
In the realm of natural language processing and machine learning, two common and highly effective models for handling sequential data are Transformers and Long Short-Term Memory (LSTM) networks. While both models have proven successful in various applications, they differ in terms of architectural structure and how they process and handle data.
LSTM networks, a type of recurrent neural network (RNN), were specifically designed to address the vanishing gradient problem found in standard RNNs. They have the ability to learn and retain long-range dependencies and are often used for sequence-to-sequence tasks, such as language translation or text generation. On the other hand, Transformers have gained popularity in recent years due to their parallelization capabilities and the introduction of the attention mechanism, which allows them to effectively process large, complex sequences without getting bogged down in sequential data processing.
Transformer and LSTM Overview

Transformers outpace RNN models due to simultaneous input processing and are easier to train than LSTMs due to fewer parameters. Currently, they are the leading technology for seq2seq models.
Transformers and LSTMs are both popular techniques used in the field of natural language processing (NLP) and sequence-to-sequence modeling tasks. Let’s dive into the key differences and similarities between these two methods. 🤖
Transformers make use of the attention mechanism that enables them to process and capture crucial aspects of the input data. They do this without relying on recurrent neural networks (RNNs) like LSTMs or gated recurrent units (GRUs). This allows for parallel processing, resulting in faster training times compared to sequential approaches in RNNs.

✅ Recommended: The Evolution of Large Language Models (LLMs): Insights from GPT-4 and Beyond
On the other hand, LSTMs (Long Short-Term Memory) are a type of RNN specifically designed to overcome the limitations of standard RNNs in handling long-term dependencies. They achieve this through a unique cell structure that includes input, output, and forget gates, controlling the flow of information across time steps.

One key advantage of Transformers over LSTMs is their more effective handling of long-range dependencies, due to the self-attention mechanism. This allows them to weigh the importance of various positions in the input sequence, whereas LSTMs might struggle with retaining information from distant positions in longer sequences.
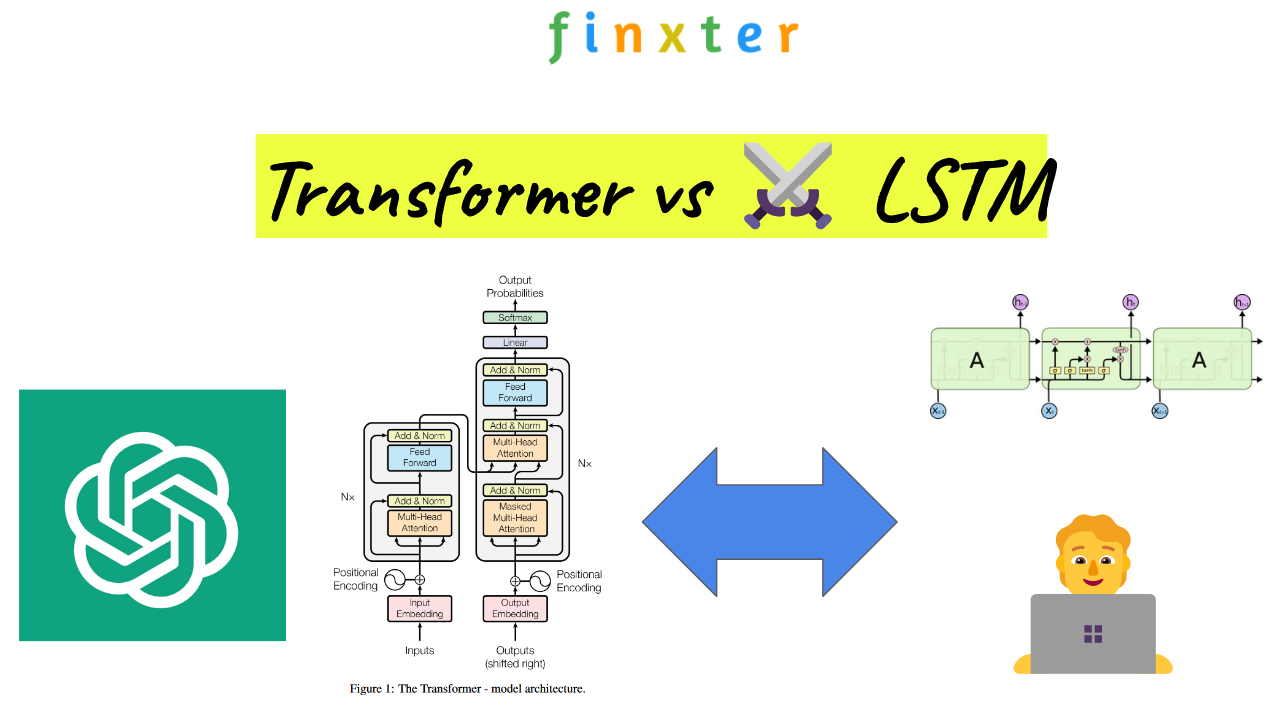
The architecture of Transformers typically consists of stacked encoder and decoder layers, with self-attention and feed-forward neural network (FFN) layers in each. The absence of RNN cells, as seen in LSTMs, contributes to their parallel processing capabilities.
Both Transformers and LSTMs have shown excellent performance in tasks like machine translation, speech recognition, text classification, and more.
Attention Mechanism

The Attention Mechanism is an important innovation in neural networks that allows models to selectively focus on certain aspects of the input data, rather than processing it all at once. This has proven especially useful in language translation and sequence-to-sequence tasks. The Attention Mechanism has paved the way for more advanced network architectures, such as Transformers, and improved upon LSTM models.

