
Problem Formulation
Given a string, a substring, and a replacement string in Python.
- String
s - Substring
sub - Replacement string
repl
How to find and replace the last occurrence of sub with the replacement repl in the Python string s?
Let’s have a look at a couple of examples to thoroughly understand the problem:
Example 1:s = 'fifi' sub = 'fi'repl = 'nxter' result: 'finxter'Example 2:s = '...' sub = '.'repl = 'hello' result: '..hello'Example 3:s = 'hello\nworld\nuniverse' sub = '\n'repl = ' and ' result: 'hello\nworld and universe'
Let’s dive into the first pure Python method next!
Method 1: rfind()
The Python string.rfind(substr) method returns the highest index in the string where a substring is found, i.e., the index of the last occurrence of the substring in a given string or -1 if not found. You can use slicing in combination with the found index to solve the problem like so:
index = s.rfind(sub)s[:index] + repl + s[index+len(sub):]
- You use
s.rfind(sub)to find the last occurrence ofsubins. - You use slicing operations
s[:index]ands[index+len(sub):]to obtain the unchanged parts of the new string that are not replaced. - You insert the replacement string
replusing string concatenation with the results of the above slicing operations.
Let’s have a look at a practical example next!
Example: Here’s how you can create a new string with the last occurrence of a given substring replaced by a given replacement string:
def repl_last(s, sub, repl):
index = s.rfind(sub)
if index == -1:
return s
return s[:index] + repl + s[index+len(sub):]
# Example 1:
s = 'fifi'
sub = 'fi'
repl = 'nxter'
result = repl_last(s, sub, repl)
print(result)
# result: 'finxter'For comprehensibility, let’s dive into the other two examples introduced in the problem formulation:
# Example 2: s = '...' sub = '.' repl = 'hello' result = repl_last(s, sub, repl) print(result) # result: '..hello' # Example 3: s = 'hello\nworld\nuniverse' sub = '\n' repl = ' and ' result = repl_last(s, sub, repl) print(result) # result: 'hello\nworld and universe'
You can find some background information on rfind() and multiple other string methods in the following video—conquer string methods once and for all! 🙂
Method 2: Regex sub()
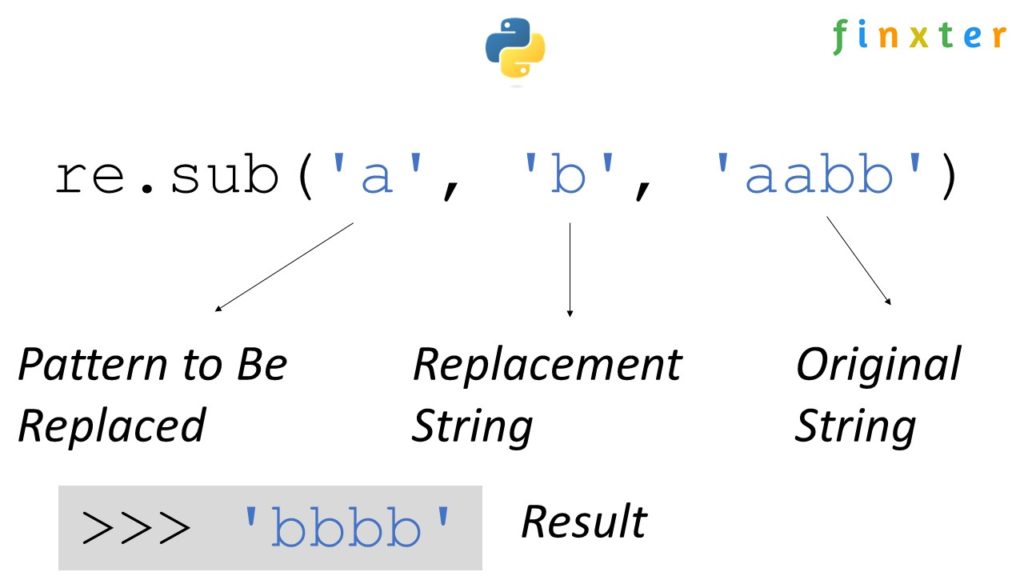
The regex function re.sub(P, R, S) replaces all occurrences of the pattern P with the replacement R in string S. It returns a new string.
For example, if you call re.sub('a', 'b', 'aabb'), the result will be the new string 'bbbb' with all characters 'a' replaced by 'b'.
However, you don’t want to replace all matching substrings—only the last one. So, how to accomplish that?
Let’s have a look at the short answer—I’ll explain it in more detail and with an example afterwards:
pattern = sub + '(?!.*' + sub + ')'
return re.sub(pattern, repl, s, flags=re.DOTALL)- You create the pattern
subwith the negative lookahead(?!.*sub)to make sure that we match the right-most patternsuband it does not occur anywhere on the right. - You replace this rightmost pattern with the replacement string using the
re.sub()method. - You set the
re.DOTALLflag to make sure that the dot and asterisk.*part of the pattern matches all characters including the newline character. This is only a minor optimization to correctly match a couple of border cases.
Okay, let’s have a look at the code to see if it correctly solves our problem!
import re
def repl_last(s, sub, repl):
pattern = sub + '(?!.*' + sub + ')'
return re.sub(pattern, repl, s, flags=re.DOTALL)
# Example 1:
s = 'fifi'
sub = 'fi'
repl = 'nxter'
result = repl_last(s, sub, repl)
print(result)
# result: 'finxter'
# Example 2:
s = '...'
sub = '.'
repl = 'hello'
result = repl_last(s, sub, repl)
print(result)
# result: '..hello'
# Example 3:
s = 'hello\nworld\nuniverse'
sub = '\n'
repl = ' and '
result = repl_last(s, sub, repl)
print(result)
# result: 'hello\nworld and universe'
It does! Regex to the rescue!
Do you want to master the regex superpower? Check out my new book The Smartest Way to Learn Regular Expressions in Python with the innovative 3-step approach for active learning: (1) study a book chapter, (2) solve a code puzzle, and (3) watch an educational chapter video.
Related Tutorial:
Python Regex Course
Google engineers are regular expression masters. The Google search engine is a massive text-processing engine that extracts value from trillions of webpages.
Facebook engineers are regular expression masters. Social networks like Facebook, WhatsApp, and Instagram connect humans via text messages.
Amazon engineers are regular expression masters. Ecommerce giants ship products based on textual product descriptions. Regular expressions rule the game when text processing meets computer science.
If you want to become a regular expression master too, check out the most comprehensive Python regex course on the planet:
