add another argument (like the position on which you’d like to append the element), you’ll get an error. Other methods such as the insert() method can handle more arguments such as the position to add an element.
Python List append() Empty Element
Do you want to add an empty element to a list to get something like this: [4, 5, , 7]? I saw this in a StackOverflow question when researching this article.
Anyways, the most natural way of accomplish this is to use the None element that exists for exactly this purpose.
Here’s an example:
>>> lst = [4, 5] >>> lst.append(None) >>> lst.append(7) >>> lst [4, 5, None, 7]
For comprehensibility, I have to say that it’s not possible to add an empty element to a list, simply because of the fact that there’s no such thing as an empty element in Python.
Python List append() Sorted
How to insert an element into a sorted list? Well, you shouldn’t use append() in the first place because the append operation cannot insert an element at the correct position. It only appends the element to the end of the list.
Instead, you can use binary search and the list.insert(i,x) method to insert element x at position i in the list. Here’s the code for the binary search algorithm in Python:
def binary_search(lst, value):
lo, hi = 0, len(lst)-1
while lo <= hi:
mid = (lo + hi) // 2
if lst[mid] < value:
lo = mid + 1
elif value < lst[mid]:
hi = mid - 1
else:
return mid
return -1
l = [3, 6, 14, 16, 33, 55, 56, 89]
x = 56
print(binary_search(l,x))
# 6 (the index of the found element)Python List append() Dictionary
These are the different interpretations of using the append() method with a dictionary:
- Append a dictionary to a list.
- Append all key value pairs from a dictionary to a list.
- Append an element to a list stored in a dictionary.
- Add/Append a key value pair to a dictionary.
Let’s explore them one by one:
Append a dictionary to a list. A dictionary is a Python object. So you can simply add it to a list like you would any other element:
>>> dic = {"hello": 0, "world":1}
>>> lst = [1, 2, 3]
>>> lst.append(dic)
>>> lst
[1, 2, 3, {'hello': 0, 'world': 1}]The fourth list element is the dictionary itself.
Append all key value pairs from a dictionary to a list. Say, you’ve got a dictionary with (key, value) pairs. How can you add all of them to a given list? The answer is simple: use the extend() method with the dictionary method items().
>>> income = {"Alice": 100000, "Bob": 44000}
>>> lst = [("Carl", 22000)]
>>> lst.extend(income.items())
>>> lst
[('Carl', 22000), ('Alice', 100000), ('Bob', 44000)]The items() method returns all key value pairs as tuples. You can master Python dictionaries by following my visual, ultimate guide on this blog.
Append an element to a list stored in a dictionary. This one is easy: retrieve the list and call the append() method on it. Here’s how:
>>> teams = {"A" : ["Alice", "Anna"], "B" : ["Bob", "Bernd"]}
>>> teams["A"].append("Atilla")
>>> teams["A"]
['Alice', 'Anna', 'Atilla']As the list is an object, modifying this object (even if it’s “outside” the dictionary) will affect the object stored in the dictionary itself.
Add/append a key value pair to a dictionary. How can you add a (key, value) pair to a dictionary? Simply use the operation dic[key] = value.
Python List append() For Loop One Line
You’re looking for a one-line for loop to add elements to a list? This is called list comprehension and I’ve written a detailed article about it on this blog.
Here’s the quick example to add all elements from 0 to 9 to a list:
>>> [i for i in range(10)] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Summary
The list.append(x) method adds element x to the end of the list.
Python List clear()
Surprisingly, even advanced Python coders don’t know about the clear() method of Python lists. Time to change that!
Definition and Usage: The list.clear() method removes all elements from an existing list. The list becomes empty again.
Here’s a short example:
>>> lst = [1, 2, 3, 4, 5] >>> lst.clear() >>> lst []
In the first line, you create the list lst consisting of five integers. You then remove all elements from the list. The result is the empty list.
Puzzle – Try It Yourself:
Syntax: You can call this method on each list object in Python. Here’s the syntax:
list.clear()
Arguments: The method doesn’t take any argument.
Return value: The method list.clear() has return value None. It operates on an existing list and, therefore, doesn’t return a new list with the removed element
Video:
Python List clear() vs New List
Now, if you’re an alert reader, you may ask the following interesting question: why to use the clear() method in the first place when you also can simply create a new list and be done with it?
Here’s an example where both ways lead to the same result:
>>> lst = [1, 2, 3] >>> lst.clear() >>> lst [] >>> lst = [1, 2, 3] >>> lst = [] >>> lst []
I know the code seems to be a bit odd but it shows that instead of clearing an existing list, you can also create a new list. In this case, this leads to the exact same result.
However, Python is an object-oriented language. And if you just create a new object and assign it to a variable, the original list still exists in memory. And other variables may point to the object.
Consider the following code snippet that exemplifies this:
lst = [1, 2, 3] lst_2 = lst lst = [] print(lst_2) # [1, 2, 3]
I’ve created a Python visualization for you so that you can see the objects in memory:
Simply assigning a new list to the variable lst will leave the other variable lst_2 unaffected. Instead, you should have used lst.clear() to make sure that both variables now point to the same empty list object.
lst = [1, 2, 3] lst_2 = lst lst.clear() print(lst_2) # []
Python List clear() Memory
The effect of the clear() method is that the list is now empty.
In theory, you released the Python virtual machine from the burden of keeping the elements in the memory. Python uses reference counting to determine if some elements in the memory are not referenced anymore (and, thus, can be considered unused). Those elements will be removed—we say, they are deallocated from memory. If you clear the list, you essentially remove all references from the list to the list elements. However, some old list elements may still be referenced from the outside (e.g. by another variable). So they are not necessarily removed because they may still be needed! Just keep this in mind when clearing the list.
In practice, however, even referenced elements may still exist in the memory until the Python garbage collector (or even the operating system) removes the elements from memory.
Python List clear() Complexity
The runtime complexity of list.clear() is O(n) for a list with n elements. Why? Well, you first need to understand what happens if you remove all elements from a list. The list elements are not physically (or, for that matter, digitally) stored in the list. The list contains only references to the real list element objects in memory. If you clear the list, you remove all those references.
The garbage collector in Python goes over all elements in the memory to remove the ones that have a reference count of zero. Why? Because they are the ones that cannot be accessed in the code. Thus, the garbage collector can safely assume that they are unused and are not needed anymore. As you see, the garbage collector needs the reference count information for each element in memory.
The algorithm when clearing a list is simple: reduce the reference count of each list element object by one. The objects that end up with reference count zero can now be removed from memory. But as you need to go over all list elements, the runtime complexity is linear to the list size.
Python List clear() Not Working
The Python list.clear() method was added in Python 3.3 (official source). So if you try to use it for any Python version before that, you must use the del list[:] method that is semantically equivalent and works for earlier Python versions, too.
Related articles on the Finxter blog:
Python List clear() Version 2.7
Have you tried to use Python list.clear() in Python 2.7? It’s not possible. The clear() method was added in Python 3.3 (official source). So if you try to use it for any Python version before that (including 2.7), you must use the del list[:] method that is semantically equivalent and works for earlier Python versions, too.
Related articles on the Finxter blog:
Python List clear() vs del
You may ask: what’s the difference between the list.clear() method and the del operation?
The answer is simple: there isn’t any semantic difference. The list.clear() method is just syntactical sugar for del list[:] (source).
Here’s an example demonstrating that both are, in fact, the same:
>>> lst = [1, 2, 3] >>> lst.clear() >>> lst [] >>> lst = [1, 2, 3] >>> del lst[:] >>> lst []
List Removal Alternatives
There are some alternative list methods to remove elements from the list. See the overview table:
| Method | Description |
|---|---|
lst.remove(x) | Remove an element from the list (by value) |
lst.pop() | Remove an element from the list (by index) and return the element |
lst.clear() | Remove all elements from the list |
del lst[3] | Remove one or more elements from the list (by index or slice) |
| List comprehension | Remove all elements that meet a certain condition |
Python List Clear Duplicates
How to remove all duplicates of a given value in the list?
The naive approach is to go over each element and check whether this element already exists in the list. If so, remove it. However, this takes a few lines of code.
A shorter and more concise way is to create a dictionary out of the elements in the list. Each list element becomes a new key to the dictionary. All elements that occur multiple times will be assigned to the same key. The dictionary contains only unique keys—there cannot be multiple equal keys.
As dictionary values, you simply take dummy values (per default).
Related blog articles:
Then, you simply convert the dictionary back to a list throwing away the dummy values. As the dictionary keys stay in the same order, you don’t lose the order information of the original list elements.
Here’s the code:
>>> lst = [1, 1, 1, 3, 2, 5, 5, 2]
>>> dic = dict.fromkeys(lst)
>>> dic
{1: None, 3: None, 2: None, 5: None}
>>> duplicate_free = list(dic)
>>> duplicate_free
[1, 3, 2, 5]Summary
The list.clear() method removes all elements from the list.
Python List copy()
Surprisingly, even advanced Python coders don’t know the details of the copy() method of Python lists. Time to change that!
Definition and Usage: The list.copy() method copies all list elements into a new list. The new list is the return value of the method. It’s a shallow copy—you copy only the object references to the list elements and not the objects themselves.
Here’s a short example:
>>> lst = [1, 2, 3] >>> lst.copy() [1, 2, 3]
In the first line, you create the list lst consisting of three integers. You then create a new list by copying all elements.
Puzzle – Try It Yourself:
Syntax: You can call this method on each list object in Python. Here’s the syntax:
list.copy()
Arguments: The method doesn’t take any argument.
Return value: The method list.clear() returns a list object by copying references to all objects in the original list.
Video:
Python List Copy Shallow
Before you can truly understand the copy() method in Python, you must understand the concept of a “shallow copy”.
In object-oriented languages such as Python, everything is an object. The list is an object and the elements in the list are objects, too. A shallow copy of the list creates a new list object—the copy—but it doesn’t create new list elements but simply copies the references to these objects.

You can see that the list below is only a shallow copy pointing to the same elements as the original list.
In Python, the list.copy() method only produces a shallow copy which has much faster runtime complexity.
Here’s an example showing exact this scenario:
>>> lst = [6, 7, [1, 2], "hello"] >>> lst_2 = lst.copy() >>> lst_2[2].append(42) >>> lst[2] [1, 2, 42]
Changing the third list element of the copied list impacts the third list element of the original list.
Python List Copy Deep
Having understood the concept of a shallow copy, it’s now easy to understand the concept of a deep copy. A shallow copy only copies the references of the list elements. A deep copy copies the list elements themselves which can lead to a highly recursive behavior because the list elements may be lists themselves that need to be copied deeply and so on.
Here’s a simple deep copy of the same list as shown previously:

In contrast to the shallow copy, the list [1, 2] is copied separately for the deep copy list. If one changes this nested list in the original list, the change would not be visible at the deep copy. (Because the nested list of the deep copy list is an independent object in memory.)
Note that in a deep copy, the string object must not be copied. Why? Because strings are immutable so you cannot change them (and, thus, there will be no dirty “side effects” seen by other copies of the list pointing to the same object in memory.
To get a deep copy in Python, use the copy module and use the deepcopy() method:
>>> import copy >>> lst = [6, 7, [1, 2], "hello"] >>> lst_2 = copy.deepcopy(lst) >>> lst_2[2].append(42) >>> lst[2] [1, 2]
How to Copy a Python List (Alternatives)?
Say, you want to copy the list. What options are there?
| Method | Description |
|---|---|
list.copy() | Returns a shallow copy of the list. |
import copy | Import the copy module and uses its method to create a deep copy of list. |
list[:] | Use slicing with default indices to create a shallow copy of the list. |
list(x) | use the built-in list constructor list(...) to create a shallow copy of the list x. |
[el for el in lst] | Use list comprehension to create a shallow copy of the original list lst. |
Slicing belongs to the fastest methods (very dirty benchmark here). If you need to refresh your Python slicing skills, here’s a tutorial on the Finxter blog:
Related Articles:
Python List Copy Not Working
The main reason why the list.copy() method may not work for you is because you assume that it creates a deep copy when, in reality, it only creates a shallow copy of the list. To create a deep copy where the list elements themselves are copied (e.g. for multi-dimensional lists), simply import the copy module and use its method deepcopy(x) to copy list x.
>>> import copy >>> lst = [[1, 2], 3, 4] >>> lst_2 = copy.deepcopy(lst)
Python List Copy And Append
How to copy a list and append an element in one line of Python code?
Simply use slicing to copy the list and the list concatenation operator + to add the list of a single element [x] to the result. But there are other nice ways, too. Check out the following ways to append element x to a given list lst and return the result as a copy:
- lst[:] + [x]
- lst.copy() + [x]
- [*lst, x]
The third way to copy a list and append a new element is my personal favorite because it’s fast, easy-to-read, and concise. It uses the asterisk operator to unpack the elements of the original list into a new list.
Python List Copy By Value
Do you want to copy all elements in your list “by value”? In other words, you want not only the list object to be copied (shallow copy) but also the list elements (deep copy).
This can be done with the deepcopy() method of Python’s copy library. Here’s an example:
>>> import copy >>> lst = [6, 7, [1, 2], "hello"] >>> lst_2 = copy.deepcopy(lst) >>> lst_2[2].append(42) >>> lst[2] [1, 2]
The element 42 was not appended to the nested list of lst.
Python List Copy With Slice
You can simply copy a list lst by using the slice operation lst[:] with default start and stop indices so that all elements are copied in the list. This creates a shallow copy of the list lst.
Related Articles:
Python List Copy Without First Element
To copy a list without its first element, simply use slicing list[1:]. By setting the start index to 1 all elements with index larger or equal to 1 are copied into the new list.
Here’s an example:
>>> lst = [1, 2, 3, 4] >>> lst[1:] [2, 3, 4]
Python List Copy Without Last Element
To copy a list without its last element, simply use slicing list[:-1]. By setting the start index to -1 (the right-most list element) all elements but the last one are copied into the new list.
Here’s an example:
>>> lst = [1, 2, 3, 4] >>> lst[:-1] [1, 2, 3]
Python List Copy Time Complexity
The time complexity of shallow list copying—examples are list.copy() or slicing list[:]—is linear to the number of elements in the list. For n list elements, the time complexity is O(n). Why? Because Python goes over all elements in the list and adds a copy of the object reference to the new list (copy by reference).
I wrote a quick script to evaluate that the time complexity of copying a list is, in fact, linear in the number of list elements:
import matplotlib.pyplot as plt
import time
y = []
for i in [100000 * j for j in range(10)]:
lst = list(range(i))
t0 = time.time()
lst_2 = lst[:]
t1 = time.time()
y.append(t1-t0)
plt.plot(y)
plt.xlabel("List elements (10**5)")
plt.ylabel("Time (sec)")
plt.show()Here’s the result:

The runtime grows linearly in the number of list elements.
Python List Copy Partially
How to copy a list partially? To copy only the elements between start index (included) and stop index (excluded), use slicing like this: list[start:stop]. This results in a new list that contains only parts of the list.
Python List Copy Multi-Dimensional List
To copy a multi-dimensional list (a list of lists), you need to create a deep copy. You can accomplish this with the copy library’s deepcopy() method as follows:
>>> import copy >>> lst = [[1, 2, 3], [4, 5, 6]] >>> lst_2 = copy.deepcopy(lst) >>> lst_2 [[1, 2, 3], [4, 5, 6]]
Now check if the copy is really deep by clearing the first list element in the copy:
>>> lst_2[0].clear() >>> lst [[1, 2, 3], [4, 5, 6]] >>> lst_2 [[], [4, 5, 6]]
You can see that the copy was really deep because the first element of the lst was not affected by the clear() method that removed all elements for the deep copy lst_2.
Summary
The list.copy() method creates a shallow copy of the list. The copy.deepcopy(list) method creates a deep copy of the list.
Python List count()
This tutorial shows you everything you need to know to help you master the essential count() method of the most fundamental container data type in the Python programming language.
Definition and Usage:
The list.count(x) method counts the number of occurrences of the element x in the list.
Here’s a short example:
>>> lst = [1, 2, 42, 2, 1, 42, 42] >>> lst.count(42) 3 >>> lst.count(2) 2
In the first line of the example, you create the list lst. You then count the number of times the integer values 42 and 2 appear in the list.
Code Puzzle — Try It Yourself:
Now you know the basics. Let’s deepen your understanding with a short code puzzle—can you solve it?
You can also solve this puzzle and track your Python skills on our interactive Finxter app.
Syntax: You can call this method on each list object in Python (Python versions 2.x and 3.x). Here’s the syntax:
list.count(value)
Arguments:
| Argument | Description |
|---|---|
value | Counts the number of occurrences of value in list. A value appears in the list if the == operator returns True. |
Return value: The method list.count(value) returns an integer value set to the number of times the argument value appears in the list. If the value does not appear in the list, the return value is 0.
Related article: Python Regex Superpower – The Ultimate Guide
Python List Count Values
You’ve already seen how to count values in a given list. Here’s the minimal example to count how often value x=42 appears in a list of elements:
>>> [42, 42, 1, 2, 3, 42, 1, 3].count(42) 3
The value 42 appears three times in the list.
It’s important that you understand how the count method works. Say, you’re looking for the value in a given list. If list element x == value the counter is increased by one. The method does not count the number of times an element is referenced in memory!