Self-Attention
Self-Attention is a specific type of attention mechanism where a model learns to selectively focus on certain parts of the input sequence to generate more relevant output. It computes a weighted sum of input values, where the weights are obtained by comparing each input to the rest of the inputs in the sequence. This allows the model to implicitly learn the relationships and dependencies between the elements in the sequence 🧠.
The main components of Self-Attention are queries, keys, and values. The queries are used to compare the input elements, while the keys and values represent the relationship between the elements. The softmax function is applied to the computed attention weights to form a probability distribution, emphasizing the most relevant elements in the sequence.
Multi-Head Attention
In the Transformer model, Multi-Head Attention is utilized to simultaneously focus on different subsets of the input data, allowing the model to learn multiple contextually rich representations of the data in parallel. Instead of using a single attention mechanism, the Multi-Head Attention mechanism consists of several attention heads, each with its own queries, keys, and values.
This design enables the Transformer to capture various aspects of the input sequence, making it more efficient and powerful at handling complex tasks. Each head processes the input independently and then combines the resulting representations through concatenation and a linear transformation.
Encoder-Decoder Attention
Encoder-Decoder Attention is another important aspect of attention mechanism, primarily used in sequence-to-sequence tasks like machine translation. In this setup, the encoder processes the input sequence and generates a context vector, while the decoder generates the output sequence based on this context vector.

The Encoder-Decoder Attention mechanism allows the decoder to attend to different parts of the encoded input sequence, promoting greater understanding of the input relationships and generating more accurate output sequences. The encoder’s output serves as the keys and values, whereas the decoder’s hidden states act as queries. This setup effectively enables the decoder to align itself to different parts of the input sequence when generating the output, hence leading to improved translation and sequence generation 🚀.
Transformers

Transformers are a type of deep learning architecture that have proven to be very effective, especially in natural language processing tasks. They were introduced in a paper by Vaswani et al. in 2017.
The transformer model is particularly well-suited for handling long-range dependencies in text and allows for efficient parallel computation. In this section, we will discuss some key aspects of transformers, including encoding and decoding, positional encoding, residual connections, and parallelization.
Encoding and Decoding
The transformer model consists of an encoder and a decoder. Both the encoder and decoder are composed of multiple layers, with each layer containing two main components: multi-head self-attention and position-wise feed-forward networks.
- Encoder: The encoder takes the input sequence and processes it to generate a continuous representation. This continuous representation preserves the contextual information of the input and can be effectively used by the decoder for generating the target sequence.
- Decoder: The decoder takes this continuous representation from the encoder and generates the target sequence. It also has a multi-head self-attention mechanism, but in addition, it has an encoder-decoder attention mechanism that helps it to focus on different parts of the input sequence.
Positional Encoding
Since transformers do not have any recurrent or convolutional structure, they need a way to capture the order of the input sequence. This is where positional encoding comes into play. Positional encoding is added to the input embeddings to provide the model with positional information. This is typically accomplished by adding sine and cosine functions of different frequencies to the input embeddings. These functions help the model to learn and use the positions of the input tokens effectively.
Residual Connections
Residual connections are a vital part of the transformer architecture. They allow the model to preserve information from earlier layers and help in mitigating the vanishing gradient problem. In transformers, each sub-layer (multi-head self-attention and position-wise feed-forward networks) has a residual connection followed by a layer normalization step. This means that the output of each sub-layer is added to its input, and this sum is then normalized before being fed to the next sub-layer.
Parallelization
One of the key advantages of the transformer model over RNNs and LSTMs is its ability to process the input sequence in parallel, rather than sequentially. This is because transformers use self-attention mechanisms that can process multiple words simultaneously instead of relying on recurrent connections that process the input in a sequential manner. This parallel computation capability allows transformers to be highly efficient and scalable, making them ideal for handling large-scale natural language processing tasks. 😊
LSTM

Gates and States
Long Short-Term Memory (LSTM) is a type of recurrent neural network (RNN) designed to handle sequence data and address the vanishing gradient problem. It consists of a series of gates and hidden states that help the model remember long-term dependencies in the data. There are three types of gates in an LSTM: input gate, forget gate, and output gate.

