
⭐Summary: Use groupby() function from the itertools module to split a string whenever a character changes. Another way to do this is to use the zip function and manipulate the result using a list comprehension.
Minimal Example
# Given string
text = "aabb-cccdd/eee"
# Method 1: Using itertools.groupby
from itertools import groupby
print(["".join(g) for k, g in groupby(text) if k != '-' and k != '/'])
# ['aa', 'bb', 'ccc', 'dd', 'eee']
# Method 2: Using zip
res = ''
for x, nxt in zip(text, text[1:] + text[-1]):
if x == nxt:
res = res + ''.join(x + '')
else:
res = res + ''.join(x + (','))
print([x for x in res.split(',') if x != "-" and x != "/"])
# ['aa', 'bb', 'ccc', 'dd', 'eee']Problem Formulation
Problem: Given a string; How will you split the string when the character changes?
Example
Consider you are given a string. You have to split the string whenever there’s a character change in the string, meaning you have to split the string whenever two consecutive characters are different.
# Input text = "111#222333@999" # Output: ['111', '222', '333', '999']
In the above case, the character changes from numbers to “#” and “@”. Or it changes from one digit to another. Note that the resultant list must not contain the characters # and @. Can you solve this problem?
Method 1: Using itertools.groupby
Prerequisite:
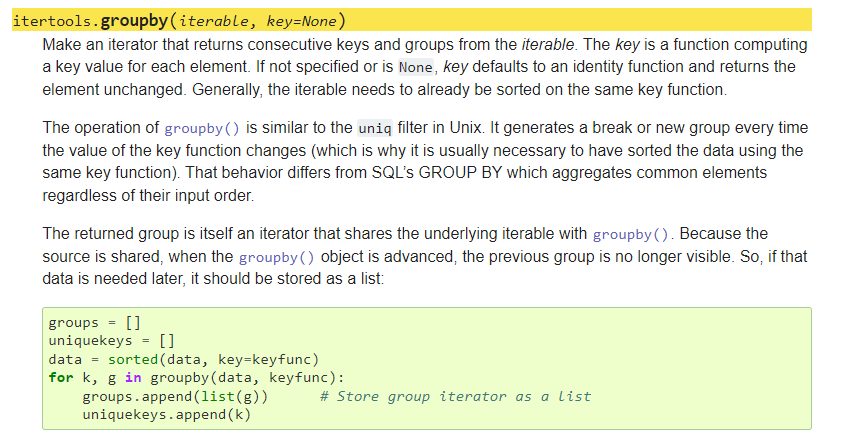
📖Read more here: itertools.groupby(iterable, key=None)
Approach: The groupby() method allows you to group your data and execute functions on these groups. In our case, the string will be grouped by similar characters that appear in a continuous sequence and you can generate the following groups with the help of the groupby() method:
| 1 | 111 |
| # | # |
| 2 | 222 |
| 3 | 333 |
| @ | @ |
| 9 | 999 |
Note that the groupby() method will return objects. Since it returns objects, you can use the join() method to convert them into strings. (to view them in human-readable format). You can then add the strings to a list. All of this can be performed within a list comprehension as shown in the solution below. Also, you have to ignore the grouped strings with characters “#” and “@”, since the characters are not required in the resultant list. This can be taken care of with the help of an if condition as shown in the solution below.
Code:
# Given text text = "111#222333@999" from itertools import groupby print(["".join(g) for k, g in groupby(text) if k != '#' and k != '@']) # ['111', '222', '333', '999']
Note: The join() method concatenates the elements in an iterable. The result is a string whereas each element in the iterable is “glued together” using the string on which it is called as a delimiter. Read more: Python String join()
📖Recommended Read: Python List of Lists Group By – A Simple Illustrated Guide
Method 2: Using zip()
Prerequisite: The zip() function takes an arbitrary number of iterables and aggregates them to a single iterable, a zip object. It combines the i-th values of each iterable argument into a tuple. Hence, if you pass two iterables, each tuple will contain two values. If you pass three iterables, each tuple will contain three values. For example, zip together lists [1, 2, 3] and [4, 5, 6] to [(1,4), (2,5), (3,6)].
Approach: Use the zip() function to iterate through two iterables. It is important to understand what these two iterables are. So, the first iterable is the string itself. The second iterable is the string starting from index 1 until the end. Now, this helps you to couple two consecutive characters with the help of the zip method which groups them in a single object.
Thus, each pair can now be compared to each other such that whenever they are similar you can join them together. However, as soon as the pairs don’t match you can insert any character of your choice within the string. In this case we have inserted a comma whenever a zip object pair does not meet the criteria (that is both the values must be similar).
Confused? Are you wondering why did we insert a new character whenever two successive characters didn’t match? Well! That’s because this inserted character will work as a separator later on when we split the string generated within the for loop.
Once you have the custom string obtained from the previous operation, you can go ahead and split it using the inserted character (comma in our case) as the delimiter. This returns a list of the split substrings. To take care of the “#” and “@” characters which you have to eliminate, you can use an if condition to crop them out of the list.
Code:
# Given string
text = "111#222333@999"
res = ''
for x, nxt in zip(text, text[1:] + text[-1]):
if x == nxt:
res = res + ''.join(x + '')
else:
res = res + ''.join(x + (','))
print([x for x in res.split(',') if x != "#" and x != "@"])
# ['111', '222', '333', '999']📖Related Read: Python Zip — A Helpful Illustrated Guide
Conclusion
Hurrah! We have successfully solved the given problem using two different ways. I hope you enjoyed this article and it helps you in your Python coding journey. Please subscribe and stay tuned for more interesting articles!