

Summary: Use urllib.parse.urljoin() to scrape the base URL and the relative path and join them to extract the complete/absolute URL. You can also concatenate the base URL and the absolute path to derive the absolute path; but make sure to take care of erroneous situations like extra forward-slash in this case.
Quick Answer
When web scraping with BeautifulSoup in Python, you may encounter relative URLs (e.g., /page2.html) instead of absolute URLs (e.g., http://example.com/page2.html). To convert relative URLs to absolute URLs, you can use the urljoin() function from the urllib.parse module.
Below is an example of how to extract absolute URLs from the a tags on a webpage using BeautifulSoup and urljoin:
from bs4 import BeautifulSoup
import requests
from urllib.parse import urljoin
# URL of the webpage you want to scrape
url = 'http://example.com'
# Send an HTTP request to the URL
response = requests.get(url)
response.raise_for_status() # Raise an error for bad responses
# Parse the webpage content
soup = BeautifulSoup(response.text, 'html.parser')
# Find all the 'a' tags on the webpage
for a_tag in soup.find_all('a'):
# Get the href attribute from the 'a' tag
href = a_tag.get('href')
# Use urljoin to convert the relative URL to an absolute URL
absolute_url = urljoin(url, href)
# Print the absolute URL
print(absolute_url)In this example:
urlis the URL of the webpage you want to scrape.responseis the HTTP response obtained by sending an HTTP GET request to the URL.soupis aBeautifulSoupobject that contains the parsed HTML content of the webpage.soup.find_all('a')finds all theatags on the webpage.a_tag.get('href')gets thehrefattribute from anatag, which is the relative URL.urljoin(url, href)converts the relative URL to an absolute URL by joining it with the base URL.absolute_urlis the absolute URL, which is printed to the console.
Now that you have a quick overview let’s dive into the specific problem more deeply and discuss various methods to solve this easily and effectively. 👇
Problem Formulation
Problem: How do you extract all the absolute URLs from an HTML page?
Example: Consider the following webpage which has numerous links:
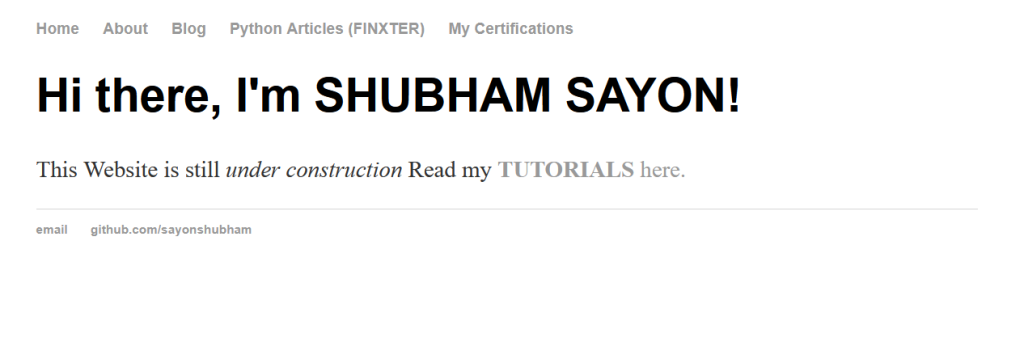

Now, when you try to scrape the links as highlighted above, you find that only the relative links/paths are extracted instead of the entire absolute path. Let us have a look at the code given below, which demonstrates what happens when you try to extract the 'href' elements normally.
from bs4 import BeautifulSoup
import urllib.request
from urllib.parse import urljoin
import requests
web_url = 'https://sayonshubham.github.io/'
headers = {"User-Agent": "Mozilla/5.0 (CrKey armv7l 1.5.16041) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/31.0.1650.0 Safari/537.36"}
# get() Request
response = requests.get(web_url, headers=headers)
# Store the webpage contents
webpage = response.content
# Check Status Code (Optional)
# print(response.status_code)
# Create a BeautifulSoup object out of the webpage content
soup = BeautifulSoup(webpage, "html.parser")
for i in soup.find_all('nav'):
for url in i.find_all('a'):
print(url['href'])Output:
/ /about /blog /finxter /
The above output is not what you desired. You wanted to extract the absolute paths as shown below:
https://sayonshubham.github.io/ https://sayonshubham.github.io/about https://sayonshubham.github.io/blog https://sayonshubham.github.io/finxter https://sayonshubham.github.io/
Without further delay, let us go ahead and try to extract the absolute paths instead of the relative paths.