Here’s an example:
>>> lst = [[1,1], [1,1], (1,1), 42, 1] >>> lst.count([1,1]) 2
The top-level list refers to two independent list objects [1, 1] in memory. Still, if you count the number of occurrences of a third list [1, 1], the method correctly determines that it appears two times. That’s because two list elements are equal to the list [1, 1].
Note that values x and y are considered equal if x==y. You can see this for integer lists in the following example:
>>> lst_1 = [1, 1] >>> lst_2 = [1, 1] >>> lst_1 == lst_2 True
To summarize, the list.count(value) method counts the number of times a list element is equal to value (using the == comparison). Here’s a reference implementation:
def count(lst, value):
''' Returns the number of times
a list element is equal to value'''
count = 0
for element in lst:
count += element == value
return count
lst = [1, 1, 1, 1, 2]
print(lst.count(1))
# 4
print(lst.count(2))
# 1
print(lst.count(3))
# 0
(Note that this is not the real cPython implementation. It’s just a semantically equivalent implementation of the list.count(value) method for educational purposes.)
Related articles:
Python List Count Runtime Complexity
The time complexity of the count(value) method is O(n) for a list with n elements. The standard Python implementation cPython “touches” all elements in the original list to check if they are equal to the value.
Again, have a look at the reference implementation where you can see these comparison operations element == value in the code:
def count(lst, value):
count = 0
for element in lst:
count += element == value
return countThus, the time complexity is linear in the number of list elements.
You can see a plot of the time complexity of the count() method for growing list size here:

The figure shows how the elapsed time of counting a dummy element -99 in lists with growing number of elements grows linear to the number of elements.
If you’re interested in the code I used to generate this plot with Matplotlib, this is it:
import matplotlib.pyplot as plt
import time
y = []
for i in [100000 * j for j in range(10,100)]:
lst = list(range(i))
t0 = time.time()
x = lst.count(-99)
t1 = time.time()
y.append(t1-t0)
plt.plot(y)
plt.xlabel("List elements (10**5)")
plt.ylabel("Time (sec)")
plt.show()
Python List Count Duplicates
How can you count the number of duplicates in a given list?
Problem: Let’s consider an element a duplicate if it appears at least two times in the list. For example, the list [1, 1, 1, 2, 2, 3] has two duplicates 1 and 2.
Solution: You create an empty set duplicates. Then you iterate over the original list and add each element to the set that has a count value of at least 2.
Here’s the code:
def find_dups(lst):
dups = set()
for el in lst:
if lst.count(el)>1:
dups.add(el)
return dups
print(find_dups([1, 1, 1, 2, 2, 3]))
# {1, 2}
print(find_dups(["Alice", "Bob", "Alice"]))
# {'Alice'}
print(find_dups([1, 2, 3]))
# set()Note that this algorithm has quadratic time complexity because for each element in the list, you need to count the number of times it appears in the list—each of those count operations has linear time complexity.
Related article:
Python List Count Unique Values and Strings
How can you count the number of unique values (or strings) in a given list?
Problem: A value is considered unique if it appears only once in the list.
Solution: You count each element in the list and take only those with list.count(element) == 1.
Here’s the code:
def find_uniques(lst):
uniques = set()
for el in lst:
if lst.count(el) == 1:
uniques.add(el)
return uniques
print(find_uniques([1, 1, 2, 3, 3]))
# {2}
print(find_uniques(["Alice", "Bob", "Alice"]))
# {'Bob'}This algorithm has quadratic time complexity because for each element in the list, you need to count the number of times it appears in the list—each of those count operations has linear time complexity.
Python List Count All Elements (Count to Dict)
How can you count all elements in a list and store the result in a dictionary?
Problem: Given is a list. You want to count each element in the list. Then, you want to store the result in a dictionary mapping the elements to their frequencies of appearance (counts). For example, the list [1, 1, 2, 2, 3] should lead to the dictionary {1:2, 2:2, 3:1}.
Solution: You solve this problem using dictionary comprehension. The key is the list element and the value is the frequency of this element in the list. You use the count() method to do this.
Here’s the code:
def count_to_dict(lst):
return {k:lst.count(k) for k in lst}
print(count_to_dict(["Alice", "Bob", "Ann", "Alice", "Charles"]))
# {'Alice': 2, 'Bob': 1, 'Ann': 1, 'Charles': 1}
print(count_to_dict([1, 1, 1, 2, 2, 3]))
# {1: 3, 2: 2, 3: 1}This algorithm has quadratic time complexity because for each element in the list, you need to count the number of times it appears in the list—each of those count operations has linear time complexity.
Related article:
Python List Count With Condition
How can you count elements under a certain condition in Python? For example, what if you want to count all even values in a list? Or all prime numbers? Or all strings that start with a certain character? There are multiple ways to accomplish this, let’s discuss them one by one.
Say, you have a condition for each element x. Let’s make it a function with the name condition(x). You can define any condition you want—just put it in your function. For example this condition returns True for all elements that are greater than the integer 10:
def condition(x):
return x > 10
print(condition(10))
# False
print(condition(2))
# False
print(condition(11))
# True
But you can also define more complicated conditions such as checking if they are prime numbers.
Python List Count If
How can you count the elements of the list IF the condition is met?
The answer is to use a simple generator expression sum(condition(x) for x in lst):
>>> def condition(x): return x>10 >>> lst = [10, 11, 42, 1, 2, 3] >>> sum(condition(x) for x in lst) 2
The result indicates that there are two elements that are larger than 10. You used a generator expression that returns an iterator of Booleans. Note that the Boolean True is represented by the integer value 1 and the Boolean False is represented by the integer value 0. That’s why you can simply calculate the sum over all Booleans to obtain the number of elements for which the condition holds.
Python List Count Greater / Smaller Than
If you want to determine the number of elements that are greater than or smaller than a specified value, just modify the condition in this example:
>>> def condition(x): return x>10 >>> lst = [10, 11, 42, 1, 2, 3] >>> sum(condition(x) for x in lst) 2
For example, to find the number of elements smaller than 5, use the condition x<5 in the generator expression:
>>> lst = [10, 11, 42, 1, 2, 3] >>> sum(x<5 for x in lst) 3
Python List Count Zero / Non-Zero
To count the number of zeros in a given list, use the list.count(0) method call.
To count the number of non-zeros in a given list, you should use conditional counting as discussed before:
def condition(x):
return x!=0
lst = [10, 11, 42, 1, 2, 0, 0, 0]
print(sum(condition(x) for x in lst))
# 5
Python List Count Lambda + Map
An alternative is to use a combination of the map and the lambda function.
Related articles:
- [Full Tutorial] Map Function: manipulates each element in an iterable.
- [Full Tutorial] Lambda Function: creates an anonymous function.
Here’s the code:
>>> sum(map(lambda x: x%2==0, [1, 2, 3, 4, 5])) 2
You count the number of even integers in the list.
- The lambda function returns a truth value for a given element
x. - The map function transforms each list element into a Boolean value (1 or 0).
- The sum function sums up the “1”s.
The result is the number of elements for which the condition evaluates to True.
Python List Count Regex / Count Matches
Given a list of strings. How can you check how many list elements match a certain regex pattern? (If you need a refresher on Python regular expressions, check out my ultimate guide on this blog – it’s really ultimate!)
- List
lstof string elements - Pattern
pto be matched against the strings in the list.
Solution: Use the concept of generator expressions with the ternary operator.
Related articles:
Here’s the code:
>>> import re >>> p = 'a...e' >>> lst = ['annie', 'alice', 'apex'] >>> sum(1 if re.match(p, x) else 0 for x in lst) 2
Python List Count Wildcard
Do you want to count all string occurrences of a given prefix (e.g. prefix "Sus" for strings "Susie", "Susy", "Susi")?
Solution: Again you can use the concept of generator expressions with the ternary operator.
Related articles:
Here’s the code for this one using the wildcard operator in a pattern to count all occurrences of this pattern in the list.
>>> import re >>> lst = ['Susi', 'Ann', 'Susanne', 'Susy'] >>> pattern = 'Sus.*' >>> frequency = sum(1 if re.match(pattern, x) else 0 for x in lst) >>> print(frequency) 3
The generator expression produces a bunch of 1s and 0s—the former if the list element starts with prefix 'Sus' and the latter if it doesn’t. By summing over all elements, you get the number of matches of the wildcard operator.
Python List Count Not Working
The list.count(value) method is very hard to break. Look what I tried to get an error:
>>> lst = [1, 1, 1, 2, 2, 3]
>>> lst.count(1)
3
>>> lst.count(2, 2)
Traceback (most recent call last):
File "<pyshell#19>", line 1, in <module>
lst.count(2, 2)
TypeError: count() takes exactly one argument (2 given)
>>> lst.count(4)
0
>>> lst.count("1")
0
>>> count(lst)
Traceback (most recent call last):
File "<pyshell#22>", line 1, in <module>
count(lst)
NameError: name 'count' is not defined
>>> You have to try really hard to break it. Just consider these tips:
- The
list.count(value)method takes exactly one argument: the value you want to count. If you define more or less arguments, there will be an error. - The
list.count(value)method is just that: a method of a list object. You need to call it on a list object. If you try to call it on another object, it will probably fail. If you try to use it just like that (without the list prefix, i.e.,count(value)), it will also fail. - The
list.count(value)will return 0 if you put in any object as an argument that does not evaluate toTruewhen compared to the list elements using the==comparison operator. So make sure that the object you want to count really evaluates toTrueif you compare it against some list elements. You may assume this but it could easily fail to do so.
Python List Reference Count
The Python garbage collector keeps track of the number of times each object in memory is referenced. You call this “reference counting”. All objects that have reference count of zero cannot be reached by your code and, thus, can be safely removed by the garbage collector.
It’s unrelated to Python lists with the one exception: each list element increases the reference count by one because a list really is an array of pointers to the list objects in memory in the cPython implementation.
Python List Count Tuples
How can you count the number of times a given tuple appears in a list?
Simply use the tuple as the input argument value for the list.count(value) method. Here’s an example:
>>> lst = [(1, 2), (1, 1), 99, "Alice", True, (1, 1)] >>> lst.count((1, 1)) 2
How can you count the number of tuples in a given list?
Use the type(x) method to check the type of a given variable x. Then compare the result with your desired data type (e.g. tuple).
Here’s an example:
>>> sum(type(x)==tuple for x in lst) 3
Related articles:
Python List Count and Sort
Given: list lst.
Problem: You want to count the number of occurrences of all values in the list and sort them by their frequency.
Example: for list elements [1, 1, 1, 1, 0, 0, 3, 1, 1, 3, 3, 3] you want to obtain their frequencies in a sorted manner:
6 times --> element 1 4 times --> element 3 2 times --> element 0
Solution: Use the collections.Counter(lst).most_common() method that does exactly that. You can find the documentation here.
import collections lst = [3, 2, 1, 1, 1, 2, 2, 3] print(collections.Counter(lst).most_common())
Generates output:
[(2, 3), (1, 3), (3, 2)]
Python List Count Slow
Do you want to improve performance of the list.count(value) method? It’s not easy because the runtime complexity is O(n) with n list elements.
There’s not much you can do about it. Of course, if you need to count the same element multiple times, you can use a cache dictionary to store its result. But this works only if the list has not changed.
You can also sort the list once which takes O(n log n) for n list elements. After that, you can call the implement a count method based on binary search with O(log n) runtime complexity. But if you need to count only a single element, this is not effective.
Interestingly, counting all elements in a list also has O(n) runtime complexity. Why? Because you’ll go over each element and add it to a dictionary if it doesn’t exist already (mapping the element to its counter value, initially 1). If it exists, you simply increment the counter by one.
In this excellent benchmark, you can find the performance of different counting methods. The Counter class seems to have best performance.
Python List Count vs Len
What’s the difference?
- The
list.count(x)method counts the number of occurrences of the elementxin thelist. - The
len(list)method returns the total number of elements in the list.
Here’s a minimal example:
>>> lst = [1, 2, 2, 2, 2] >>> lst.count(2) 4 >>> len(lst) 5
Summary
The list.count(x) method counts the number of times the element x appears in the list.
Python List extend()
How can you not one but multiple elements to a given list? Use the extend() method in Python. This tutorial shows you everything you need to know to help you master an essential method of the most fundamental container data type in the Python programming language.
Definition and Usage
The list.extend(iter) method adds all elements in the argument iterable iter to an existing list.
Here’s a short example:
>>> lst = [1, 2, 3] >>> lst.extend([4, 5, 6]) >>> lst [1, 2, 3, 4, 5, 6]
In the first line of the example, you create the list lst. You then append the integers 4, 5, 6 to the end of the list using the extend() method. The result is the list with six elements [1, 2, 3, 4, 5, 6].
Try it yourself:
Syntax
You can call this method on each list object in Python. Here’s the syntax:
list.extend(iterable)
Arguments
| Argument | Description |
|---|---|
iterable | All the elements of the iterable will be added to the end of the list—in the order of their occurrence. |
Video
Code Puzzle
Now you know the basics. Let’s deepen your understanding with a short code puzzle—can you solve it?
# Puzzle # Author: Finxter Lee lst1 = [1, 2, 3] lst2 = [4, 5, 6] lst1.append(lst2) lst3 = [1, 2, 3] lst4 = [4, 5, 6] lst3.extend(lst4) print(lst1 == lst3) # What's the output of this code snippet?
You can check out the solution on the Finxter app. (I know it’s tricky!)
Examples
Let’s dive into a few more examples:
>>> lst = [1, 2, 3]
>>> lst.extend({32, 42})
>>> lst
[1, 2, 3, 32, 42]
>>> lst.extend((1, 2))
>>> lst
[1, 2, 3, 32, 42, 1, 2]
>>> lst.extend(range(10,13))
>>> lst
[1, 2, 3, 32, 42, 1, 2, 10, 11, 12]
>>> lst.extend(1)
Traceback (most recent call last):
File "<pyshell#10>", line 1, in <module>
lst.extend(1)
TypeError: 'int' object is not iterable
>>> You can see that the extend() method allows for all sorts of iterables: lists, sets, tuples, and even range objects. But what it doesn’t allow is an integer argument. Why? Because the integer argument isn’t an iterable—it doesn’t make sense to “iterate over all values in an integer”.
Python List extend() At The Beginning
What if you want to use the extend() method at the beginning: you want to “add” a number of elements just before the first element of the list.
Well, you should work on your terminology for starters. But if you insist, you can use the insert() method instead.
Here’s an example:
>>> lst = [1, 2, 3] >>> lst.insert(0, 99) >>> lst [99, 1, 2, 3]
The insert(i, x) method inserts an element x at position i in the list. This way, you can insert an element to each position in the list—even at the first position. Note that if you insert an element at the first position, each subsequent element will be moved by one position. In other words, element i will move to position i+1.
Python List extend() vs +
List concatenation operator +: If you use the + operator on two integers, you’ll get the sum of those integers. But if you use the + operator on two lists, you’ll get a new list that is the concatenation of those lists.
l1 = [1, 2, 3] l2 = [4, 5, 6] l3 = l1 + l2 print(l3)
Output:
[1, 2, 3, 4, 5, 6]
The problem with the + operator for list concatenation is that it creates a new list for each list concatenation operation. This can be very inefficient if you use the + operator multiple times in a loop.
How fast is the + operator really? Here’s a common scenario how people use it to add new elements to a list in a loop. This is very inefficient:
import time
start = time.time()
l = []
for i in range(100000):
l = l + [i]
stop = time.time()
print("Elapsed time: " + str(stop - start))Output:
Elapsed time: 14.438847541809082
The experiments were performed on my notebook with an Intel(R) Core(TM) i7-8565U 1.8GHz processor (with Turbo Boost up to 4.6 GHz) and 8 GB of RAM.
I measured the start and stop timestamps to calculate the total elapsed time for adding 100,000 elements to a list.
The result shows that it takes 14 seconds to perform this operation.
This seems slow (it is!). So let’s investigate some other methods to concatenate and their performance:
Python List extend() Performance
Here’s a similar example that shows how you can use the extend() method to concatenate two lists l1 and l2.
l1 = [1, 2, 3] l2 = [4, 5, 6] l1.extend(l2) print(l1)
Output:
[1, 2, 3, 4, 5, 6]
But is it also fast? Let’s check the performance!
Performance:
I performed a similar experiment as before for the list concatenation operator +.
import time
start = time.time()
l = []
l.extend(range(100000))
stop = time.time()
print("Elapsed time: " + str(stop - start))
Output:
Elapsed time: 0.0
I measured the start and stop timestamps to calculate the total elapsed time for adding 100,000 elements to a list.
The result shows that it takes negligible time to run the code (0.0 seconds compared to 0.006 seconds for the append() operation above).
The extend() method is the most concise and fastest way to concatenate lists.
Python List append() vs extend()
I shot a small video explaining the difference and which method is faster, too:
The method list.append(x) adds element x to the end of the list.
The method list.extend(iter) adds all elements in iter to the end of the list.
The difference between append() and extend() is that the former adds only one element and the latter adds a collection of elements to the list.
