
Do you want to replace all occurrences of a pattern in a string? You’re in the right place!
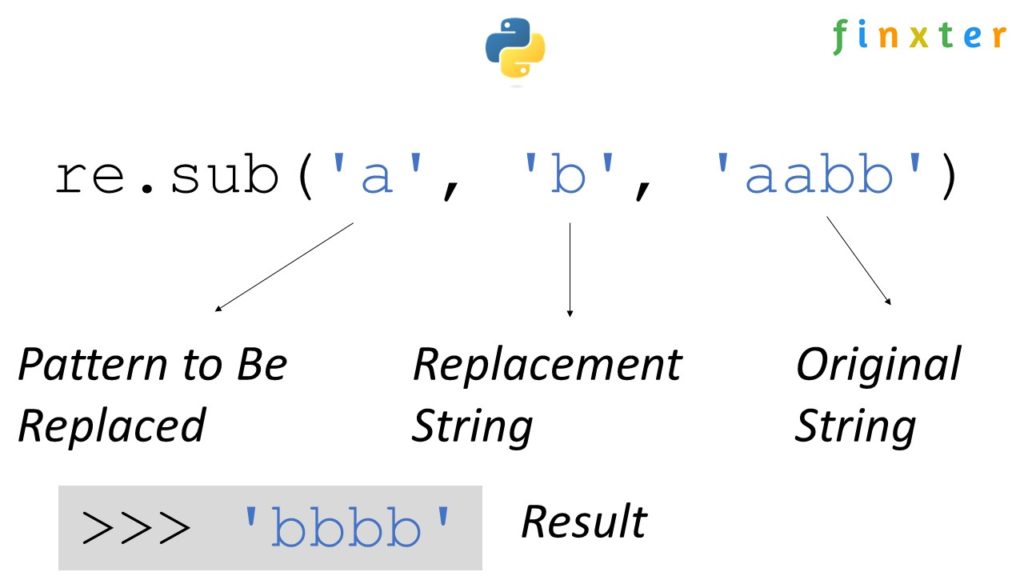
The regex function re.sub(P, R, S) replaces all occurrences of the pattern P with the replacement R in string S. It returns a new string. For example, if you call re.sub('a', 'b', 'aabb'), the result will be the new string 'bbbb' with all characters 'a' replaced by 'b'.
You can also watch my tutorial video as you read through this article:
Related article: Python Regex Superpower – The Ultimate Guide
Do you want to master the regex superpower? Check out my new book The Smartest Way to Learn Regular Expressions in Python with the innovative 3-step approach for active learning: (1) study a book chapter, (2) solve a code puzzle, and (3) watch an educational chapter video.
Let’s answer the following question:
How Does re.sub() Work in Python?
The re.sub(pattern, repl, string, count=0, flags=0) method returns a new string where all occurrences of the pattern in the old string are replaced by repl.
Here’s a minimal example:
>>> import re
>>> text = 'C++ is the best language. C++ rocks!'
>>> re.sub('C\+\+', 'Python', text)
'Python is the best language. Python rocks!'
>>> The text contains two occurrences of the string 'C++'. You use the re.sub() method to search all of those occurrences. Your goal is to replace all those with the new string 'Python' (Python is the best language after all).
Note that you must escape the '+' symbol in 'C++' as otherwise it would mean the at-least-one regex.
You can also see that the sub() method replaces all matched patterns in the string—not only the first one.
But there’s more! Let’s have a look at the formal definition of the sub() method.
Specification
re.sub(pattern, repl, string, count=0, flags=0)
The method has four arguments—two of which are optional.
pattern: the regular expression pattern to search for strings you want to replace.repl: the replacement string or function. If it’s a function, it needs to take one argument (the match object) which is passed for each occurrence of the pattern. The return value of the replacement function is a string that replaces the matching substring.string: the text you want to replace.count(optional argument): the maximum number of replacements you want to perform. Per default, you usecount=0which reads as replace all occurrences of the pattern.flags(optional argument): a more advanced modifier that allows you to customize the behavior of the method. Per default, you don’t use any flags. Want to know how to use those flags? Check out this detailed article on the Finxter blog.
