

Life is unpredictable. Sometimes good things happen out of the blue like you find $100 on the floor. And sometimes bad things happen, like your flight being canceled because of bad weather.
Most programming languages have a module to deal with randomness. Python is no exception coming with the module named random and in this article, we’ll be looking at the most essential functions you need to use it.
The Absolute Basics
Before we use any function from the random module, we must import it.
import random
Because we’re dealing with a computer program, the random numbers are not 100% random. Rather, the module creates pseudo-random numbers using a generator function.
The core generator function Python uses is called the Mersenne Twister. It is one of the most extensively tested random number generators in the world. However, the random numbers are predetermined. If someone sees 624 iterations in a row, they can predict, with 100% accuracy, what the next numbers will be. It’s also a repeating sequence. Fortunately, it takes quite a while to repeat itself. You must go through 2**19937 – 1 numbers (a Mersenne prime, hence the name) before you’ll reach the start of the sequence again.
Therefore, you should NOT use the random module for anything security-related such as setting passwords. Instead, use Python’s secrets module.
It is useful that random doesn’t create 100% random numbers because it allows us to reproduce our results! This is incredibly important for those working in Data Science.
But how do we ensure we can reproduce our results? We first have to plant a seed.
random.seed()
At the start of any work involving randomness, it’s good practice to set a ‘seed’. This can be viewed as the ‘start point’ of our random sequence. To do this we enter any float or int into random.seed().
Let’s set the seed to 1.
import random random.seed(1)
Now we’ll generate random numbers in the range [0.0, 1.0) by calling the random.random() function a few times. If you do the same, you’ll see that your numbers are identical to mine!
>>> random.random() 0.13436424411240122 >>> random.random() 0.8474337369372327 >>> random.random() 0.763774618976614
If we reset the seed and call random.random() again, we will get the same numbers.
>>> random.seed(1) >>> seed_1 = [random.random() for i in range(3)] >>> seed_1 [0.13436424411240122, 0.8474337369372327, 0.763774618976614]
I used a list comprehension for greater readability but you can manually type it if you prefer.
Now we can generate some random numbers. But what would it look like if we generate hundreds of thousands of them and plot them? Plots like that are called distributions.
Distributions
If we roll one dice, every number from 1 to 6 is equally likely. They all have probability 1/6. We say that these probabilities are uniformly distributed. To remember this, recall that a group of people wearing uniforms all look the same.
If we roll two dice and sum their results, the results are not uniformly distributed. The probability of rolling 2 and 12 is 1/36 but 7 has probability 1/6. What’s going on? Not everything is uniformly distributed.

To understand what’s going on, let’s roll one dice 100,000 times and two dice 100,000 times then plot the results. We’ll use the random.choice() function to help us. It takes any sequence and returns a randomly chosen element – assuming a uniform distribution.
Note: I call sns.set() at the start to use the default Seaborn settings as they look much nicer than matplotlib.
Rolling One Dice 100,000 Times
import matplotlib.pyplot as plt import seaborn as sns sns.set() # Create our data outcomes = [1, 2, 3, 4, 5, 6] one_dice = [random.choice(outcomes) for i in range(100000)] # Plot our data plt.hist(one_dice, bins=np.arange(1, 8), density=True) plt.show()
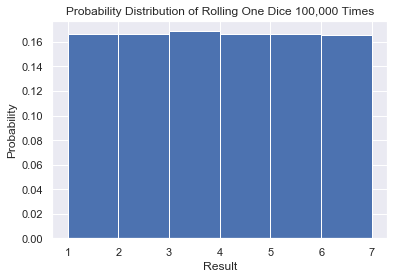
Here is a perfect example of a uniform distribution. We know that 1/6 = 0.1666 and each bar is about that height.
Explaining the Code
We use list comprehensions to generate 100,000 values. Then plot it using plt.hist(). Set density=True to ensure that the y-axis shows probabilities rather than counts. Finally, set bin=np.arange(1, 8) to create 6 bins of width 1. Each bin is half-open – [1, 2) includes 1 but not 2. The final bin is closed – [6, 7] – but since 7 is not a possible outcome this does not impact our results. We can set bins to an integer but this creates a graph that is harder to interpret as you can see below.
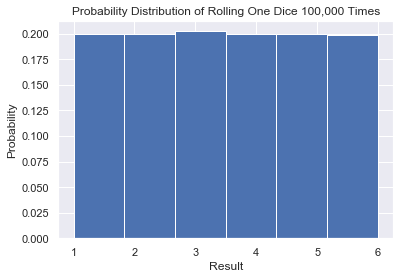
Each bar is of width ~ 0.8 and probability 0.2, neither of which we expected or wanted. Thus, it is always best to manually set bins using np.arange(). If you struggle with NumPy arange, check out the full tutorial of NumPy’s arange function on our blog!
The random module contains the function random.uniform(a, b) that returns randomly chosen floats in the interval [a, b]. If you draw 100,000 numbers and plot the results you’ll see a similar-looking plot to those above.