You can see this in the following example:
>>> l = [] >>> l.append(1) >>> l.append(2) >>> l [1, 2] >>> l.extend([3, 4, 5]) >>> l [1, 2, 3, 4, 5]
In the code, you first add integer elements 1 and 2 to the list using two calls to the append() method. Then, you use the extend method to add the three elements 3, 4, and 5 in a single call of the extend() method.
Which method is faster — extend() vs append()?
To answer this question, I’ve written a short script that tests the runtime performance of creating large lists of increasing sizes using the extend() and the append() methods.
Our thesis is that the extend() method should be faster for larger list sizes because Python can append elements to a list in a batch rather than by calling the same method again and again.
I used my notebook with an Intel(R) Core(TM) i7-8565U 1.8GHz processor (with Turbo Boost up to 4.6 GHz) and 8 GB of RAM.
Then, I created 100 lists with both methods, extend() and append(), with sizes ranging from 10,000 elements to 1,000,000 elements. As elements, I simply incremented integer numbers by one starting from 0.
Here’s the code I used to measure and plot the results: which method is faster—append() or extend()?
import time
def list_by_append(n):
'''Creates a list & appends n elements'''
lst = []
for i in range(n):
lst.append(n)
return lst
def list_by_extend(n):
'''Creates a list & extends it with n elements'''
lst = []
lst.extend(range(n))
return lst
# Compare runtime of both methods
list_sizes = [i * 10000 for i in range(100)]
append_runtimes = []
extend_runtimes = []
for size in list_sizes:
# Get time stamps
time_0 = time.time()
list_by_append(size)
time_1 = time.time()
list_by_extend(size)
time_2 = time.time()
# Calculate runtimes
append_runtimes.append((size, time_1 - time_0))
extend_runtimes.append((size, time_2 - time_1))
# Plot everything
import matplotlib.pyplot as plt
import numpy as np
append_runtimes = np.array(append_runtimes)
extend_runtimes = np.array(extend_runtimes)
print(append_runtimes)
print(extend_runtimes)
plt.plot(append_runtimes[:,0], append_runtimes[:,1], label='append()')
plt.plot(extend_runtimes[:,0], extend_runtimes[:,1], label='extend()')
plt.xlabel('list size')
plt.ylabel('runtime (seconds)')
plt.legend()
plt.savefig('append_vs_extend.jpg')
plt.show()The code consists of three high-level parts:
- In the first part of the code, you define two functions
list_by_append(n)andlist_by_extend(n)that take as input argument an integer list sizenand create lists of successively increasing integer elements using theappend()andextend()methods, respectively. - In the second part of the code, you compare the runtime of both functions using 100 different values for the list size
n. - In the third part of the code, you plot everything using the Python matplotlib library.
Here’s the resulting plot that compares the runtime of the two methods append() vs extend(). On the x axis, you can see the list size from 0 to 1,000,000 elements. On the y axis, you can see the runtime in seconds needed to execute the respective functions.
The resulting plot shows that both methods are extremely fast for a few tens of thousands of elements. In fact, they are so fast that the time() function of the time module cannot capture the elapsed time.
But as you increase the size of the lists to hundreds of thousands of elements, the extend() method starts to win:
For large lists with one million elements, the runtime of the extend() method is 60% faster than the runtime of the append() method.
The reason is the already mentioned batching of individual append operations.
However, the effect only plays out for very large lists. For small lists, you can choose either method. Well, for clarity of your code, it would still make sense to prefer extend() over append() if you need to add a bunch of elements rather than only a single element.
Python Append List to Another List
To append list lst_1 to another list lst_2, use the lst_2.extend(lst_1) method. Here’s an example:
>>> lst_1 = [1, 2, 3] >>> lst_2 = [4, 5, 6] >>> lst_2.extend(lst_1) >>> lst_2 [4, 5, 6, 1, 2, 3]
Python List extend() Returns None
The return value of the extend() method is None. The return value of the extend() method is not a list with the added elements. Assuming this is a common source of mistakes.
Here’s such an error where the coder wrongly assumed this:
>>> lst = [1, 2].extend([3, 4])
>>> lst[0]
Traceback (most recent call last):
File "<pyshell#16>", line 1, in <module>
lst[0]
TypeError: 'NoneType' object is not subscriptable It doesn’t make sense to assign the result of the extend() method to another variable—because it’s always None. Instead, the extend() method changes a list object without creating (and returning) a new list.
Here’s the correct version of the same code:
>>> lst = [1, 2] >>> lst.extend([3, 4]) >>> lst[0] 1
Now, you change the list object itself by calling the extend() method on it. You through away the None return value because it’s not needed.
Python List Concatenation
So you have two or more lists and you want to glue them together. This is called list concatenation. How can you do that?
These are six ways of concatenating lists (detailed tutorial here):
- List concatenation operator
+ - List
append()method - List
extend()method - Asterisk operator
* Itertools.chain()- List comprehension
a = [1, 2, 3]
b = [4, 5, 6]
# 1. List concatenation operator +
l_1 = a + b
# 2. List append() method
l_2 = []
for el in a:
l_2.append(el)
for el in b:
l_2.append(el)
# 3. List extend() method
l_3 = []
l_3.extend(a)
l_3.extend(b)
# 4. Asterisk operator *
l_4 = [*a, *b]
# 5. Itertools.chain()
import itertools
l_5 = list(itertools.chain(a, b))
# 6. List comprehension
l_6 = [el for lst in (a, b) for el in lst]Output:
''' l_1 --> [1, 2, 3, 4, 5, 6] l_2 --> [1, 2, 3, 4, 5, 6] l_3 --> [1, 2, 3, 4, 5, 6] l_4 --> [1, 2, 3, 4, 5, 6] l_5 --> [1, 2, 3, 4, 5, 6] l_6 --> [1, 2, 3, 4, 5, 6] '''
What’s the best way to concatenate two lists?
If you’re busy, you may want to know the best answer immediately. Here it is:
To concatenate two lists l1, l2, use the l1.extend(l2) method which is the fastest and the most readable.
To concatenate more than two lists, use the unpacking (asterisk) operator [*l1, *l2, ..., *ln].
However, you should avoid using the append() method for list concatenation because it’s neither very efficient nor concise and readable.
Python List extend() Unique – Add If Not Exists
A common question is the following:
How can you add or append elements to a list, but only if they don’t already exist in the list?
When ignoring any performance issues, the answer is simple: use an if condition in combination with the membership operation element in list and only append() the element if the result is False (don’t use extend() for this fine-grained method). As an alternative, you can also use the negative membership operation element not in list and add the element if the result is True.
Example: Say, you want to add all elements between 0 and 9 to a list of three elements. But you don’t want any duplicates. Here’s how you can do this:
lst = [1, 2, 3]
for element in range(10):
if element not in lst:
lst.append(element) Resulting list:
[1, 2, 3, 0, 4, 5, 6, 7, 8, 9]
You add all elements between 0 and 9 to the list but only if they aren’t already present. Thus, the resulting list doesn’t contain duplicates.
But there’s a problem: this method is highly inefficient!
In each loop iteration, the snippet element not in lst searches the whole list for the current element. For a list with n elements, this results in n comparisons, per iteration. As you have n iterations, the runtime complexity of this code snippet is quadratic in the number of elements.
Can you do better?
Sure, but you need to look beyond the list data type: Python sets are the right abstraction here. If you need to refresh your basic understanding of the set data type, check out my detailed set tutorial (with Harry Potter examples) on the Finxter blog.
Why are Python sets great for this? Because they don’t allow any duplicates per design: a set is a unique collection of unordered elements. And the runtime complexity of the membership operation is not linear in the number of elements (as it’s the case for lists) but constant!
Example: Say, you want to add all elements between 0 and 9 to a set of three elements. But you don’t want any duplicates. Here’s how you can do this with sets:
s = {1, 2, 3}
for element in range(10):
s.add(element)
print(s)
Resulting set:
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}The set doesn’t allow for duplicate entries so the elements 1, 2, and 3 are not added twice to the set.
You can even make this code more concise:
s = {1, 2, 3}
s = s.union(range(10))
print(s)Output:
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}The union method creates a new set that consists of all elements in both operands.
Now, you may want to have a list as a result and not a set. The solution is simple: convert the resulting set to a list by using the list(set) conversion method. This has linear runtime complexity and if you call it only once, it doesn’t change the overall runtime complexity of the code snippet (it remains linear in the number of set elements).
Problem: what if you want to maintain the order information and still add all elements that are not already in the list?
The problem with the previous approach is that by converting the list to a set, the order of the list is lost. In this case, I’d advise you to do the following: use two data structures, a list and a set. You use the list to add new elements and keep the order information. You use the set to check membership (constant rather than linear runtime complexity). Here’s the code:
lst = [1, 2, 3]
s = set(lst)
for element in range(10):
if element not in s:
s.add(element)
lst.append(element)
print(lst)Resulting list:
[1, 2, 3, 0, 4, 5, 6, 7, 8, 9]
You can see that the resulting list doesn’t contain any duplicates but the order information is maintained. At the same time, the runtime complexity of the code is linear because each loop iteration can be completed in constant time.
The trade-off is that you have to maintain two data structures which results in double the memory overhead. This nicely demonstrates the common inverse relationship between memory and runtime overhead.
Python List extend() Return New List
If you use the lst.extend(iter) operation, you add the elements in iter to the existing list lst. But what if you want to create a new list where all elements were added?
The answer is simply to use the list concatenation operation lst + list(iter) which creates a new list each time it is used. The original list lst will not be affected by the list concatenation operation.
Here’s an example that shows that the extend() method only modifies an existing list:
>>> lst_1 = [1, 2, 3] >>> lst_2 = lst_1.extend([42, 99]) >>> lst_1 [1, 2, 3, 42, 99]
And here’s the example that shows how to create a new list as you add elements 42 and 99 to a list:
>>> lst_3 = [1, 2, 3] >>> lst_4 = lst_3 + [42, 99] >>> lst_3 [1, 2, 3]
By using the list concatenation operation, you can create a new list rather than appending the element to an existing list.
Python List extend() Time Complexity, Memory, and Efficiency
Time Complexity: The extend() method has linear time complexity O(n) in the number of elements n to be added to the list. Adding one element to the list requires only a constant number of operations—no matter the size of the list.
Space Complexity: The extend() method has linear space complexity O(n) in the number of elements n to be added to the list. The operation itself needs only a constant number of bytes for the involved temporary variables. The memory overhead does not depend on the size of the list.
Python List extend() at Index
If you want to insert a whole list at a certain position and create a new list by doing so, I’d recommend to use Python slicing. Check out this in-depth blog tutorial that’ll show you everything you need to know about slicing.
Here’s the code that shows how to create a new list after inserting a list at a certain position:
>>> lst = [33, 44, 55] >>> lst[:2] + [99, 42] + lst[2:] [33, 44, 99, 42, 55]
Again, you’re using list concatenation to create a new list with element 99 inserted at position 2. Note that the slicing operations lst[:2] and lst[2:] create their own shallow copy of the list.
Summary
The list.extend(iter) method adds all elements in iter to the end of the list (in the order of their appearance).
Python List index()
This tutorial shows you everything you need to know to help you master the essential index() method of the most fundamental container data type in the Python programming language.
Definition and Usage: The list.index(value) method returns the index of the value argument in the list. You can use optional start and stop arguments to limit the index range where to search for the value in the list. If the value is not in the list, the method throws a ValueError.
Here’s a short example:
>>> lst = ["Alice", 42, "Bob", 99]
>>> lst.index("Alice")
0
>>> lst.index(99)
3
>>> lst.index(99, 1, 3)
Traceback (most recent call last):
File "<pyshell#9>", line 1, in <module>
lst.index(99, 1, 3)
ValueError: 99 is not in listIn the first line of the example, you create the list lst. You then look up the index of the elements "Alice" and 99. If you use start=1 and stop=3, the value 99 is not found anymore and Python throws a ValueError.
Code Puzzle — Try It Yourself:
Now you know the basics. Let’s deepen your understanding with a short code puzzle—can you solve it?
You can also solve this puzzle and track your Python skills on our interactive Finxter app.
Syntax: You can call this method on each list object in Python (Python versions 2.x and 3.x). Here’s the syntax:
list.index(value, start=0, stop=9223372036854775807)
Arguments:
| Argument | Description |
|---|---|
value | Returns the index of value in the list. A value appears in the list if the == operator returns True. If the value doesn’t exist in the list, the return value is -1. |
start | (Optional.) The index of where you want to start searching in the list. All list elements in front of this position are ignored. This is a positional argument, not a keyword argument. |
stop | (Optional.) The index of where you want to stop searching in the list. All list elements after this position are ignored. This is a positional argument, not a keyword argument. |
Return value: The method list.index(value) returns an integer value representing the index where the argument value appears in the list. If the value does not appear in the list, the method throws a ValueError.
Related article: Python Regex Superpower – The Ultimate Guide
Python List Index Implementation
So you really want to know the cPython implementation of the index() method?
On a high level, the algorithm to find the index of a given value in the list consists of the following steps:
- Ensure that the start and stop indices are at least zero.
- Iterate over all elements in the list and check if they are equal.
- If they are equal, return immediately from the method.
- If no element is found, throw the
ValueError.
Here’s the C++ implementation in case you want to revive your C++ skills a bit. Otherwise, just skip it and move immediately to the next section where I’ll discuss the computational complexity of the algorithm.
/*[clinic input]
list.index
value: object
start: slice_index(accept={int}) = 0
stop: slice_index(accept={int}, c_default="PY_SSIZE_T_MAX") = sys.maxsize
/
Return first index of value.
Raises ValueError if the value is not present.
[clinic start generated code]*/
static PyObject *
list_index_impl(PyListObject *self, PyObject *value, Py_ssize_t start,
Py_ssize_t stop)
/*[clinic end generated code: output=ec51b88787e4e481 input=40ec5826303a0eb1]*/
{
Py_ssize_t i;
if (start < 0) {
start += Py_SIZE(self);
if (start < 0)
start = 0;
}
if (stop < 0) {
stop += Py_SIZE(self);
if (stop < 0)
stop = 0;
}
for (i = start; i < stop && i < Py_SIZE(self); i++) {
PyObject *obj = self->ob_item[i];
Py_INCREF(obj);
int cmp = PyObject_RichCompareBool(obj, value, Py_EQ);
Py_DECREF(obj);
if (cmp > 0)
return PyLong_FromSsize_t(i);
else if (cmp < 0)
return NULL;
}
PyErr_Format(PyExc_ValueError, "%R is not in list", value);
return NULL;
}But what’s the computational complexity of this index() method in Python?
Python List Index Time Complexity
For simplicity, here’s the Python equivalent of the implementation with some basic simplifications that don’t change the overall complexity:
def index(value, lst):
for i, el in enumerate(lst):
if el==value:
return i
raise Exception('ValueError')
print(index(42, [1, 2, 42, 99]))
# 2
print(index("Alice", [1, 2, 3]))
'''
Traceback (most recent call last):
File "C:\Users\xcent\Desktop\code.py", line 10, in <module>
print(index("Alice", [1, 2, 3]))
File "C:\Users\xcent\Desktop\code.py", line 5, in index
raise Exception('ValueError')
Exception: ValueError
'''I know it’s not the perfect replication of the above C++ code. But it’s enough to see the computational (runtime) complexity of the list.index(value) method.
The index() method has linear runtime complexity in the number of list elements. For n elements, the runtime complexity is O(n) because in the worst-case you need to iterate over each element in the list to find that the element does not appear in it.
Let’s check the runtime complexity practically for different list sizes with a short benchmark program.
You can see a plot of the time complexity of the index() method for growing list size here:

The figure shows how the elapsed time of finding the last list element in a list. This experiment is repeated for growing number of elements. The runtime grows linear to the number of elements.
If you’re interested in the code I used to generate this plot with Matplotlib, this is it:
import matplotlib.pyplot as plt
import time
y = []
for i in [100000 * j for j in range(10,100)]:
lst = list(range(i))
t0 = time.time()
x = lst.count(-99)
t1 = time.time()
y.append(t1-t0)
plt.plot(y)
plt.xlabel("List elements (10**5)")
plt.ylabel("Time (sec)")
plt.show()
Related articles:
Python List Index Without Exception
Per default, the list.index() method will throw a ValueError if the value is not equal to an element of the list. When I first encountered the list.index() method, I assumed that the return value will be simply -1 so I was surprised that the method threw an error. However, after thinking about the problem, I came to the conclusion that it makes a lot of sense NOT to return the value -1 if an index cannot be found. The reason is that by convention, the index -1 refers to the last element in the list in Python:
>>> lst = [1, 2, 3] >>> lst[-1] 3
But what if you don’t want to get an exception if the value cannot be found?
In this case, you can use lambda functions and list comprehension to write your own small method in a single line of code:
>>> ind = lambda l, v: [i for i in range(len(l)) if l[i] == v]
>>> ind('Alice', ['Bob', 'Alice', 'Frank'])
[]
>>> ind(['Bob', 'Alice', 'Frank'], 'Alice')
[1]The function ind finds all occurrences of a given value in a given list in linear runtime without throwing an error. Instead, it’ll simply return an empty list.