The initial three arguments are required. The remaining two arguments are optional.
You’ll learn about those arguments in more detail later.
Return Value:
A new string where count occurrences of the first substrings that match the pattern are replaced with the string value defined in the repl argument.
Regex Sub Minimal Example
Let’s study some more examples—from simple to more complex.
The easiest use is with only three arguments: the pattern 'sing‘, the replacement string 'program', and the string you want to modify (text in our example).
>>> import re
>>> text = 'Learn to sing because singing is fun.'
>>> re.sub('sing', 'program', text)
'Learn to program because programing is fun.'Just ignore the grammar mistake for now. You get the point: we don’t sing, we program.
But what if you want to actually fix this grammar mistake? After all, it’s programming, not programing. In this case, we need to substitute 'sing' with 'program' in some cases and 'sing' with 'programm' in other cases.
You see where this leads us: the sub argument must be a function! So let’s try this:
import re
def sub(matched):
if matched.group(0)=='singing':
return 'programming'
else:
return 'program'
text = 'Learn to sing because singing is fun.'
print(re.sub('sing(ing)?', sub, text))
# Learn to program because programming is fun.In this example, you first define a substitution function sub. The function takes the matched object as an input and returns a string. If it matches the longer form 'singing', it returns 'programming'. Else it matches the shorter form 'sing', so it returns the shorter replacement string 'program' instead.
How to Use the Count Argument of the Regex Sub Method?
What if you don’t want to substitute all occurrences of a pattern but only a limited number of them? Just use the count argument! Here’s an example:
>>> import re
>>> s = 'xxxxxxhelloxxxxxworld!xxxx'
>>> re.sub('x+', '', s, count=2)
'helloworld!xxxx'
>>> re.sub('x+', '', s, count=3)
'helloworld!'In the first substitution operation, you replace only two occurrences of the pattern 'x+'. In the second, you replace all three.
You can also use positional arguments to save some characters:
>>> re.sub('x+', '', s, 3)
'helloworld!'But as many coders don’t know about the count argument, you probably should use the keyword argument for readability.
How to Use the Optional Flag Argument?
As you’ve seen in the specification, the re.sub() method comes with an optional fourth flag argument:
re.sub(pattern, repl, string, count=0, flags=0)
What’s the purpose of the flags argument?
Flags allow you to control the regular expression engine. Because regular expressions are so powerful, they are a useful way of switching on and off certain features (for example, whether to ignore capitalization when matching your regex).
| Syntax | Meaning |
| re.ASCII | If you don’t use this flag, the special Python regex symbols w, W, b, B, d, D, s and S will match Unicode characters. If you use this flag, those special symbols will match only ASCII characters — as the name suggests. |
| re.A | Same as re.ASCII |
| re.DEBUG | If you use this flag, Python will print some useful information to the shell that helps you debugging your regex. |
| re.IGNORECASE | If you use this flag, the regex engine will perform case-insensitive matching. So if you’re searching for [A-Z], it will also match [a-z]. |
| re.I | Same as re.IGNORECASE |
| re.LOCALE | Don’t use this flag — ever. It’s depreciated—the idea was to perform case-insensitive matching depending on your current locale. But it isn’t reliable. |
| re.L | Same as re.LOCALE |
| re.MULTILINE | This flag switches on the following feature: the start-of-the-string regex ‘^’ matches at the beginning of each line (rather than only at the beginning of the string). The same holds for the end-of-the-string regex ‘$’ that now matches also at the end of each line in a multi-line string. |
| re.M | Same as re.MULTILINE |
| re.DOTALL | Without using this flag, the dot regex ‘.’ matches all characters except the newline character ‘n’. Switch on this flag to really match all characters including the newline character. |
| re.S | Same as re.DOTALL |
| re.VERBOSE | To improve the readability of complicated regular expressions, you may want to allow comments and (multi-line) formatting of the regex itself. This is possible with this flag: all whitespace characters and lines that start with the character ‘#’ are ignored in the regex. |
| re.X | Same as re.VERBOSE |
Here’s how you’d use it in a minimal example:
>>> import re
>>> s = 'xxxiiixxXxxxiiixXXX'
>>> re.sub('x+', '', s)
'iiiXiiiXXX'
>>> re.sub('x+', '', s, flags=re.I)
'iiiiii'In the second substitution operation, you ignore the capitalization by using the flag re.I which is short for re.IGNORECASE. That’s why it substitutes even the uppercase 'X' characters that now match the regex 'x+', too.