Rolling Two Dice 100,000 Times
The code is almost identical to the first example.
outcomes = [1, 2, 3, 4, 5, 6]
two_dice = [random.choice(outcomes) + random.choice(outcomes)
for i in range(100000)]
plt.hist(two_dice, bins=np.arange(2, 14), density=True)
plt.show()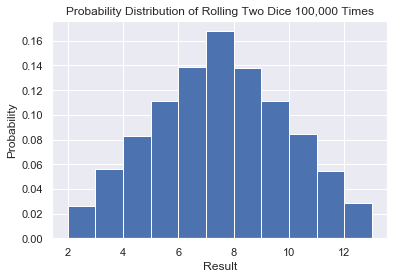
The shape is very different from our first example and illustrates what we expected. Numbers 2 and 12 have probability 1/36 = 0.0277 and 7 is 1/6 = 1.666. The shape may remind you of one of the most famous distributions in the world: the Normal Distribution.
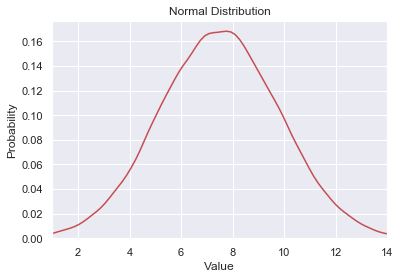
In the Normal Distribution, the values near the center are much more likely to occur than those at the extreme ends. You will see this distribution many times throughout your career as it can be used to model countless random events e.g. height, weight, and IQ.
There are many different distributions and any good statistics textbook explains them in detail. Check out the list of 101 free Python books on the Finxter blog and just download one of your choice.
The random module has functions that draw values from the most common ones. We will just cover the Normal Distribution here for brevity.
Since the Normal Distribution is also called the Gaussian Distribution, random has two functions to generate samples: random.gauss() and random.normalvariate(). Both take two parameters, mu and sigma – the mean and variance of the distribution respectively. For more info check out the Wikipedia page.
We will plot both graphs on the same axes using the following code.
normal = [random.normalvariate(7.5, 2.35) for i in range(100000)]
plt.hist(two_dice, bins=np.arange(2, 14), density=True,
alpha=0.7, label='Dice Data')
sns.distplot(normal, hist=False, color='r', label='Normal Approx.')
plt.legend()
plt.show()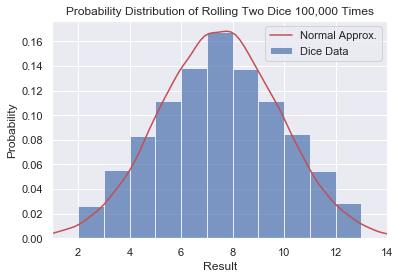
The normal approximation with mu=7.5 and sigma=2.35 is a very good approximation of rolling two dice. I found these after trying a few random values. We call it 100,000 times using list comprehension and plot using sns.distplot setting hist=False to just show the approximation.
This is very useful especially in the field of data science. If we can approximate our data using well-known and well-researched distributions, we instantly know a lot about our data.
There is a whole branch of statistics dedicated to approximating data to known distributions. It can be dangerous to infer too much from a small sample of data. The method we used above is not statistically sound but is a good starting point.
Note that the Normal Distribution does not have a finite selection of values, nor does it have an upper or lower limit. It is unlikely but random.normalvariate(7.5, 2.35) can generate numbers < 2 and > 12. Thus it is only useful as an approximation and not as a replacement.
Three Ideas to Use the Random Module
That was a whistle-stop tour of the random module and now you’ve got everything you need to start using it.
Given that the best way to learn is through projects, here are some ideas for you to try out:
- When web-scraping, use
time.sleep()combined withrandom.uniform()to wait a random amount of time between requests. - Create a ‘guess the number’ game. The computer chooses a random number between 1 and 10 – using
random.choice()– and you guess different numbers with theinput()command. See this book for more ideas. - Create a list of phone numbers and names of your loved ones. Create another list of loving messages. Use Twilio to send a random loving message to a randomly chosen person each day.
Best of luck and may randomness be with you!
Attribution
This article is contributed by Finxter user Adam Murphy (data scientist, grandmaster of Python code):
I am a self-taught programmer with a First Class degree in Mathematics from Durham University and have been coding since June 2019.
I am well versed in the fundamentals of web scraping and data science and can get you a wide variety of information from the web very quickly.
I recently scraped information about all watches that Breitling and Rolex sell in just 48 hours and am confident I can deliver datasets of similar quality to you whatever your needs.
Being a native English speaker, my communication skills are excellent and I am available to answer any questions you have and will provide regular updates on the progress of my work.
If you want to hire Adam, check out his Upwork profile!
Where to Go From Here?
Do you want to become a professional Python coder? Understanding the basics in Python is critical for your success in your professional life!
As I know you are a busy person, I’ve created a simple and easy-to-follow email course based on cheat sheets and a daily Python-related email. One Python lesson at-a-time, you’ll become a great Python coder!
Join tens of thousands of ambitious Python coders now! Just type your email address into the box below and start your new coding venture:
References
[1] https://docs.python.org/3.8/library/random.html
[2] https://en.wikipedia.org/wiki/Mersenne_twister
[3] https://docs.python.org/3.8/library/secrets.html#module-secrets
[4] https://matplotlib.org/3.1.1/api/_as_gen/matplotlib.pyplot.hist.html
[5] https://en.wikipedia.org/wiki/Normal_distribution
[6] https://automatetheboringstuff.com/
[7] https://www.twilio.com/