Method 1: Using urllib.parse.urljoin()
The easiest solution to our problem is to use the urllib.parse.urljoin() method.
According to the Python documentation: urllib.parse.urljoin() is used to construct a full/absolute URL by combining the “base URL” with another URL. The advantage of using the urljoin() is that it properly resolves the relative path, whether BASE_URL is the domain of the URL, or the absolute URL of the webpage.
from urllib.parse import urljoin URL_1 = 'http://www.example.com' URL_2 = 'http://www.example.com/something/index.html' print(urljoin(URL_1, '/demo')) print(urljoin(URL_2, '/demo'))
Output:
http://www.example.com/demo http://www.example.com/demo
Now that we have an idea about urljoin, let us have a look at the following code which successfully resolves our problem and helps us to extract the complete/absolute paths from the HTML page.
Solution:
from bs4 import BeautifulSoup
import urllib.request
from urllib.parse import urljoin
import requests
web_url = 'https://sayonshubham.github.io/'
headers = {"User-Agent": "Mozilla/5.0 (CrKey armv7l 1.5.16041) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/31.0.1650.0 Safari/537.36"}
# get() Request
response = requests.get(web_url, headers=headers)
# Store the webpage contents
webpage = response.content
# Check Status Code (Optional)
# print(response.status_code)
# Create a BeautifulSoup object out of the webpage content
soup = BeautifulSoup(webpage, "html.parser")
for i in soup.find_all('nav'):
for url in i.find_all('a'):
print(urljoin(web_url, url.get('href')))Output:
https://sayonshubham.github.io/ https://sayonshubham.github.io/about https://sayonshubham.github.io/blog https://sayonshubham.github.io/finxter https://sayonshubham.github.io/
Method 2: Concatenate The Base URL And Relative URL Manually
Another workaround to our problem is to concatenate the base part of the URL and the relative URLs manually, just like two ordinary strings. The problem, in this case, is that manually adding the strings might lead to “one-off” errors — try to spot the extra front slash characters / below:
URL_1 = 'http://www.example.com/' print(URL_1+'/demo') # Output --> http://www.example.com//demo
Therefore to ensure proper concatenation, you have to modify your code accordingly such that any extra character that might lead to errors is removed. Let us have a look at the following code that helps us to concatenate the base and the relative paths without the presence of any extra forward slash.
Solution:
from bs4 import BeautifulSoup
import urllib.request
from urllib.parse import urljoin
import requests
web_url = 'https://sayonshubham.github.io/'
headers = {"User-Agent": "Mozilla/5.0 (CrKey armv7l 1.5.16041) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/31.0.1650.0 Safari/537.36"}
# get() Request
response = requests.get(web_url, headers=headers)
# Store the webpage contents
webpage = response.content
# Check Status Code (Optional)
# print(response.status_code)
# Create a BeautifulSoup object out of the webpage content
soup = BeautifulSoup(webpage, "html.parser")
for i in soup.find_all('nav'):
for url in i.find_all('a'):
# extract the href string
x = url['href']
# remove the extra forward-slash if present
if x[0] == '/':
print(web_url + x[1:])
else:
print(web_url+x)Output:
https://sayonshubham.github.io/ https://sayonshubham.github.io/about https://sayonshubham.github.io/blog https://sayonshubham.github.io/finxter https://sayonshubham.github.io/
⚠️ Caution: This is not the recommended way of extracting the absolute path from a given HTML page. In situations when you have an automated script that needs to resolve a URL but at the time of writing the script you don’t know what website your script is visiting, in that case, this method won’t serve your purpose, and your go-to method would be to use urlljoin. Nevertheless, this method deserves to be mentioned because, in our case, it successfully serves the purpose and helps us to extract the absolute URLs.
Conclusion
In this article, we learned how to extract the absolute links from a given HTML page using BeautifulSoup. If you want to master the concepts of Pythons BeautifulSoup library and dive deep into the concepts along with examples and video lessons, please have a look at the following link and follow the articles one by one wherein you will find every aspect of BeautifulSoup explained in great details.
🔗 Recommended: Web Scraping With BeautifulSoup In Python
With that, we come to the end of this tutorial! Please stay tuned and subscribe for more interesting content in the future.