Related Articles
- List Comprehension (Internal Link to Finxter Blog)
- Lambda Function (Internal Link to Finxter Blog)
- Python One-Liner Book (External Link to Amazon)
Python List Index Try Catch
The Python list.index(value) method throws a ValueError if the value is not in the list. If you’re not doing anything about it, this can break your whole program. So what can you do about it?
The Pythonic way is to “catch” the exception in a try/catch block. You can then handle it in the catch block that’s only executed if the value is not in the list. (You need a backup plan anyways.)
Here’s how you can catch the ValueError in a minimal code snippet:
lst = [1, 2, 3]
try:
index = lst.index('Alice')
except ValueError:
index = None
print(index)
# NoneThe output is the expected:
None
You don’t even see that there was an exception when executing the code.
However, if this seems to long-winded for you (and you love Python one-liners as much as I do, you should do the following:
First, check out my new book Python One-Liners that will teach you to understand every single line of code you’ll ever encounter in practice.
Second, use a one-liner to achieve the same thing:
lst = [1, 2, 3] indices = [i for i in range(len(lst)) if lst[i]=='Alice'] index = indices[0] if indices else None print(index)
This is my preferred option.
Python List Index Out of Range
This error message appears if you try to access list elements with an index that’s either larger than the maximal allowed index or smaller than the negative indexing -len(list).
Here’s the minimal example of both cases:
>>> lst = [1, 2, 3]
>>> lst[3]
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
lst[3]
IndexError: list index out of range
>>> lst[-5]
Traceback (most recent call last):
File "<pyshell#4>", line 1, in <module>
lst[-5]
IndexError: list index out of rangeTo avoid the IndexError, just use indices within the allowed range (inclusive numbers) between -len(list) and +len(list)-1.
Here’s how this error can appear when removing elements from a list while iterating over it:
l=[3, 3, 3, 4, 4, 4]
for i in range(0,len(l)):
l.pop(i)
Traceback (most recent call last):
File "C:\Users\xcent\Desktop\code.py", line 3, in <module>
l.pop(i)
IndexError: pop index out of rangeDon’t do that! The behavior won’t be as you expected because the iterator is created only once before entering the loop. But removing an element from a list can change the indices of all elements in the list so the predefined indices do not point to the correct elements anymore.
Python List Index Multiple
To find multiple elements of an element in the list, you can use the index() method multiple times by setting the start index to the previously found index.
lst = [1, 2, 3, 3, 3, 3, 3, 3, 0, 0, 0]
value = 3
min_index = 0
indices = []
while min_index < len(lst):
try:
indices.append(lst.index(value, min_index))
min_index = indices[-1] + 1
except ValueError:
min_index = len(lst)
print(indices)
# [2, 3, 4, 5, 6, 7]But I wouldn’t advise it as it’s complicated and hard to read. A simple one-liner is all you need:
indices = [i for i in range(len(lst)) if lst[i] == value] print(indices) # [2, 3, 4, 5, 6, 7]
Beautiful is better than complex!
Python List Index of Max / Min
Given is a list:
a = [33, 11, 23, 55, 89, 101, 1, 101, 33, 83, 101]
The maximum element in the list is 101.
Problem: find all index position(s) of the maximum in the list.
Solution: use the following concise solution to get a list of maximum positions.
a = [33, 11, 23, 55, 89, 101, 1, 101, 33, 83, 101] maxs = [i for i in range(len(a)) if a[i] == max(a)] print(maxs) # [5, 7, 10]
In the code snippet, you use list comprehension to get all indices of the maximum element max(a).
Of course, if you care about performance, you can also optimize this by calculating max(a) once, store it in a variable max_a and using the variable in instead of calculating it again and again.
a = [33, 11, 23, 55, 89, 101, 1, 101, 33, 83, 101] max_a = max(a) maxs = [i for i in range(len(a)) if a[i] == max_a] print(maxs) # [5, 7, 10]
You can easily do the same thing for the indices of the minimum elements in a list by using min(a) rather than max(a):
a = [33, 11, 23, 55, 89, 101, 1, 101, 33, 83, 101] min_a = min(a) mins = [i for i in range(len(a)) if a[i] == min_a] print(mins) # [6]
Python List Index From End (Reverse)
You can calculate the index from the end by using the reversed list (I used slicing lst[::-1] with negative step size to reverse the list).
Say, you’ve a list of elements. You’re looking for the value 101. By default, the list.index(value) method looks from the left and returns the left-most element that’s equal to value. But what if you want to do this from the right?
Here’s how: you calculate the index (with respect to the original list) like this: index_right = len(a) - a[::-1].index(101) - 1.
a = [23, 55, 89, 101, 1, 101, 33, 83] index_left = a.index(101) index_right = len(a) - a[::-1].index(101) - 1 print(index_left) # 3 print(index_right) # 5
Just think about it for a moment. If you just reverse the list and search for the first occurrence of the value, you’ll get the wrong index with regards to the original list. (You’ll get it backwards.) So you first need to reverse the indexing scheme as done in the code.
Python List Index Regex / Wildcard
How can you find the index of the elements in a list that match a certain regex?
Related article:
Answer: You do this with a short list comprehension statement (there’s no built-in method and it’s simple enough).
import re lst = ['Alice', 'Bob', 'Ann', 'Albrecht'] pattern = 'A.*' matching_indices = [i for i in range(len(lst)) if re.match(pattern, lst[i])] print(matching_indices) # [0, 2, 3]
The re.match(pattern, lst[i]) method returns a matching object if the pattern matches the element at position i in the list. In this case, you add it to the result list.
Python List Index Tuple
How to find an index of a tuple in a list of tuples?
Use the list.index(value) method that returns the index of the first occurrence of the value in the list. It also works for tuples:
>>> [(1, 1), (2, 2), (3, 3)].index((3,3)) 2
Python List Index True False
How to find all indices of True values in a list of tuples?
Use list comprehension with the built-in enumerate() function to iterate over all (index, value) pairs. Here’s the minimal example:
lst = [True, True, True, False, False, True] print([i for i, x in enumerate(lst) if x]) # [0, 1, 2, 5]
You can do the same but check for not x to find all indices of False values in a list:
lst = [True, True, True, False, False, True] print([i for i, x in enumerate(lst) if not x]) # [3, 4]
Python List Index Zero / Non-Zero
How to find the indices of all zero elements in a list?
Use list comprehension with the built-in enumerate() function to iterate over all (index, value) pairs. Here’s the minimal example:
lst = [0, 0, 0, 1, 1, 1, 0, 1] print([i for i, x in enumerate(lst) if not x]) # [0, 1, 2, 6]
You can find all non-zero elements by skipping the negation in the list comprehension condition:
lst = [0, 0, 0, 1, 1, 1, 0, 1] print([i for i, x in enumerate(lst) if x]) # [3, 4, 5, 7]
Python List Index Pop
The list.pop(index) method with the optional argument index removes and returns the element at the position index.
Related article:
An example is as follows:
>>> lst = [1, 2, 3] >>> lst.pop() 3 >>> lst [1, 2]
In the first line of the example, you create the list lst. You then remove and return the final element 3 from the list. The result is the list with only two elements [1, 2].
Python List Index Delete
This trick is also relatively unknown among Python beginners:
- Use
del lst[index]to remove the element at index. - Use
del lst[start:stop]to remove all elements in the slice.
>>> lst = list(range(10)) >>> lst [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> del lst[5] >>> lst [0, 1, 2, 3, 4, 6, 7, 8, 9] >>> del lst[:4] >>> lst [4, 6, 7, 8, 9]
Python List Index Range
If you’re looking for an index range, you’re probably meaning slicing which is an advanced technique to carve out a range of values from a Python list or string. See the full slicing tutorial on the Finxter blog here.
The notation is list[start:stop:step]. The step argument is optional and you don’t need it to carve out a range of values.
Here are some examples:
>>> lst = ['a', 'b', 'c', 'd', 'e'] >>> lst[:] ['a', 'b', 'c', 'd', 'e'] >>> lst[2:4] ['c', 'd'] >>> lst[3:] ['d', 'e'] >>> lst[:-3] ['a', 'b'] >>> lst[:-1] ['a', 'b', 'c', 'd'] >>> lst[::2] ['a', 'c', 'e']
Python List Index on 2D Lists
Say, you want to search the row and column index of the value 5 in the array
a = [[1, 2], [3, 4], [5, 6]]
You can simply calculate the x and y coordinates like this:
a = [[1, 2],
[3, 4],
[5, 6]]
row = [x for x in a if 5 in x][0]
x = a.index(row)
y = row.index(5)
print(x, y)
# 2 0Summary
The list.index(value) method finds the index of the first occurrence of the element value in the list. You’ve learned the ins and outs of this important Python list method.
Python List insert()
How can you insert an element at a given index in a given list? Python’s insert() method is your friend.
This tutorial shows you everything you need to know to help you master an essential method of the most fundamental container data type in the Python programming language.
Definition and Usage:
The list.insert(i, element) method adds an element element to an existing list at position i. All elements j>i will be moved by one index position to the right.
Here’s a short example:
>>> lst = [1, 2, 3, 4] >>> lst.insert(3, 99) >>> lst [1, 2, 3, 99, 4]
In the first line of the example, you create the list lst. You then insert the integer element 99 at position 3 of the list. The result is the list with five elements [1, 2, 3, 99, 4].
Try it yourself:
Syntax:
You can call this method on each list object in Python. Here’s the syntax:
list.insert(index, element)
Arguments:
| Argument | Description |
|---|---|
index | Integer value representing the position before you want to insert an element |
element | Object you want to insert into the list. |
Video:
Code Puzzle:
Now you know the basics. Let’s deepen your understanding with a short code puzzle—can you solve it?
# Puzzle # Puzzle created by Finxter Lee lst = [1, 3, 4, 5, 6, 7, 8] lst.insert(1, 2) print(lst) # What's the output of this code snippet?
You can check out the solution on the Finxter app.
Examples:
To help you fully understand the ins and outs of the insert() method, let’s dive into a few more examples.
>>> lst = [1, 2, 3] >>> lst.insert(0, 99) >>> lst [99, 1, 2, 3] >>> lst.insert(-1, 42) >>> lst [99, 1, 2, 42, 3] >>> lst.insert(100, 0) >>> lst [99, 1, 2, 42, 3, 0]
An interesting case is the second one where you use a negative index in the insert() method:
Python List insert() Negative Index
You can use a negative index in the lst.insert(index, element) method. With a negative index you count backwards, starting from the right. In other words, the index -1 stands for the rightmost element in the list. The insert() method inserts the element right in front of the index position. Thus, you get the following behavior where the element is inserted to the second last position:
>>> lst = ["Ann", "Bob", "Alice"] >>> lst.insert(-1, "Liz") >>> lst ['Ann', 'Bob', 'Liz', 'Alice']
What happens if you count further, i.e., -2, -3, or even -99? Let’s check:
>>> lst.insert(-2, "Sam") >>> lst ['Ann', 'Bob', 'Sam', 'Liz', 'Alice']
… and …
>>> lst.insert(-3, "Bob") >>> lst ['Ann', 'Bob', 'Bob', 'Sam', 'Liz', 'Alice']
… and …
>>> lst.insert(-99, "Hans") >>> lst ['Hans', 'Ann', 'Bob', 'Bob', 'Sam', 'Liz', 'Alice']
So you can see that every integer index is allowed! If you overshoot (e.g. -99), it will simply insert at the beginning of the list.
Python List insert() At Beginning
The insert() method allows you to add an element at the beginning of a list. Simply use the index 0 in the call lst.insert(0, element) to add element to the beginning of the lst.
Here’s an example:
>>> lst = [1, 2, 3] >>> lst.insert(0, 99) >>> lst [99, 1, 2, 3]
The insert(i, x) method inserts an element x at position i in the list. This way, you can insert an element to each position in the list—even at the first position. Note that if you insert an element at the first position, each subsequent element will be moved by one position. In other words, element i will move to position i+1.
Python List insert() At End
Okay, you can insert an element at every position in the list—just use the first argument to define the insertion index. Consequently, you can “insert” an element at the end of a list by defining an index that’s greater or equal the size of the list. Remember, insert(index, element) inserts element before the element that’s currently at position index. So if you define an index that’s at least the size of the list, you’ll insert the element at the end of the list:
>>> lst = [1, 2, 3, 4, 5, 6] >>> lst.insert(6, 99) >>> lst [1, 2, 3, 4, 5, 6, 99] >>> lst.insert(100000, 42) >>> lst [1, 2, 3, 4, 5, 6, 99, 42]
No matter your concrete choice of the index argument, as long as it’s larger or equal the current size of the list, your element will be inserted at the end of the list.
However, this doesn’t make a lot of sense considering that you can use the append(element) method which adds an element at the end of the list—and is highly efficient (and readable). Read more about the append() method at my detailed blog article.
Here’s an example adding the same elements 99 and 42 to the end of the list:
>>> lst = [1, 2, 3, 4, 5, 6] >>> lst.append(99) >>> lst.append(42) >>> lst [1, 2, 3, 4, 5, 6, 99, 42]
In Python, there are usually a lot of ways to accomplish the same thing. Using the append() method to add an element to the end of the list is the better way!
Python insert() into Sorted List
How to insert an element into a sorted list (ascending order) and keep the list sorted?
The naive approach is to go over all elements, from first to last, as long as the element to be inserted is still smaller than the current element in the list. As soon as it’s larger, you go back one position and insert it there.
However, the computational complexity of the naive sorted insert algorithm is bad because you need up to n operations to insert an element into a list of n elements.
If you’re interested in the right way of doing it, you can use binary search and the list.insert(i,x) method to insert element x at position i in the list. Here’s the code for the binary search algorithm in Python:
def binary_search(lst, value):
lo, hi = 0, len(lst)-1
while lo <= hi:
mid = (lo + hi) // 2
if lst[mid] < value:
lo = mid + 1
elif value < lst[mid]:
hi = mid - 1
else:
return mid
return -1
l = [3, 6, 14, 16, 33, 55, 56, 89]
x = 56
print(binary_search(l,x))
# 6 (the index of the found element)Don’t worry if the code looks a bit complicated!
Python List insert() Multiple Elements
How can you insert multiple elements into a list? Just call the insert() method multiple times—once for each element to be inserted! But be careful: you must reverse the order of the elements to be inserted first if you keep the insert position constant. Here’s what I mean:
>>> lst = [1, 2, 3, 4] >>> insert = [42, 99] >>> insert.reverse() >>> for el in insert: lst.insert(2, el) >>> lst [1, 2, 42, 99, 3, 4]
You want to insert elements 42 and 99 at position 2 of the list lst, in that order. If you’d just iterate over both elements, you’d first insert element 42 before index 2. Now, element 42 obtains the position 2 in the list. Next, you’d insert element 99 before position 2. Now, element 99 obtains position 2 in the list. So basically, you’ve reversed the original order of the elements to be inserted. Therefore, you have to call the reverse() method first before inserting the elements into the list.
There’s really no better alternative. Of course, you could use list concatenation but that is not as efficient because you’d create a new list rather than modify an existing list:
>>> lst = [1, 2, 3, 4] >>> insert = [42, 99] >>> lst = lst[:2] + insert + lst[2:] >>> lst [1, 2, 42, 99, 3, 4]
This may be more readable but it’s not as efficient because list concatenation creates a new list each time it’s used. If you need to refresh your basic Python slicing skills (e.g. in the operation lst[:2]), check out this detailed blog tutorial.
Python List insert() Complexity
Time Complexity: The insert() method has constant time complexity O(1) no matter the number of elements in the list. The reason is that Python lists are implemented with variable-length array lists so accessing a certain position is fast. Also inserting an element into the array list is fast because you only have to modify the pointers of the preceding and following elements in the list.
Python List insert() vs append()
The difference between the append() and the insert() method is the following:
- the
append(x)method adds new elementxto the end of the list, and - the
insert(i, x)method adds new elementxat positioniin the list. It shifts all subsequent elements one position to the right.
Here’s an example showing both append() and insert() methods in action:
>>> l = [1, 2, 3] >>> l.append(99) >>> l [1, 2, 3, 99] >>> l.insert(2, 42) >>> l [1, 2, 42, 3, 99]
Both methods help you add new elements to the list. But you may ask:
Which is faster, append() or insert()?
All things being equal, the append() method is significantly faster than the insert() method.
Here’s a small script that shows that the append() method has a huge performance advantage over the insert() method when creating a list with 100,000 elements.
import time
l1 = []
l2 = []
t1 = time.time()
for i in range(100000):
l1.append(i)
t2 = time.time()
for i in range(100000):
l2.insert(0,i)
t3 = time.time()
print("append(): " + str(t2 - t1) + " seconds")
print("insert(): " + str(t3 - t2) + " seconds")
# OUTPUT:
# append(): 0.015607357025146484 seconds
# insert(): 1.5420396327972412 secondsThe experiments were performed on my notebook with an Intel(R) Core(TM) i7-8565U 1.8GHz processor (with Turbo Boost up to 4.6 GHz) and 8 GB of RAM.
Alternatives: Python List append() vs extend()
Instead of inserting an element, you can also add a single element to the end of the list using the append() method or even adding multiple elements to the end of the list using the extend() method.
What’s the difference?
I shot a small video explaining the difference and which method is faster, too:
The method list.append(x) adds element x to the end of the list.