What’s the Difference Between Regex Sub and String Replace?
In a way, the re.sub() method is the more powerful variant of the string.replace() method which is described in detail on this Finxter blog article.
Why? Because you can replace all occurrences of a regex pattern rather than only all occurrences of a string in another string.
So with re.sub() you can do everything you can do with string.replace()—but some things more!
Here’s an example:
>>> 'Python is python is PYTHON'.replace('python', 'fun')
'Python is fun is PYTHON'
>>> re.sub('(Python)|(python)|(PYTHON)', 'fun', 'Python is python is PYTHON')
'fun is fun is fun'The string.replace() method only replaces the lowercase word 'python' while the re.sub() method replaces all occurrences of uppercase or lowercase variants.
Note, you can accomplish the same thing even easier with the flags argument.
>>> re.sub('python', 'fun', 'Python is python is PYTHON', flags=re.I)
'fun is fun is fun'How to Remove Regex Pattern in Python?
Nothing simpler than that. Just use the empty string as a replacement string:
>>> re.sub('p', '', 'Python is python is PYTHON', flags=re.I)
'ython is ython is YTHON'You replace all occurrences of the pattern 'p' with the empty string ''. In other words, you remove all occurrences of 'p'. As you use the flags=re.I argument, you ignore capitalization.
Related Re Methods
There are five important regular expression methods which you should master:
- The
re.findall(pattern, string)method returns a list of string matches. Read more in our blog tutorial. - The
re.search(pattern, string)method returns a match object of the first match. Read more in our blog tutorial. - The
re.match(pattern, string)method returns a match object if the regex matches at the beginning of the string. Read more in our blog tutorial. - The
re.fullmatch(pattern, string)method returns a match object if the regex matches the whole string. Read more in our blog tutorial. - The
re.compile(pattern)method prepares the regular expression pattern—and returns a regex object which you can use multiple times in your code. Read more in our blog tutorial. - The
re.split(pattern, string)method returns a list of strings by matching all occurrences of the pattern in the string and dividing the string along those. Read more in our blog tutorial. - The
re.sub(pattern, repl, string, count=0, flags=0)method returns a new string where all occurrences of the pattern in the old string are replaced byrepl. Read more in our blog tutorial.
These seven methods are 80% of what you need to know to get started with Python’s regular expression functionality.
Summary
You’ve learned the re.sub(pattern, repl, string, count=0, flags=0) method returns a new string where all occurrences of the pattern in the old string are replaced by repl.
Where to Go From Here?
Enough theory. Let’s get some practice!
Coders get paid six figures and more because they can solve problems more effectively using machine intelligence and automation.
To become more successful in coding, solve more real problems for real people. That’s how you polish the skills you really need in practice. After all, what’s the use of learning theory that nobody ever needs?
You build high-value coding skills by working on practical coding projects!
Do you want to stop learning with toy projects and focus on practical code projects that earn you money and solve real problems for people?
🚀 If your answer is YES!, consider becoming a Python freelance developer! It’s the best way of approaching the task of improving your Python skills—even if you are a complete beginner.
If you just want to learn about the freelancing opportunity, feel free to watch my free webinar “How to Build Your High-Income Skill Python” and learn how I grew my coding business online and how you can, too—from the comfort of your own home.