

Does your model’s prediction accuracy suck but you need to meet the deadline at all costs?
Try the quick and dirty “meta-learning” approach called ensemble learning. In this article, you’ll learn about a specific ensemble learning technique called random forests that combines the predictions (or classifications) of multiple machine learning algorithms. In many cases, it will give you better last-minute results.
Video Random Forest Classification Python
This video gives you a concise introduction into ensemble learning with random forests using sklearn:
Ensemble Learning
You may already have studied multiple machine learning algorithms—and realized that different algorithms have different strengths.
For example, neural network classifiers can generate excellent results for complex problems. However, they are also prone to “overfitting” the data because of their powerful capacity of memorizing fine-grained patterns of the data.
The simple idea of ensemble learning for classification problems leverages the fact that you often don’t know in advance which machine learning technique works best.
How does ensemble learning work? You create a meta-classifier consisting of multiple types or instances of basic machine learning algorithms. In other words, you train multiple models. To classify a single observation, you ask all models to classify the input independently. Now, you return the class that was returned most often, given your input, as a “meta-prediction”. This is the final output of your ensemble learning algorithm.
Random Forest Learning
Random forests are a special type of ensemble learning algorithms. They focus on decision tree learning. A forest consists of many trees. Similarly, a random forest consists of many decision trees.
Each decision tree is built by injecting randomness in the tree generation procedure during the training phase (e.g. which tree node to select first). This leads to various decision trees – exactly what we want.
Here is how the prediction works for a trained random forest:
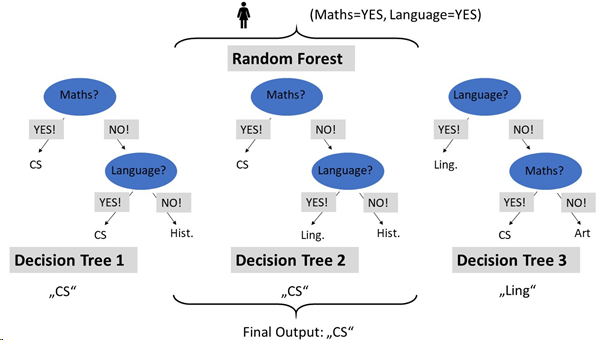
In the example, Alice has high maths and language skills. The “ensemble” consists of three decision trees (building a random forest). To classify Alice, each decision tree is queried about Alice’s classification. Two of the decision trees classify Alice as a computer scientist. As this is the class with most votes, it is returned as final output for the classification.
sklearn.ensemble.RandomForestClassifier
Let’s stick to this example of classifying the study field based on a student’s skill level in three different areas (math, language, creativity). You may think that implementing an ensemble learning method is complicated in Python. But it’s not – thanks to the comprehensive scikit-learn library:
## Dependencies
import numpy as np
from sklearn.ensemble import RandomForestClassifier
## Data: student scores in (math, language, creativity) --> study field
X = np.array([[9, 5, 6, "computer science"],
[5, 1, 5, "computer science"],
[8, 8, 8, "computer science"],
[1, 10, 7, "literature"],
[1, 8, 1, "literature"],
[5, 7, 9, "art"],
[1, 1, 6, "art"]])
## One-liner
Forest = RandomForestClassifier(n_estimators=10).fit(X[:,:-1], X[:,-1])
## Result & puzzle
students = Forest.predict([[8, 6, 5],
[3, 7, 9],
[2, 2, 1]])
print(students)Take a guess: what’s the output of this code snippet?
After initializing the labeled training data, the code creates a random forest using the constructor on the class RandomForestClassifier with one parameter n_estimators that defines the number of trees in the forest.
Next, we populate the model that results from the previous initialization (an empty forest) by calling the function fit(). To this end, the input training data consists of all but the last column of array X, while the labels of the training data are defined in the last column. As in the previous examples, we use slicing to extract the respective columns from the data array X.
Related Tutorial: Introduction to Python Slicing
The classification part is slightly different in this code snippet. I wanted to show you how to classify multiple observations instead of only one. You can simply achieve this here by creating a multi-dimensional array with one row per observation.
Here is the output of the code:
## Result & puzzle
students = Forest.predict([[8, 6, 5],
[3, 7, 9],
[2, 2, 1]])
print(students)
# ['computer science' 'art' 'art']Note that the result is still non-deterministic (which means the result may be different for different executions of the code) because the random forest algorithm relies on the random number generator that returns different numbers at different points in time. You can make this call deterministic by using the argument random_state.
RandomForestClassifier Methods
The RandomForestClassifier object has the following methods (source):
apply(X) | Apply trees in the forest to X and return leaf indices. |
decision_path(X) | Return the decision path in the forest. |
fit(X, y[, sample_weight]) | Build a forest of trees from the training set (X, y). |
get_params([deep]) | Get parameters for this estimator. |
predict(X) | Predict class for X. |
predict_log_proba(X) | Predict class log-probabilities for X. |
predict_proba(X) | Predict class probabilities for X. |
score(X, y[, sample_weight]) | Return the mean accuracy on the given test data and labels. |
set_params(**params) | Set the parameters of this estimator. |
To learn about the different arguments of the RandomForestClassifier() constructor, feel free to visit the official documentation. However, the default arguments are often enough to create powerful classification meta-models.
Where to Go From Here?
Random Forests built upon a thorough understanding of Decision Tree Learning. Read my article about decision trees to improve your understanding of this area.
If you feel that you need to refresh your Python skills, download your Python Cheat Sheets (and get regularly new cheat sheets) by subscribing to my email list.
You can level up your skills with our new Python learning system based on solving rated Python code puzzles. You do nothing but solving Python puzzles and observe how your Python rating improves.
Test your coding skills by solving Python puzzles now!
This article is based on my book “Python One-Liners”. Feel free to check out the additional material to help you master the single line like nobody else!
Python One-Liners Book: Master the Single Line First!
Python programmers will improve their computer science skills with these useful one-liners.

Python One-Liners will teach you how to read and write “one-liners”: concise statements of useful functionality packed into a single line of code. You’ll learn how to systematically unpack and understand any line of Python code, and write eloquent, powerfully compressed Python like an expert.
The book’s five chapters cover (1) tips and tricks, (2) regular expressions, (3) machine learning, (4) core data science topics, and (5) useful algorithms.
Detailed explanations of one-liners introduce key computer science concepts and boost your coding and analytical skills. You’ll learn about advanced Python features such as list comprehension, slicing, lambda functions, regular expressions, map and reduce functions, and slice assignments.
You’ll also learn how to:
- Leverage data structures to solve real-world problems, like using Boolean indexing to find cities with above-average pollution
- Use NumPy basics such as array, shape, axis, type, broadcasting, advanced indexing, slicing, sorting, searching, aggregating, and statistics
- Calculate basic statistics of multidimensional data arrays and the K-Means algorithms for unsupervised learning
- Create more advanced regular expressions using grouping and named groups, negative lookaheads, escaped characters, whitespaces, character sets (and negative characters sets), and greedy/nongreedy operators
- Understand a wide range of computer science topics, including anagrams, palindromes, supersets, permutations, factorials, prime numbers, Fibonacci numbers, obfuscation, searching, and algorithmic sorting
By the end of the book, you’ll know how to write Python at its most refined, and create concise, beautiful pieces of “Python art” in merely a single line.