The method list.extend(iter) adds all elements in iter to the end of the list.
The difference between append() and extend() is that the former adds only one element and the latter adds a collection of elements to the list.
You can see this in the following example:
>>> l = [] >>> l.append(1) >>> l.append(2) >>> l [1, 2] >>> l.extend([3, 4, 5]) >>> l [1, 2, 3, 4, 5]
In the code, you first add integer elements 1 and 2 to the list using two calls to the append() method. Then, you use the extend method to add the three elements 3, 4, and 5 in a single call of the extend() method.
Which method is faster — extend() vs append()?
To answer this question, I’ve written a short script that tests the runtime performance of creating large lists of increasing sizes using the extend() and the append() methods.
Our thesis is that the extend() method should be faster for larger list sizes because Python can append elements to a list in a batch rather than by calling the same method again and again.
I used my notebook with an Intel(R) Core(TM) i7-8565U 1.8GHz processor (with Turbo Boost up to 4.6 GHz) and 8 GB of RAM.
Then, I created 100 lists with both methods, extend() and append(), with sizes ranging from 10,000 elements to 1,000,000 elements. As elements, I simply incremented integer numbers by one starting from 0.
Here’s the code I used to measure and plot the results: which method is faster—append() or extend()?
import time
def list_by_append(n):
'''Creates a list & appends n elements'''
lst = []
for i in range(n):
lst.append(n)
return lst
def list_by_extend(n):
'''Creates a list & extends it with n elements'''
lst = []
lst.extend(range(n))
return lst
# Compare runtime of both methods
list_sizes = [i * 10000 for i in range(100)]
append_runtimes = []
extend_runtimes = []
for size in list_sizes:
# Get time stamps
time_0 = time.time()
list_by_append(size)
time_1 = time.time()
list_by_extend(size)
time_2 = time.time()
# Calculate runtimes
append_runtimes.append((size, time_1 - time_0))
extend_runtimes.append((size, time_2 - time_1))
# Plot everything
import matplotlib.pyplot as plt
import numpy as np
append_runtimes = np.array(append_runtimes)
extend_runtimes = np.array(extend_runtimes)
print(append_runtimes)
print(extend_runtimes)
plt.plot(append_runtimes[:,0], append_runtimes[:,1], label='append()')
plt.plot(extend_runtimes[:,0], extend_runtimes[:,1], label='extend()')
plt.xlabel('list size')
plt.ylabel('runtime (seconds)')
plt.legend()
plt.savefig('append_vs_extend.jpg')
plt.show()The code consists of three high-level parts:
- In the first part of the code, you define two functions
list_by_append(n)andlist_by_extend(n)that take as input argument an integer list sizenand create lists of successively increasing integer elements using theappend()andextend()methods, respectively. - In the second part of the code, you compare the runtime of both functions using 100 different values for the list size
n. - In the third part of the code, you plot everything using the Python matplotlib library.
Here’s the resulting plot that compares the runtime of the two methods append() vs extend(). On the x axis, you can see the list size from 0 to 1,000,000 elements. On the y axis, you can see the runtime in seconds needed to execute the respective functions.
The resulting plot shows that both methods are extremely fast for a few tens of thousands of elements. In fact, they are so fast that the time() function of the time module cannot capture the elapsed time.
But as you increase the size of the lists to hundreds of thousands of elements, the extend() method starts to win:
For large lists with one million elements, the runtime of the extend() method is 60% faster than the runtime of the append() method.
The reason is the already mentioned batching of individual append operations.
However, the effect only plays out for very large lists. For small lists, you can choose either method. Well, for clarity of your code, it would still make sense to prefer extend() over append() if you need to add a bunch of elements rather than only a single element.
Python List insert() Returns None
The return value of the insert() method is None. The return value of the insert() method is not a modified list with the added elements. Assuming this is a common source of mistakes.
Here’s such an error where the coder wrongly assumed this:
>>> lst = [1, 2].insert(1, 99)
>>> lst[0]
Traceback (most recent call last):
File "<pyshell#16>", line 1, in <module>
lst[0]
TypeError: 'NoneType' object is not subscriptable It doesn’t make sense to assign the result of the insert() method to another variable—because it’s always None. Instead, the insert() method changes a list object without creating (and returning) a new list.
Here’s the correct version of the same code:
>>> lst = [1, 2] >>> lst.insert(1, 99) >>> lst[1] 99
Now, you change the list object itself by calling the insert() method on it. You through away the None return value because it’s not needed.
Python List insert() Return New List
If you use the lst.insert(index, element) operation, you add the element to the existing list lst. But what if you want to create a new list where all elements were added?
The answer is simply to use the list concatenation operation lst[:index] + [element] + lst[index:] which creates a new list each time it is used. The original list lst will not be affected by the list concatenation operation.
Here’s an example that shows that the insert() method only modifies an existing list:
>>> lst_1 = [1, 2, 3] >>> lst_2 = lst_1.insert(1, 42) >>> lst_1 [1, 42, 2, 3] >>> lst_2 None
And here’s the example that shows how to create a new list inserting element 42 at index 2:
>>> lst_1 = [1, 2, 3] >>> lst_2 = lst_1[:1] + [42] + lst_1[1:] >>> lst_1 [1, 2, 3] >>> lst_2 [1, 42, 2, 3]
By using the list concatenation operation, you can create a new list rather than inserting the element into an existing list.
Summary
The list.insert(index, element) method inserts an element to the end of the list before the given index position.
Python List pop()
This tutorial shows you everything you need to know to help you master the essential pop() method of the most fundamental container data type in the Python programming language.
Definition and Usage:
The list.pop() method removes and returns the last element from an existing list. The list.pop(index) method with the optional argument index removes and returns the element at the position index.
Here’s a short example:
>>> lst = [1, 2, 3] >>> lst.pop() 3 >>> lst [1, 2]
In the first line of the example, you create the list lst. You then remove and return the final element 3 from the list. The result is the list with only two elements [1, 2].
Code Puzzle — Try It Yourself:
Now you know the basics. Let’s deepen your understanding with a short code puzzle—can you solve it?
You can also solve this puzzle and track your Python skills on our interactive Finxter app.
Syntax:
You can call this method on each list object in Python. Here’s the syntax:
list.pop(index=-1)
Arguments:
| Argument | Description |
|---|---|
index | Optional argument. You can define the index of the element to be removed and returned. The default argument leads to the removal of the last list element with index -1. |
Return value:
The method list.pop() has return value Object. It removes the particular element from the list (default: the last element) and returns it directly to the caller.
Video:
Python List pop() By Index
You can use the list.pop(index) method to with the optional index argument to remove and return the element at position index from the list.
Here’s an example:
>>> customers = ['Alice', 'Bob', 'Ann', 'Frank'] >>> customers.pop(2) 'Ann' >>> customers ['Alice', 'Bob', 'Frank'] >>> customers.pop(0) 'Alice' >>> customers ['Bob', 'Frank']
After creating the list with four elements, you first remove and return the second element 'Ann'. Then, you remove and return the first element 'Alice'. The resulting list has only two elements left.
Python List pop() First / Front / Left / Head
The list.pop(index) method to with the optional index argument to remove and return the element at position index from the list. So if you want to remove the first element from the list, simply set index=0 by calling list.pop(0). This will pop the first element from the list.
Here’s an example:
>>> primes = [1, 2, 3, 5, 7, 11] >>> primes.pop(0) 1 >>> primes [2, 3, 5, 7, 11]
The pop(0) method removes the first element 1 from the list of prime numbers given in the example.
Python List pop() By Value
In the previous two examples, you’ve seen how to pop elements by index. But can you also pop by value?
Yes, you can by using the list.index(value) method which gives you the index of the element value in the list. Now, you can use the list.pop(index) method on this index to remove the value from the list and get the result as a return value.
Here’s an example where you want to pop the element 7 from the list and store the result in the variable some_prime.
>>> primes = [1, 2, 3, 5, 7, 11] >>> some_prime = primes.pop(primes.index(7)) >>> some_prime 7
If you’re not interested in the return value but you only want to remove the first occurrence of the value x in the list, use the list.remove(x) method.
Related Article:
Python List pop() Multiple Elements
If you can pop one element from a Python list, the natural question is if you can also pop multiple elements at the same time?
The answer no. You cannot directly pop multiple element from a list. But you can do it indirectly with a simple list comprehension statement.
Python List pop() First n Elements
Say, you want to pop the first n elements from a list. How do you do this?
You simply create a list of values using list comprehension [list.pop(0) for i in range(n)] to remove and return the first n elements of the list.
Here’s another example:
>>> lst = ['a', 'b', 'c', 'd', 'e', 'f'] >>> popped = [lst.pop(0) for i in range(5)] >>> popped ['a', 'b', 'c', 'd', 'e'] >>> lst ['f']
The popped list contains the first five elements. The original list has only one element left.
Python List pop() Last n Elements
Say, you want to pop the last n elements from a list. How do you do this?
You simply create a list of values using list comprehension [list.pop() for i in range(n)] to remove and return the last n elements of the list.
Here’s another example:
>>> lst = ['a', 'b', 'c', 'd', 'e', 'f'] >>> [lst.pop() for i in range(5)] ['f', 'e', 'd', 'c', 'b'] >>> lst ['a']
The popped list contains the last five elements. The original list has only one element left.
Python List pop() Time Complexity
The time complexity of the pop() method is constant O(1). No matter how many elements are in the list, popping an element from a list takes the same time (plus minus constant factors).
The reason is that lists are implemented with arrays in cPython. Retrieving an element from an array has constant complexity. Removing the element from the array also has constant complexity. Thus, retrieving and removing the element as done by the pop() method has constant runtime complexity too.
I’ve written a short script to evaluate runtime complexity of the pop() method in Python:
import matplotlib.pyplot as plt
import time
y = []
for i in [100000 * j for j in range(5,15)]:
lst = list(range(i))
t0 = time.time()
x = lst.pop(0)
t1 = time.time()
y.append(t1-t0)
plt.plot(y)
plt.xlabel("List elements (10**5)")
plt.ylabel("Time (sec)")
plt.show()The resulting plot shows that the runtime complexity is linear, even if the number of elements increases drastically:

(Okay, there are some bumps but who really cares?)
Note that the runtime complexity is still linear if we pop the last element or any other arbitrary element from the list.
Python List pop() vs remove()
What’s the difference between the list.pop() and the list.remove() methods?
- The
list.remove(element)method removes the first occurrence of theelementfrom an existinglist. It does not, however, remove all occurrences of the element in the list! - The
list.pop()method removes and returns the last element from an existinglist. Thelist.pop(index)method with the optional argumentindexremoves and returns the element at the positionindex.
So, the remove method removes by value and the pop method removes by index. Also, the remove method returns nothing (it operates on the list itself) and the pop method returns the removed object.
Python List Pop and Push (Stack)
Python doesn’t have a built-in stack data structure because it’s not needed. You can simply create an empty list and call it stack. Then, you use the stack.append(x) method to push element x to the stack. And you sue the stack.pop() method to push the topmost element from the stack.
Here’s an example that shows how to push three values to the stack and then removing them in the traditional First-In Last-Out (FILO) order of stacks.
>>> stack = []
>>> stack.append(5)
>>> stack.append(42)
>>> stack.append("Ann")
>>> stack.pop()
'Ann'
>>> stack.pop()
42
>>> stack.pop()
5
>>> stack
[]Python List pop() Without Remove
Want to pop() an element from a given list without removing it? Don’t do it! Instead, use simple indexing. To get an element with index i from list, simply use indexing scheme list[i]. This will keep the original element in the list without removing it.
Python List pop() If Not Empty
How can you pop() an element only if the list is not empty in a single line of code? Use the ternary operator in Python lst.pop() if lst else None as follows:
>>> lst = [1, 2, 3] >>> for i in range(5): print(lst.pop() if lst else None) 3 2 1 None None
You try to pop the leftmost element five times from a list with only three values. However, there’s no error message because of your proficient use of the ternary operator that checks in a single line if the list is empty. If it is empty, it doesn’t pop but return the None value.
If you don’t use the ternary operator in this example, Python will throw an IndexError as you try to pop from an empty list:
>>> lst = [1, 2, 3]
>>> for i in range(5):
print(lst.pop())
3
2
1
Traceback (most recent call last):
File "<pyshell#15>", line 2, in <module>
print(lst.pop())
IndexError: pop from empty listPython List pop() Slice
Can you pop a whole slice at once? Well, you can remove a whole slice by using the del keyword: to remove slice lst[start:stop] from the list, you can call del lst[start:stop]. However, you won’t get the slice as a return value so you may want to store the slice in a separate variable first, before removing it from the list.
Python List pop() While Iterating
It’s always dangerous to change a list over which you currently iterate.
Why? Because the iterator is created only once in the loop definition and it will stubbornly give you the indices it prepared in the beginning. If the loop changes, the indices of the elements change, too. But the iterator doesn’t adapt the indices to account for those changes. Here’s an example:
>>> lst = list(range(10))
>>> for i in range(len(lst)):
lst.pop(i)
0
2
4
6
8
Traceback (most recent call last):
File "<pyshell#20>", line 2, in <module>
lst.pop(i)
IndexError: pop index out of rangeWow—this was unexpected, wasn’t it? You popped only every second element from the list. Why? Because in the first iteration, the index variable i=0. Now, we remove this from the list. The element 1 in the list has now index 0 after removal of the previous leading element. But in the second loop iteration, the loop variable has index i=1. This is the next element to be popped. But you have skipped popping the element 1 from the list at position index 0! Only every other element is popped as a result.
Alternatives Ways to Remove Elements From a List
There are some alternative ways to remove elements from the list. See the overview table:
| Method | Description |
|---|---|
lst.remove(x) | Remove an element from the list (by value) |
lst.pop() | Remove an element from the list (by index) and return the element |
lst.clear() | Remove all elements from the list |
del lst[3] | Remove one or more elements from the list (by index or slice) |
| List comprehension | Remove all elements that meet a certain condition |
Next, you’ll dive into each of those methods to gain some deep understanding.
remove() — Remove An Element by Value
To remove an element from the list, use the list.remove(element) method you’ve already seen previously:
>>> lst = ["Alice", 3, "alice", "Ann", 42]
>>> lst.remove("Ann")
>>> lst
['Alice', 3, 'alice', 42]Try it yourself:
The method goes from left to right and removes the first occurrence of the element that’s equal to the one to be removed.
Removed Element Does Not Exist
If you’re trying to remove element x from the list but x does not exist in the list, Python throws a Value error:
>>> lst = ['Alice', 'Bob', 'Ann']
>>> lst.remove('Frank')
Traceback (most recent call last):
File "<pyshell#19>", line 1, in <module>
lst.remove('Frank')
ValueError: list.remove(x): x not in listpop() — Remove An Element by Index
Per default, the pop() method removes the last element from the list and returns the element.
>>> lst = ['Alice', 'Bob', 'Ann'] >>> lst.pop() 'Ann' >>> lst ['Alice', 'Bob']
But you can also define the optional index argument. In this case, you’ll remove the element at the given index—a little known Python secret!
>>> lst = ['Alice', 'Bob', 'Ann'] >>> lst.pop(1) 'Bob' >>> lst ['Alice', 'Ann']
clear() — Remove All Elements
The clear() method simply removes all elements from a given list object.
>>> lst = ['Alice', 'Bob', 'Ann'] >>> lst.clear() >>> lst []
del — Remove Elements by Index or Slice
This trick is also relatively unknown among Python beginners:
- Use
del lst[index]to remove the element at index. - Use
del lst[start:stop]to remove all elements in the slice.
>>> lst = list(range(10)) >>> lst [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> del lst[5] >>> lst [0, 1, 2, 3, 4, 6, 7, 8, 9] >>> del lst[:4] >>> lst [4, 6, 7, 8, 9]
Related blog articles:
List Comprehension — Remove Elements Conditionally
Okay, this is kind of cheating because this method does not really remove elements from a list object. It merely creates a new list with some elements that meet your condition.
List comprehension is a compact way of creating lists. The simple formula is [ expression + context ].
- Expression: What to do with each list element?
- Context: What list elements to select? It consists of an arbitrary number of for and if statements.
The example [x for x in range(3)] creates the list [0, 1, 2].
You can also define a condition such as all odd values x%2==1 in the context part by using an if condition. This leads us to a way to remove all elements that do not meet a certain condition in a given list.
>>> lst = list(range(10)) >>> lst_new = [x for x in lst if x%2] >>> lst_new [1, 3, 5, 7, 9]
While you iterate over the whole list lst, the condition x%2 requires that the elements are odd.
Related blog articles:
Summary
The list.remove(element) method removes the first occurrence of element from the list.
Python List remove()
This tutorial shows you everything you need to know to help you master the essential remove() method of the most fundamental container data type in the Python programming language.
Definition and Usage:
The list.remove(element) method removes the first occurrence of the element from an existing list. It does not, however, remove all occurrences of the element in the list!
Here’s a short example:
>>> lst = [1, 2, 99, 4, 99] >>> lst.remove(99) >>> lst [1, 2, 4, 99]
In the first line of the example, you create the list lst. You then remove the integer element 99 from the list—but only its first occurrence. The result is the list with only four elements [1, 2, 4, 99].
Try it yourself:
Syntax:
You can call this method on each list object in Python. Here’s the syntax:
list.remove(element)
Arguments:
| Argument | Description |
|---|---|
element | Object you want to remove from the list. Only the first occurrence of the element is removed. |
Return value:
The method list.remove(element) has return value None. It operates on an existing list and, therefore, doesn’t return a new list with the removed element
Video:
Code Puzzle:
Now you know the basics. Let’s deepen your understanding with a short code puzzle—can you solve it?
# Puzzle
presidents = ['Obama',
'Trump',
'Washington']
p2 = presidents[:2]
p2.remove('Trump')
print(presidents)
# What's the output of this code snippet?You can check out the solution on the Finxter app.
Overview:
There are some alternative ways to remove elements from the list. See the overview table:
| Method | Description |
|---|---|
lst.remove(x) | Remove an element from the list (by value) |
lst.pop() | Remove an element from the list (by index) and return the element |
lst.clear() | Remove all elements from the list |
del lst[3] | Remove one or more elements from the list (by index or slice) |
| List comprehension | Remove all elements that meet a certain condition |
Next, you’ll dive into each of those methods to gain some deep understanding.
remove() — Remove An Element by Value
To remove an element from the list, use the list.remove(element) method you’ve already seen previously:
>>> lst = ["Alice", 3, "alice", "Ann", 42]
>>> lst.remove("Ann")
>>> lst
['Alice', 3, 'alice', 42]Try it yourself:
The method goes from left to right and removes the first occurrence of the element that’s equal to the one to be removed.
Removed Element Does Not Exist
If you’re trying to remove element x from the list but x does not exist in the list, Python throws a Value error:
>>> lst = ['Alice', 'Bob', 'Ann']
>>> lst.remove('Frank')
Traceback (most recent call last):
File "<pyshell#19>", line 1, in <module>
lst.remove('Frank')
ValueError: list.remove(x): x not in listpop() — Remove An Element by Index
Per default, the pop() method removes the last element from the list and returns the element.
>>> lst = ['Alice', 'Bob', 'Ann'] >>> lst.pop() 'Ann' >>> lst ['Alice', 'Bob']
But you can also define the optional index argument. In this case, you’ll remove the element at the given index—a little known Python secret!
>>> lst = ['Alice', 'Bob', 'Ann'] >>> lst.pop(1) 'Bob' >>> lst ['Alice', 'Ann']
clear() — Remove All Elements
The clear() method simply removes all elements from a given list object.
>>> lst = ['Alice', 'Bob', 'Ann'] >>> lst.clear() >>> lst []
del — Remove Elements by Index or Slice
This trick is also relatively unknown among Python beginners:
- Use
del lst[index]to remove the element at index. - Use
del lst[start:stop]to remove all elements in the slice.
>>> lst = list(range(10)) >>> lst [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> del lst[5] >>> lst [0, 1, 2, 3, 4, 6, 7, 8, 9] >>> del lst[:4] >>> lst [4, 6, 7, 8, 9]
Related blog articles:
List Comprehension — Remove Elements Conditionally
Okay, this is kind of cheating because this method does not really remove elements from a list object. It merely creates a new list with some elements that meet your condition.
List comprehension is a compact way of creating lists. The simple formula is [ expression + context ].
- Expression: What to do with each list element?
- Context: What list elements to select? It consists of an arbitrary number of for and if statements.
The example [x for x in range(3)] creates the list [0, 1, 2].
You can also define a condition such as all odd values x%2==1 in the context part by using an if condition. This leads us to a way to remove all elements that do not meet a certain condition in a given list.
>>> lst = list(range(10)) >>> lst_new = [x for x in lst if x%2] >>> lst_new [1, 3, 5, 7, 9]
While you iterate over the whole list lst, the condition x%2 requires that the elements are odd.
Related blog articles:
Python List remove() All
The list.remove(x) method only removes the first occurrence of element x from the list.
But what if you want to remove all occurrences of element x from a given list?
The answer is to use a simple loop:
lst = ['Ann', 'Ann', 'Ann', 'Alice', 'Ann', 'Bob']
x = 'Ann'
while x in lst:
lst.remove(x)
print(lst)
# ['Alice', 'Bob']You simply call the remove() method again and again until element x is not in the list anymore.
Python List Remove Duplicates
How to remove all duplicates of a given value in the list?
The naive approach is to go over each element and check whether this element already exists in the list. If so, remove it. However, this takes a few lines of code.
A shorter and more concise way is to create a dictionary out of the elements in the list. Each list element becomes a new key to the dictionary. All elements that occur multiple times will be assigned to the same key. The dictionary contains only unique keys—there cannot be multiple equal keys.
As dictionary values, you simply take dummy values (per default).
Related blog articles:
Then, you simply convert the dictionary back to a list throwing away the dummy values. As the dictionary keys stay in the same order, you don’t lose the order information of the original list elements.
Here’s the code:
>>> lst = [1, 1, 1, 3, 2, 5, 5, 2]
>>> dic = dict.fromkeys(lst)
>>> dic
{1: None, 3: None, 2: None, 5: None}
>>> duplicate_free = list(dic)
>>> duplicate_free
[1, 3, 2, 5]Python List remove() If Exists
How to remove an element from a list—but only if it exists?
The problem is that if you try to remove an element from the list that doesn’t exist, Python throws a Value Error. You can avoid this by checking the membership of the element to be removed first:
>>> lst = ['Alice', 'Bob', 'Ann']
>>> lst.remove('Frank') if 'Frank' in lst else None
>>> lst
['Alice', 'Bob', 'Ann']This makes use of the Python one-liner feature of conditional assignment (also called the ternary operator).
Related blog articles:
Summary
The list.remove(element) method removes the first occurrence of element from the list.
Python List reverse()
This tutorial shows you everything you need to know to help you master the essential reverse() method of the most fundamental container data type in the Python programming language.
Definition and Usage:
The list.reverse() reverses the order of the elements in the list. If you want to create a new list with reversed elements, use slicing with negative step size list[::-1].
Here’s a short example:
>>> lst = [1, 2, 3, 4] >>> lst.reverse() >>> lst [4, 3, 2, 1]
In the first line of the example, you create the list lst. You then reverse the order of the elements in the list and print it to the shell.
Code Puzzle — Try It Yourself:
Now you know the basics. Let’s deepen your understanding with a short code puzzle—can you solve it?
You can also solve this puzzle and track your Python skills on our interactive Finxter app.
Syntax: You can call this method on each list object in Python. Here’s the syntax:
list.reverse()
Arguments: The reverse method doesn’t take any arguments.
Return value: The method list.reverse() has return value None. It reverses the elements of the list in place (but doesn’t create a new list). Thus, a return value is not needed.
Python List reverse() Time Complexity
The time complexity of the reverse() operation is O(n) for a list with n elements. The standard Python implementation cPython “touches” all elements in the original list to move them to another position. Thus, the time complexity is linear in the number of list elements.
You can see a plot of the time complexity of the reverse() method for growing list size here:
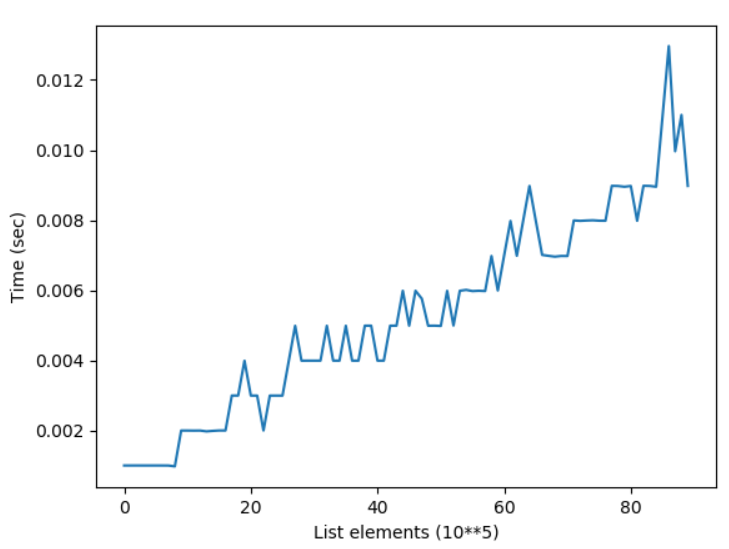
The figure shows how the elapsed time of reversing lists with growing number of elements grows linear to the number of elements.
If you’re interested in the code I used to generate this plot with Matplotlib, this is it:
import matplotlib.pyplot as plt
import time
y = []
for i in [100000 * j for j in range(10,100)]:
lst = list(range(i))
t0 = time.time()
x = lst.reverse()
t1 = time.time()
y.append(t1-t0)
plt.plot(y)
plt.xlabel("List elements (10**5)")
plt.ylabel("Time (sec)")
plt.show()Python List reverse() In Place
If you call the list.reverse() method on any list object in Python, it reverses the list elements of this particular list object. You say that the reverse method happens in place.
This is a common mistake of many Python beginners. They assume that the reverse() method creates a new list with the elements in reversed order. This is not the case: the reverse() method modifies only the existing list object.
You can see this in the following example:
>>> lst = [1, 2, 3] >>> lst.reverse() >>> lst [3, 2, 1]
In the example, you only reversed the existing list lst. But you didn’t create a new list!
Python List reverse() None
The return value of the list.reverse() method is None. Why? Because the method reverses the list in place. This means that no new list is created. Instead, the method modifies the old list object.
You’ve seen an example of this in the previous section.
Python List Reverse List Without reverse()
You can also reverse a list without using the reverse() method. Let’s have a look at the following table that shows all reverse() alternatives:
| Method | Description |
|---|---|
lst.reverse() | Reverses the order of the elements of list lst in place. |
list(reversed(lst)) | The built-in reversed(lst) method creates a new list object with reversed list elements. |
lst[::-1] | Slicing with negative indexing is the most concise way of reversing the order of a list. It creates a new list object. |
[lst[i] for i in range(len(lst)-1,-1,-1)] | Just for fun—one-liner solution to reverse a list using list comprehension and the negative range function. |
There is a fifth solution using recursion. But it’s highly inefficient and you shouldn’t use it in practice. If you want to learn about it anyways, read on. But don’t tell me you haven’t been warned!
Python List Reverse Recursive
You can create a recursive function to reverse any list. I’ll give you the code first and explain it later:
>>> reverse = lambda lst: reverse(lst[1:]) + [lst[0]] if lst else []
Let’s check if it does what it’s supposed to do (reversing the list):
>>> reverse([1, 2, 3]) [3, 2, 1] >>> reverse(["Ann", 1, 42, 0]) [0, 42, 1, 'Ann'] >>> reverse([]) [] >>> reverse([1]) [1]
Okay, it works!
The recursive one-liner solution uses several Python features you have to understand before you can understand it entirely:
- The lambda function
lambda x: ycreates an anonymous function with argumentxand return valuey. You can read the detailed tutorial on the Finxter blog. - List concatenation
[a, b, c] + [d]creates the new list[a, b, c, d]. You can read the detailed tutorial on the Finxter blog. - Slicing
lst[start:stop]carves out a subsequence from the list between thestartandstopindices. You can read the detailed tutorial on the Finxter blog. - The ternary operator
x if y else zreturns the valuexifyisTrue. In all other cases, it returns the valuez. You can read the detailed tutorial on the Finxter blog.
Phew! Quite some information to digest! But that’s not all. If you’ve understood all of the above, you also need to understand recursion. That’s too much to teach in a single paragraph so I’d send you over to my blog article about recursion.
I’ll say only that much: to understand recursion, you first need to understand recursion! 😉
Python List Reverse Slice
Slicing is the easiest way to reverse a list.
To reverse the list lst, you simply use slicing operation lst[::-1] with default start and stop indices (not given) and negative step size -1 (given).
There’s only one case where you shouldn’t use slicing to reverse the list and this is if you don’t want to create a new list. In this case, stick to the lst.reverse() method which reverses the list in place.
Here’s an example of slicing to reverse a given list:
>>> friends = ["Ann", "Carsten", "Bob", "Alice"] >>> r_friends = friends[::-1] >>> friends ['Ann', 'Carsten', 'Bob', 'Alice'] >>> r_friends ['Alice', 'Bob', 'Carsten', 'Ann']
You see that the two lists friends and r_friends are independent objects in memory because the slicing operation creates a new list.
Related articles:
Python List Reverse Copy
There are two ways to copy a list and reverse the order of its elements:
- Use slicing
list[::-1], or - Call the
reversed(list)method and convert the result to a list using thelist(...)constructor.
Here are both in action:
>>> lst_1 = ['Alice', 'Bob', 'Ann'] >>> lst_2 = lst_1[::-1] >>> lst_3 = list(reversed(lst_1)) >>> lst_1 ['Alice', 'Bob', 'Ann'] >>> lst_2 ['Ann', 'Bob', 'Alice'] >>> lst_3 ['Ann', 'Bob', 'Alice']
Python List Partial Reverse
To partially reverse a list lst, use slicing with negative step size: lst[start:stop:-1]. The start and stop values define the part of the list to be reversed and the step size -1 means that you go through the list in reversed order.
Here’s an example of some partial list reversals:
>>> lst = ['a', 'b', 'c', 'd', 'e'] >>> lst[5:2:-1] ['e', 'd'] >>> lst[:1:-1] ['e', 'd', 'c'] >>> lst[3:2:-1] ['d']
All of those slicing operations reversed a subsequence of the original list. Note that the start index must be larger or equal than the stop index because you traverse the list in negative order (well, if you don’t want to have an empty slice object).
Python List Reverse List Comprehension
You can reverse a list with Python’s powerful list comprehension method. (Although I cannot imagine a scenario where this would actually make sense.)
Related article:
List comprehension is a compact way of creating lists. The simple formula is [ expression + context ].
- Expression: What to do with each list element?
- Context: What list elements to select? It consists of an arbitrary number of for and if statements.
For example, the expression [x for x in range(3)] creates the list [0, 1, 2].
Here’s how you’d use list comprehension to reverse a list:
[lst[i] for i in range(len(lst)-1,-1,-1)]
You go over all indices in negative order—starting with the last list index len(lst)-1 and ending in the first list index 0. Note that the stop index is not included in the index sequence so I used the value -1 as the stop index for the range() built-in function.
Python List reverse() vs reversed()
What’s the difference between the method list.reverse() and the built-in function reversed(list)?
list.reverse()modifies an existing list in place and reverses the order of elements in this list object. No new list object is created.reversed(list)creates a new iterable object by reversing the order of elements of the originallist.
So you should use the former if you don’t want to create a new list and the latter if you want to create a new iterable without modifying the existing list.
An example is the following:
>>> lst_1 = [1, 2, 3] >>> lst_1.reverse() >>> lst_1 [3, 2, 1] >>> reversed(lst_1) <list_reverseiterator object at 0x0000025B58FEC9B0>
The output is not very intuitive but it only means that the reversed() function returns an iterable object.
Python List Deep Reverse
What if you want not only to reverse a list but running a deep reverse where all nested lists are also reversed in a recursive manner?
Here’s how you can do it:
def deep_reverse(lst):
''' Reverses a nested list in place'''
# Reverse top-level list
lst.reverse()
# Recursively reverse all nested lists
for element in lst:
if isinstance(element, list):
deep_reverse(element)
lst = [1, 2, 3, [4, 5, 6]]
deep_reverse(lst)
print(lst)This generates the output:
# OUTPUT: [[6, 5, 4], 3, 2, 1]
Not only the first-level list is reversed but also the second-level list. The code is loosely inspired from this article.
Python List Reverse Enumerate
The enumerate(list) built-in function returns a list of tuples with the first tuple value being the list index and the second tuple value being the list element.
You can reverse the order of enumerated tuples by stacking together the enumerate() function and the list.reverse() method as follows:
>>> for i, el in enumerate(list(reversed([1, 2, 3]))): print(i, el) 0 3 1 2 2 1
This way, you first reverse the list which creates an iterator. You then transform it into a list. The result can be enumerated.
If you want to reverse the order of the indices as well, simply switch the order of both functions:
>>> for i, el in reversed(list(enumerate([1, 2, 3]))): print(i, el) 2 3 1 2 0 1
By first enumerating, you calculate the indices based on the original list. Then you reverse them in the outer function.
Python List Reverse Iterator
The reversed(list) method returns an iterator, not a new list. This is different: an iterator is more efficient than a list. You can easily convert the iterator object into a list by using the list(...) built-in function.
Here’s an example:
>>> reversed([1, 2, 3]) <list_reverseiterator object at 0x0000021735E070B8> >>> for i in reversed([1, 2, 3]): print(i) 3 2 1
The iterator object doesn’t look pretty in the shell but it’s a more efficient way to iterate over a sequence of values than using lists. Why? Because lists need to maintain all values in memory. Iterators don’t.
Python List Reverse Sort
Do you want to sort a list in descending order? Use the reverse=True argument of the sorted() method. Here’s an example:
>>> sorted([42, 1, 99]) [1, 42, 99] >>> sorted([42, 1, 99], reverse=True) [99, 42, 1]
Python List reverse() Index
Rather than just using positive list indices, you can use reverse indexing in Python lists, too. The negative integer index -1 accesses the last element. The negative integer index -2 accesses the second last element and so on. Here’s an example:
>>> lst = ["Alice", "Bob", "Ann"] >>> lst[-1] 'Ann' >>> lst[-2] 'Bob' >>> lst[-3] 'Alice'
Python List Reverse range()
Do you want to iterate over a range of integer values in reverse order? Say, you want to iterate over the numbers from 10 to 0 in reverse order: 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0. You can simply achieve this by specifying the start, stop, and step arguments of the range(start, stop, step) method:
>>> for i in range(10, -1, -1): print(i) 10 9 8 7 6 5 4 3 2 1 0
Note that the start argument is included in the range but the stop argument isn’t.
Python List reverse() Doesn’t Work
What if the reverse() method doesn’t work? Chances are that you assume the list.reverse() method has a return value—that is the reversed list. This is not the case! The list.reverse() method returns None because it reverses the list in place. It doesn’t return a new reversed list.
Here’s an example what you’re probably doing:
>>> lst = [1, 2, 3] >>> print(lst) [1, 2, 3] >>> print(lst.reverse()) None
If you really want to have a new list with elements in reversed order, use the Python built-in reversed(list) method:
>>> print(list(reversed([1, 2, 3]))) [3, 2, 1]
The reversed() method reverses the list and returns the reversed list as an iterator object. You need to convert it to a list first before printing it to the shell (and receiving a meaningful output).
Python Reverse List NumPy
To reverse a NumPy array (or even a Python list), you can simply use slicing with negative step size a[::-1]. Here’s an example:
>>> import numpy as np >>> a = np.array([1, 2, 3]) >>> a[::-1] array([3, 2, 1])
Summary
The list.reverse() method reverses the order of the list elements.
Python List sort()
Every computer scientist loves sorting things. In this article, I’ll show you how Python does it—and how you can tap into the powerful sorting features of Python lists.
Definition and Usage: The list.sort() method sorts the list elements in place in an ascending manner. To customize the default sorting behavior, use the optional key argument by passing a function that returns a comparable value for each element in the list. With the optional Boolean reverse argument, you can switch from ascending (reverse=False) to descending order (reverse=True).
Here’s a short overview example that shows you how to use the arguments in practice:
# Create an unsorted integer list lst = [88, 12, 42, 11, 2] # Sort the list in place (ascending) lst.sort() print(lst) # [2, 11, 12, 42, 88] # Sort the list (leading number) lst.sort(key=lambda x: str(x)[0]) print(lst) # [11, 12, 2, 42, 88] # Sort the list in place (descending) lst.sort(reverse=True) print(lst) # [88, 42, 12, 11, 2]
In the first line of the example, you create the list lst. You then sort the list once using the default sorting behavior and once using a customized sorting behavior with only the first letter of the number. You then reverse the order of the elements in the sorted list using the reverse=True argument.
Code Puzzle — Try It Yourself:
Now you know the basics. Let’s deepen your understanding with a short code puzzle—can you solve it?
You can also solve this puzzle and track your Python skills on our interactive Finxter app.
Syntax: You can call this method on each list object in Python (Python versions 2.x and 3.x). Here’s the syntax:
list.sort(key=None, reverse=False)
Arguments:
| Argument | Description |
|---|---|
key | (Optional. Default None.) Pass a function that takes a single argument and returns a comparable value. The function is then applied to each element in the list. Then, the method sorts based on the key function results rather than the elements themselves. |
reverse | (Optional. Default False.) The order of the list elements. If False, sorting is in ascending order. If True, it’s in descending order. |
Return value: The method list.sort() returns None, no matter the list on which it’s called. Why? Because it sorts a list in-place and doesn’t create a new list.
Related article: Python List Methods [Overview]
Python List Sort Key

The list.sort() method takes another function as an optional key argument that allows you to modify the default sorting behavior. The key function is then called on each list element and returns another value based on which the sorting is done. Hence, the key function takes one input argument (a list element) and returns one output value (a value that can be compared).
Here’s an example:
>>> lst = [(1,2), (3,2), (3,3), (1,0), (0,1), (4,2), (1,1), (0,2), (0,0)] >>> lst.sort() >>> lst [(0, 0), (0, 1), (0, 2), (1, 0), (1, 1), (1, 2), (3, 2), (3, 3), (4, 2)] >>> lst.sort(key=lambda x: x[0]) >>> lst [(0, 0), (0, 1), (0, 2), (1, 0), (1, 1), (1, 2), (3, 2), (3, 3), (4, 2)] >>> lst.sort(key=lambda x: x[1]) >>> lst [(0, 0), (1, 0), (0, 1), (1, 1), (0, 2), (1, 2), (3, 2), (4, 2), (3, 3)]
You can see that in the first two examples, the list is sorted according to the first tuple value first. In the third example, the list is sorted according to the second tuple value first. You achieve this by defining a key function key=lambda x: x[1] that takes one list element x (a tuple) as an argument and transforms it into a comparable value x[1] (the second tuple value).
Related article:
Python List Sort Itemgetter
You can use any function as a key function that transforms one element into another (comparable) element.
For example, it’s common to use the itemgetter() function from the operator module to access the i-th value of an iterable:
>>> from operator import itemgetter
>>> customers = [('alice', 1000), ('bob', 100), ('frank', 10)]
>>> customers.sort(key=itemgetter(1))
[('frank', 10), ('bob', 100), ('alice', 1000)]The itemgetter() function does exactly the same as the lambda function in the previous example: it returns the second tuple value and uses it as a basis for comparison.
Python List Sort with Two Keys
How to sort a list with two keys? For example, you have a list of tuples [(1,2), (3,2), (3,3), (1,0), (0,1), (4,2), (1,1), (0,2), (0,0)] and you want to sort after the second tuple value first. But if there’s a tie (e.g. (1,2) and (3,2)), you want to sort after the first tuple value. How can you do that?
Per default, Python sorts tuples lexicographically—the first tuple value is considered first. Only if there’s a tie, it takes the second tuple value and so on.
So to sort with “two keys”, you can define a key function that returns a tuple rather than only a single tuple value. Here’s an example:
>>> lst = [(1,2), (3,2), (3,3), (1,0), (0,1), (4,2), (1,1), (0,2), (0,0)] >>> lst.sort(key=lambda x: (x[1], x[0])) >>> lst [(0, 0), (1, 0), (0, 1), (1, 1), (0, 2), (1, 2), (3, 2), (4, 2), (3, 3)]
The second tuple value takes precedence over the first tuple value.
Python List Sort with Multiple Keys
How to sort a list with multiple keys? For example, you have a list of tuples [(1,1,2), (0,0,1), (0,1,0), (0,1,2), (1,4,0)] and you want to sort after the second tuple value first. But if there’s a tie (e.g. (0,1,0) and (1,1,2)), you want to sort after the third tuple value. If there’s another tie, you want to sort after the first tuple value. How can you do that?
Per default, Python sorts tuples lexicographically—the first tuple value is considered first. Only if there’s a tie, it takes the second tuple value and so on.
So to sort with “two keys”, you can define a key function that returns a tuple rather than only a single tuple value. Here’s an example:
>>> lst = [(1,1,2), (0,0,1), (0,1,0), (0,1,2), (1,4,0)] >>> lst.sort() >>> lst [(0, 0, 1), (0, 1, 0), (0, 1, 2), (1, 1, 2), (1, 4, 0)] >>> lst.sort(key=lambda x: (x[1],x[2],x[0])) >>> lst [(0, 0, 1), (0, 1, 0), (0, 1, 2), (1, 1, 2), (1, 4, 0)]
The second tuple value takes precedence over the third tuple value. And the third tuple value takes precedence over the first tuple value.
Python List Sort Lambda
Lambda functions are anonymous functions that are not defined in the namespace (they have no names). In it’s simplest form, the syntax is:
lambda argument : expression.
You map the argument to the result of the expression.
You can use the lambda function syntax to define the key argument of the sort() method in place.
Here’s an example:
>>> from operator import itemgetter
>>> customers = [('alice', 1000), ('bob', 100), ('frank', 10)]
>>> customers.sort(key=lambda x: x[1])
[('frank', 10), ('bob', 100), ('alice', 1000)]The lambda function returns the second tuple value of each tuple in the list. This is the basis on which the sorting algorithm bases its order.
Python List Sort with Comparator
In the previous examples, you’ve learned about the key argument that allows you to specify for each list element how it should be treated when sorting the list. This way, you can create a separate “value” for each element. The sort() method then sorts the list based on these “values” rather than based on the list elements themselves.
There’s only one condition: the returned values must be comparable. Otherwise, how’d you expect the list to sort them?
What does it mean to be comparable? And how do you make your own custom class comparable? To do this, you must implement a number of methods in your custom class definition (source):
| Operator | Method |
|---|---|
| == | __eq__ |
| != | __ne__ |
| < | __lt__ |
| <= | __le__ |
| > | __gt__ |
| >= | __ge__ |
If you implement all of those methods, you can compare two elements easily. All basic Python data structures have implemented them. So don’t worry about it.
Python List Sort Implementation
Python’s sorting routines such as list.sort() and the built-in sorted() use the Timsort algorithm (named after its creator Tim Peters).
The main idea is to use the popular mergesort algorithm that allows you to quickly combine two already sorted sequences quickly in linear runtime. So if you already have sorted subsequences, they can be combined quickly.
The Timsort algorithm exploits this idea by searching for already sorted subsequences that can be merged together (these sorted subsequences are called “runs” in the original algorithmic description of Timsort). If you can quickly identify runs and you can quickly merge those runs into a sorted sequence, you exploit the existing (random) ordering of the data. Many real-world data sets already come with many such sorted “runs”.
Thus, while the algorithm has the same worst-case time complexity of O(n log n), the best-case time complexity is O(n). In many practical settings, the algorithm outperforms theoretically similar algorithms because of the property of leveraging the existing ordering of the data.
You can dive deep into the Timsort algorithm here.
Python List Sort Complexity
Python’s Timsort algorithm has O(n log n) worst-case time complexity and O(n) best-case time complexity if the list is already largely sorted. It also has excellent benchmark results—it outperforms many of the best sorting algorithms in the world on real-world input data.


Python List Sort Error
There are two common errors when using the list.sort() method.
Python List Sort Returns None
The return value of the list.sort() method is None, but many coders expect it to be the sorted list. So they’re surprised finding out that their variables contain the None type rather than a sorted list.
>>> lst = [10, 5, 7] >>> a = lst.sort() >>> print(a) None
However, returning None makes perfect sense for the list.sort() method. Why? Because you call the method on a list object and it modifies this exact list object. It doesn’t create a new list—there won’t be a new list object in memory.
>>> print(lst) [5, 7, 10]
If you want to create a new list object, use the sorted() built-in Python function like this:
>>> sorted([10, 8, 9]) [8, 9, 10]
Python list sort ‘nonetype’ object is not iterable
Say you want to iterate over a list in a sorted order. You want to use the list.sort() method to accomplish this.
This code snippet would solve the problem, wouldn’t it?
years = [2008, 1999, 2012, 1988]
for year in years.sort():
print(year)But when running the code, you get the following error message:
Traceback (most recent call last):
File "C:\Users\xcent\Desktop\code.py", line 3, in <module>
for year in years.sort():
TypeError: 'NoneType' object is not iterableWhy does the TypeError occur?
The reason is that the list.sort() method returns the value None. It doesn’t return a new list with sorted values (as you expected). Instead, it sorts the list in place. If you want to fix this and get a new list with sorted values, you need to use the built-in sorted(list) method.
Here’s an example:
years = [2008, 1999, 2012, 1988]
for year in sorted(years):
print(year)Now, the result is expected:
1988 1999 2008 2012
Python List Sort Alphabetically/Lexicographically
Problem: Given a list of strings. Sort the list of strings in alphabetical order!
Example:
['Frank', 'Alice', 'Bob'] --> ['Alice', 'Bob', 'Frank']
Solution: Use the list.sort() method without argument to solve the list in lexicographical order which is a generalization of alphabetical order (also applies to the second, third, … characters).
lst = ['Frank', 'Alice', 'Bob'] lst.sort() print(lst) # ['Alice', 'Bob', 'Frank']
Try It Yourself:
Python List Sort Alphabetically Reverse
You can reverse the order of the list by using the reverse keyword. Set reverse=False to sort in ascending order and set reverse=True to sort in descending order.
lst = ['Frank', 'Alice', 'Bob'] lst.sort(reverse=False) print(lst) # ['Alice', 'Bob', 'Frank'] lst.sort(reverse=True) print(lst) # ['Frank', 'Bob', 'Alice']
Python List Sort Alphabetically and Numerically
Problem: You’ve got a list of strings. Each string contains a number. You want the numbers to sort numerically (e.g., 100 comes after 20, not before) but the characters to sort alphabetically (e.g., 'c' comes before 'd').
Example:
['alice 100', 'alice 20', 'bob 99'] --> ['alice 20', 'alice 100', 'bob 99'
Naive Solution (doesn’t work): Use the list.sort() method to sort the list alphabetically:
lst = ['alice 100', 'alice 20', 'bob 99'] lst.sort() print(lst) # ['alice 100', 'alice 20', 'bob 99']
Because the number 100 comes before 20 in an alphabetical order, the string 'alice 100' is placed before 'alice 20'.
Solution: I found this code on StackOverflow that nicely demonstrates how to sort alphanumerically:
import re
def sorted_nicely(l):
""" Sort the given iterable in the way that humans expect."""
convert = lambda text: int(text) if text.isdigit() else text
alphanum_key = lambda key: [convert(c) for c in re.split('([0-9]+)', key)]
l.sort(key = alphanum_key)
lst = ['alice 100', 'alice 20', 'bob 99']
sorted_nicely(lst)
print(lst)
# ['alice 20', 'alice 100', 'bob 99']The idea is to differentiate characters and numbers and use them as the basis of comparison for the sort routine.
Python Sort List with Letters and Numbers
See previous Section Python List Sort Alphabetically.
Python List Sort Case Insensitive
The problem with the default list.sort() or sorted(list) method is that they consider capitalization. This way, it can lead to strange sortings like this:
lst = ['ab', 'Ac', 'ad'] lst.sort() print(lst) # ['Ac', 'ab', 'ad']
Intuitively, you would expect the string 'ab' to occur before 'Ac', right?
To ignore the capitalization, you can simply call the x.lower() method on each element x before sorting the list.
However, my preferred method is to use the key argument to accomplish the same thing in a single line of code:
lst = ['ab', 'Ac', 'ad'] lst.sort(key=lambda x: x.lower()) print(lst) # ['ab', 'Ac', 'ad']
If you like one-liners, you’ll love my new book “Python One-Liners” with NoStarch Press (Amazon Link).
Python List Sort In Place
If you call the list.sort() method, you sort the list object in place. In other words, you don’t create a new list with the same elements in sorted order. No! You sort the existing list. Thus, all variables that also point to this list in memory will see the changed list.
Here’s an example that shows exactly that:
lst_1 = ['Bob', 'Alice', 'Frank'] lst_2 = lst_1 lst_1.sort() print(lst_2) # ['Alice', 'Bob', 'Frank']
You can see in the code that the sorting is visible for the variable lst_2 that point to the same object in memory.
If you want to sort the list but return a new object (without modifying the old list object), you need to take the Python built-in sorted() method:
lst_1 = ['Bob', 'Alice', 'Frank'] lst_2 = sorted(lst_1) print(lst_1) # ['Bob', 'Alice', 'Frank'] print(lst_2) # ['Alice', 'Bob', 'Frank']
Now both lists point to separate list objects in memory. Thus, the change in the order of the elements is only visible to list lst_2.
Python List Sort Ascending vs Descending (Reverse)
To sort a list in ascending order means that the elements are ordered from small to large. Per default, Python lists are sorted in ascending order.
lst_1 = ['Bob', 'Alice', 'Frank'] lst_1.sort() print(lst_1) # ['Alice', 'Bob', 'Frank'] lst_2 = [10, 8, 11, 2, 1] lst_2.sort() print(lst_2) # [1, 2, 8, 10, 11]
However, if you want to sort in descending order (from large to small), you can use either of the following two methods:
- Use the
list.sort(reverse=True)method with thereverse=Trueargument. - Use slicing
list[::-1]to reverse the order of the list.
The difference between both methods is that the first changes the list in place, and the second creates a new list with sorted elements in descending order.
Here’s the example:
lst_1 = ['Bob', 'Alice', 'Frank'] lst_1.sort(reverse=True) print(lst_1) # ['Frank', 'Bob', 'Alice'] lst_2 = [10, 8, 11, 2, 1] lst_2.sort() lst_2 = lst_2[::-1] print(lst_2) # [11, 10, 8, 2, 1]
As you see, using the reverse=True argument is prettier in most cases.
Python List Sort Index (Argsort)
What if you want to sort a list but you only want to have the indices of the sorted elements?
Problem: Say, you have the list ['Bob', 'Alice', 'Carl'] and you’re interested in the sorted indices [1, 0, 2].
Solution: There are many pure Python ways on the web, but the simplest and most efficient solution is to “stand on the shoulders of giants” and use the NumPy library—specifically, the np.argsort() method.
Here’s how:
import numpy as np lst = ['Bob', 'Alice', 'Carl'] sorted_indices = np.argsort(lst) print(sorted_indices) # [1 0 2]
Why look further than that? If you need the result to be a list, then feel free to convert it using the list(...) constructor.
Related article:
Python Sort List of Strings
How can you sort a list of strings? There’s no difference – just use the normal list.sort() method. If you need to sort in an alphanumerical way, then use the tips above (see Section Python List Sort Alphabetically).
Here’s the minimal example:
lst = ['Bob', 'Alice', 'Carl'] lst.sort() print(lst) # ['Alice', 'Bob', 'Carl']
Python Sort List of Floats
You can sort a list of floats like you sort any other list. There’s no difference:
lst = [101.0, 20.9, 13.4, 106.4] lst.sort() print(lst) # [13.4, 20.9, 101.0, 106.4]
The default sorting of numerical values is in ascending order.
However, what if you have the list of floats given as string values? This can lead to unexpected behavior:
lst = ['101.0', '20.9', '13.4', '106.4'] lst.sort() print(lst) # ['101.0', '106.4', '13.4', '20.9']
The “sorted” list looks strange. The problem is that the strings are sorted alphabetically, not numerically. The letter '1' comes before the letter '2' in the Unicode alphabet. That’s why the number '101.0' comes before '20.9'—even if the latter is a smaller numerical value.
If you want to sort the list numerically, you have to convert all list values to floats first. The easiest way to do this is to use the float() built-in Python conversion function as a key argument of the lst.sort() method.
lst = ['101.0', '20.9', '13.4', '106.4'] lst.sort(key=float) print(lst) # ['13.4', '20.9', '101.0', '106.4']
This way, you retain the string data type because the list values are not actually changed. But you associate a new “value” to each list element via the key function—the respective float value of the string element.
Python Sort List of Tuples
Problem: Say you have a list of tuples [(1,1,2), (0,0,1), (0,1,0), (0,1,2), (1,4,0)] and you want to sort after the second tuple value first. But if there’s a tie (e.g. (0,1,0) and (1,1,2)), you want to sort after the third tuple value. If there’s another tie, you want to sort after the first tuple value. How can you do that?
Per default, Python sorts tuples lexicographically which means that the first tuple value is considered first. Only if there’s a tie, it takes the second tuple value and so on.
Solution: Define a key function that returns a tuple rather than only a single tuple value. Here’s an example:
>>> lst = [(1,1,2), (0,0,1), (0,1,0), (0,1,2), (1,4,0)] >>> lst.sort() >>> lst [(0, 0, 1), (0, 1, 0), (0, 1, 2), (1, 1, 2), (1, 4, 0)] >>> lst.sort(key=lambda x: (x[1],x[2],x[0])) >>> lst [(0, 0, 1), (0, 1, 0), (0, 1, 2), (1, 1, 2), (1, 4, 0)]
The second tuple value takes precedence over the third tuple value. And the third tuple value takes precedence over the first tuple value.
Python Sort List of Dictionaries
Next, you’re going to learn how to sort a list of dictionaries in all possible variations. [1] So let’s get started!
How to Sort a List of Dictionaries By Value?
Problem: Given a list of dictionaries. Each dictionary consists of multiple (key, value) pairs. You want to sort them by value of a particular dictionary key (attribute). How do you sort this dictionary?
Minimal Example: Consider the following example where you want to sort a list of salary dictionaries by value of the key 'Alice'.
salaries = [{'Alice': 100000, 'Bob': 24000},
{'Alice': 121000, 'Bob': 48000},
{'Alice': 12000, 'Bob': 66000}]
sorted_salaries = # ... Sorting Magic Here ...
print(sorted_salaries)The output should look like this where the salary of Alice determines the order of the dictionaries:
[{'Alice': 12000, 'Bob': 66000},
{'Alice': 100000, 'Bob': 24000},
{'Alice': 121000, 'Bob': 48000}]Solution: You have two main ways to do this—both are based on defining the key function of Python’s sorting methods. The key function maps each list element (in our case a dictionary) to a single value that can be used as the basis of comparison.
- Use a lambda function as the key function to sort the list of dictionaries.
- Use the itemgetter function as the key function to sort the list of dictionaries.
Here’s the code of the first option using a lambda function that returns the value of the key 'Alice' from each dictionary:
# Create the dictionary of Bob's and Alice's salary data
salaries = [{'Alice': 100000, 'Bob': 24000},
{'Alice': 121000, 'Bob': 48000},
{'Alice': 12000, 'Bob': 66000}]
# Use the sorted() function with key argument to create a new dic.
# Each dictionary list element is "reduced" to the value stored for key 'Alice'
sorted_salaries = sorted(salaries, key=lambda d: d['Alice'])
# Print everything to the shell
print(sorted_salaries)The output is the sorted dictionary. Note that the first dictionary has the smallest salary of Alice and the third dictionary has the largest salary of Alice.
[{'Alice': 12000, 'Bob': 66000},
{'Alice': 100000, 'Bob': 24000},
{'Alice': 121000, 'Bob': 48000}]Try It Yourself:
You’ll learn about the second way below (where you use the itemgetter function from the operator module).
Related articles on the Finxter blog:
Python List Sort Remove Duplicates (Sort + Unique)
Idea: To remove duplicates from a list, you can sort the list first and then go over the list once and remove duplicates. As the list is sorted, duplicates will appear side by side. This makes it easier to spot them.
Runtime Complexity: Say, you’ve got a list [1, 10, 3, 2, 3, 1, 11, 10]. If you go over each element and check if this element exists at another position, the runtime complexity is O(n²) for n elements. But if you sort the list first, the runtime complexity is only O(n log n) for sorting. Going over the sorted list [1, 1, 2, 3, 3, 10, 10, 11] once more to find subsequent duplicates is only O(n) so overall runtime complexity of the sorted duplicate detection is O(n log n).
Solution: Consider the following code.
lst = [1, 10, 3, 2, 3, 1, 11, 10]
lst.sort()
index = 0
while index < len(lst) - 1:
if lst[index] == lst[index+1]:
lst.pop(index)
index = index + 1
print(lst)
# [1, 2, 3, 10, 11]Discussion: We keep track of the current index that goes from left to right over the list and removes an element if its successor in the list is a duplicate. This way, you remove all duplicates from the sorted list.
Alternatives: You can also convert the list to a set and back to a list to remove duplicates. This has runtime complexity of only O(n) and is, therefore, more efficient.
lst = [1, 10, 3, 2, 3, 1, 11, 10] dup_free = list(set(lst)) print(dup_free) # [1, 2, 3, 10, 11]
Python List Quicksort
Quicksort is not only a popular question in many code interviews – asked by Google, Facebook, and Amazon – but also a practical sorting algorithm that is fast, concise, and readable. Because of its beauty, you won’t find many “Intro to Algorithms” classes that don’t discuss the Quicksort algorithm.
Quicksort sorts a list by recursively dividing the big problem (sorting the list) into smaller problems (sorting two smaller lists) and combining the solutions from the smaller problems in a way that it solves the big problem. In order to solve each smaller problem, the same strategy is used recursively: the smaller problems are divided into even smaller subproblems, solved separately, and combined. Because of this strategy, Quicksort belongs to the class of “Divide and Conquer” algorithms. Let’s dive deeper into the Quicksort algorithm:
The main idea of Quicksort is to select a pivot element and then placing all elements that are larger or equal than the pivot element to the right and all elements that are smaller than the pivot element to the left. Now, you have divided the big problem of sorting the list into two smaller subproblems: sorting the right and the left partition of the list. What you do now is to repeat this procedure recursively until you obtain a list with zero elements. This list is already sorted, so the recursion terminates.
The following figure shows the Quicksort algorithm in action:
Figure: The Quicksort algorithm selects a pivot element, splits up the list into (i) an unsorted sublist with all elements that are smaller or equal than the pivot, and (ii) an unsorted sublist with all elements that are larger than the pivot. Next, the Quicksort algorithm is called recursively on the two unsorted sublists to sort them. As soon as the sublists contain maximally one element, they are sorted by definition – the recursion ends. At every recursion level, the three sublists (left, pivot, right) are concatenated before the resulting list is handed to the higher recursion level.
Here’s a Python one-liner implementation from my new Python One-Liners Book (Amazon Link).
## The Data unsorted = [33, 2, 3, 45, 6, 54, 33] ## The One-Liner q = lambda l: q([x for x in l[1:] if x <= l[0]]) + [l[0]] + q([x for x in l if x > l[0]]) if l else [] ## The Result print(q(unsorted))
If you need some explanation, check out my in-depth blog article about this one-liner Quicksort implementation:
Related articles:
Python List Sort Len
Problem: Given a list of strings. How can you sort them by length?
Example: You want to sort your list of strings ['aaaa', 'bbb', 'cc', 'd'] by length—starting with the shortest string. Thus, the result should be ['d', 'cc', 'bbb', 'aaaa']. How to achieve that?
Solution: Use the len() function as key argument of the list.sort() method like this: list.sort(key=len). As the len() function is a Python built-in function, you don’t need to import or define anything else.
Here’s the code solution:
lst = ['aaaa', 'bbb', 'cc', 'd'] lst.sort(key=len) print(lst)
The output is the list sorted by length of the string:
['d', 'cc', 'bbb', 'aaaa']
You can also use this technique to sort a list of lists by length.
Python List Sort Enumerate
Problem: Given an enumerated list of (index, value) pairs. How can you sort the list by value?
Example: You have the list ['Alice', 'Bob', 'Ann', ‘Frank’]. The enumerated list is list(enumerate(['Alice', 'Bob', 'Ann', 'Frank'])) == [(0, 'Alice'), (1, 'Bob'), (2, 'Ann'), (3, 'Frank')]. How can you sort that by value.
Solution: This is an instance of the problem: how to sort a list of tuples by the second tuple value? You can do this by using the key argument with a simple lambda function that returns the second tuple value as a basis for comparison.
Here’s the code solution:
lst = ['Alice', 'Bob', 'Ann', 'Frank'] en_lst = list(enumerate(lst)) en_lst.sort(key=lambda x: x[1]) print(en_lst)
The output is the list sorted by the value of the enumerated list.
[(0, 'Alice'), (2, 'Ann'), (1, 'Bob'), (3, 'Frank')]
Python List Sort Zip
Problem: How to sort a zipped list by values?
Example: Given two lists [5, 7, 9] and ['Alice', 'Bob', 'Ann']. Zip them together to obtain [(5, 'Alice'), (7, 'Bob'), (9, 'Ann')]. How to sort this list by value (i.e., the second tuple value).
Solution: Again, the solution is a variant of the problem: how to sort a list of tuples by second tuple value? You can do this by using the key argument with a simple lambda function that returns the second tuple value as a basis for comparison.
Here’s the code solution:
a = [5, 7, 9] b = ['Alice', 'Bob', 'Ann'] zipped = list(zip(a, b)) # [(5, 'Alice'), (7, 'Bob'), (9, 'Ann')] zipped.sort(key=lambda x: x[1]) print(zipped)
Here’s the output of the sorted zipped list:
[(5, 'Alice'), (9, 'Ann'), (7, 'Bob')]
Python List Sort Except First Element
Problem: How to sort a list except the first element? The first element should remain at the first position.
Example: Given a list [99, 3, 8, 1, 12]. After sorting, you want the almost sorted list [99, 1, 3, 8, 12]. Only the first element is ignored by the sorting routine.
Solution: You use the sorted(iterable) function to return a new list. As iterable to be sorted, you use all elements of the original list except the first one. Slicing helps you carve out this sublist. Then, you use list concatenation to glue together the sorted sublist and the first element of the list.
Here’s the code solution:
lst = [99, 3, 8, 1, 12] lst_2 = lst[:1] + sorted(lst[1:]) print(lst_2)
Here’s the output of the sorted zipped list:
[99, 1, 3, 8, 12]
Python List Sort File
Problem: Sort a file alphabetically, line by line.
Example: Say, you’ve got the following file "chat.txt" that contains some timestamps of messages in a chatroom.
2014-05-12: hi 2020-07-13: Python is great 2020-07-12: Is Python great? 2014-06-01: how are you?
You want the following sorted file/string:
2014-05-12: hi 2014-06-01: how are you? 2020-07-12: Is Python great? 2020-07-13: Python is great
How can you sort this file in Python?
Solution: You use a concise one-liner to load the contents of the file into a list of strings, one for each line. Then, you sort the list.
Here’s the code:
lines = [line for line in open('chat.txt')]
lines.sort()
print(lines)The output is the following sorted list:
['2014-05-12: hi\n', '2014-06-01: how are you?', '2020-07-12: Is Python great?\n', '2020-07-13: Python is great\n']
If you want to store the results in another file, you can simply write it in a new file. If you don’t need the trailing whitespace characters, you can call strip() like this:
lines = [line.strip() for line in open('chat.txt')]Python List Sort vs Sorted
What’s the difference between the list.sorted() method of Python lists and the sorted() built-in function? Given a list…
- The method
list.sort()sorts the given list in place. It doesn’t create a new list. - The Python built-in function
sorted()creates a new list object with sorted elements.
The return value of the list.sort() method is None but many coders expect it to be the sorted list. So they’re surprised finding out that their variables contain the None type rather than a sorted list.
>>> lst = [10, 5, 7] >>> a = lst.sort() >>> print(a) None
However, returning None makes perfect sense for the list.sort() method. Why? Because you call the method on a list object and it modifies this exact list object. It doesn’t create a new list—there won’t be a new list object in memory.
>>> print(lst) [5, 7, 10]
If you want to create a new list object, use the sorted() built-in Python function like this:
>>> sorted([10, 8, 9]) [8, 9, 10]
Python List Index Time Complexity
For simplicity, here’s the Python equivalent of the implementation with some basic simplifications that don’t change the overall complexity:
def index(value, lst):
for i, el in enumerate(lst):
if el==value:
return i
raise Exception('ValueError')
print(index(42, [1, 2, 42, 99]))
# 2
print(index("Alice", [1, 2, 3]))
'''
Traceback (most recent call last):
File "C:UsersxcentDesktopcode.py", line 10, in <module>
print(index("Alice", [1, 2, 3]))
File "C:UsersxcentDesktopcode.py", line 5, in index
raise Exception('ValueError')
Exception: ValueError
'''I know it’s not the perfect replication of the above C++ code. But it’s enough to see the computational (runtime) complexity of the list.index(value) method.
The index() method has linear runtime complexity in the number of list elements. For n elements, the runtime complexity is O(n) because in the worst case you need to iterate over each element in the list to find that the element does not appear in it.
Let’s check the runtime complexity practically for different list sizes with a short benchmark program.
You can see a plot of the time complexity of the index() method for growing list size here:
The figure shows how the elapsed time of finding the last list element in a list. This experiment is repeated for a growing number of elements. The runtime grows linear to the number of elements.
If you’re interested in the code I used to generate this plot with Matplotlib, this is it:
import matplotlib.pyplot as plt
import time
y = []
for i in [100000 * j for j in range(10,100)]:
lst = list(range(i))
t0 = time.time()
x = lst.count(-99)
t1 = time.time()
y.append(t1-t0)
plt.plot(y)
plt.xlabel("List elements (10**5)")
plt.ylabel("Time (sec)")
plt.show()
Related articles:
Python List Methods Thread Safe
Do you have multiple threads that access your list at the same time? Then you need to be sure that the list operations are actually thread safe.
In other words: can you call any list operation in two threads on the same list at the same time? (And can you be sure that the result is meaningful?)
The answer is yes (if you use the cPython implementation). The reason is Python’s global interpreter lock that ensures that a thread that’s currently working on its code will first finish its current basic Python operation as defined by the cPython implementation. Only if it terminates with this operation will the next thread be able to access the computational resource. This is ensured with a sophisticated locking scheme by the cPython implementation.
The only thing you need to know is that each basic operation in the cPython implementation is atomic. It’s executed wholly and at once before any other thread has the chance to run on the same virtual engine. Therefore, there are no race conditions. An example of such a race condition would be the following: the first thread reads a value from the list, the second thread overwrites the value, and the first thread overwrites the value again invalidating the second thread’s operation.
All cPython operations are thread-safe. But if you combine those operations into higher-level functions, those are not generally thread safe as they consist of many (possibly interleaving) operations.
Where to Go From Here
The list.sort() method sorts the list elements in place in an ascending manner. To customize the default sorting behavior, use the optional key argument by passing a function that returns a comparable value for each element in the list. With the optional Boolean reverse argument, you can switch from ascending (reverse=False) to descending order (reverse=True).
If you keep struggling with those basic Python commands and you feel stuck in your learning progress, I’ve got something for you: Python One-Liners (Amazon Link).
In the book, I’ll give you a thorough overview of critical computer science topics such as machine learning, regular expression, data science, NumPy, and Python basics—all in a single line of Python code!
OFFICIAL BOOK DESCRIPTION: Python One-Liners will show readers how to perform useful tasks with one line of Python code. Following a brief Python refresher, the book covers essential advanced topics like slicing, list comprehension, broadcasting, lambda functions, algorithms, regular expressions, neural networks, logistic regression and more. Each of the 50 book sections introduces a problem to solve, walks the reader through the skills necessary to solve that problem, then provides a concise one-liner Python solution with a detailed explanation.