- Input gate: The input gate decides how much of the new information should be stored in the cell state. It uses a sigmoid activation function that outputs values between 0 (retain nothing) and 1 (retain everything).
- Forget gate: This gate controls how much of the previous cell state should be forgotten. It also uses a sigmoid activation function. A value close to 0 means forget more, and a value close to 1 means forget less.
- Output gate: The output gate determines what information should be output from the cell state and passed on to the next layer. Its activation function is a combination of sigmoid (for deciding what information to pass) and tanh (to scale the values).
Vanishing Gradient Problem
The vanishing gradient problem is a significant challenge in deep learning, especially with RNNs, when dealing with long sequences. During backpropagation, gradients can become extremely small (vanish) or extremely large (explode), making it difficult to train the model effectively. LSTMs manage to mitigate this issue by using their gates, allowing the network to retain relevant information and disregard irrelevant data.
LSTMs, with their unique architecture and gating mechanisms, provide a more robust and effective way of handling sequence data than traditional RNNs. They can capture long-term dependencies and alleviate the vanishing gradient problem, making them suitable for a wide range of applications, such as natural language processing, time series forecasting, and text generation. 💡 While LSTMs are effective, they are not the only solution for sequence data, as newer models like transformers have emerged to provide alternative approaches for capturing long-range dependencies.
Sequence-to-Sequence Models
Seq2Seq
Seq2Seq (sequence-to-sequence) models are an important breakthrough in the field of Natural Language Processing (NLP). These models are designed to tackle sequence transformation tasks, where the goal is to convert one sequence into another. They consist of two primary components: an encoder and a decoder network. The encoder processes the input sequence, while the decoder generates the output sequence, typically using recurrent neural networks (RNN), Long Short-Term Memory (LSTM), or Gated Recurrent Units (GRU) to handle the challenge of vanishing gradients 🧠.
Seq2Seq models have been further improved with the introduction of attention mechanisms 🎯, which allow the model to selectively focus on different parts of the input sequence while generating the output. This greatly enhances the performance of the model, particularly in tasks involving long-range dependencies.
NLP Applications
There are several notable NLP applications that utilize Seq2Seq models, particularly in the area of language translation and neural machine translation 🌐. These models have proven to be more effective at handling the complexities of language and producing high-quality translations compared to traditional techniques.
Other NLP applications of Seq2Seq models include text summarization, where the model is tasked with generating a shorter, coherent summary of a given document, and conversation modeling to build chatbots 🤖 that can engage in natural and meaningful dialogues with users.
Popular Transformer Models
BERT
BERT (Bidirectional Encoder Representations from Transformers) is a prominent transformer model developed by Google AI. It is particularly successful in natural language processing tasks due to its bidirectional encoding capabilities. BERT achieves state-of-the-art results in numerous NLP benchmarks, such as SQuAD, GLUE, and SuperGLUE 🌟.
This model is pretrained on large datasets, making it easy to fine-tune for specific tasks. BERT comes in different sizes:
- BERT-Base: 12 layers, 768 hidden units
- BERT-Large: 24 layers, 1024 hidden units
GPT
GPT (Generative Pre-trained Transformer) is another popular model created by OpenAI. GPT is known for its capacity to generate human-like text, making it suitable for various tasks like text summarization, translation, and question-answering. GPT initially gained attention with its GPT-2 release. Its most recent release, GPT-3, significantly improved in text generation capabilities:
- GPT-3: 175 billion parameters, 96 layers

✅ Recommended: Will GPT-4 Save Millions in Healthcare? Radiologists Replaced By Fine-Tuned LLMs
Transformer-XL
Transformer-XL (Transformer with extra-long context) is a groundbreaking variant of the original Transformer model. It focuses on overcoming issues in capturing long-range dependencies and enhancing NLP capabilities in tasks like translation and language modeling. Transformer-XL achieves its remarkable performance by implementing a recursive mechanism that connects different segments, allowing the model to efficiently store and access information from previous segments 💡.
Vision Transformers
Vision Transformers (ViT) are a new category of Transformers, specifically designed for computer vision tasks. ViT models treat an image as a sequence of patches, applying the transformer framework for image classification 🖼️. This novel approach challenges the prevalent use of convolutional neural networks (CNNs) for computer vision tasks, achieving state-of-the-art results in benchmarks like ImageNet.
Input Representation
Tokenization
The first step in processing input sequences for both Transformer and LSTM models is tokenization. Tokenization is the process of breaking down the input sentence into smaller units, known as tokens. These tokens are typically words, but can also be subwords or characters, depending on the chosen method. 📘
Embeddings
After tokenization, the next step is to convert these tokens into numerical representations that can be fed into the neural networks. This is achieved using embeddings, which map tokens to high-dimensional vectors, often referred to as word vector embeddings. These embeddings capture semantic and syntactic information about the words, allowing the model to understand the relationships between them.
For Transformer models, in addition to word vector embeddings, positional embeddings are also used. Positional embeddings capture the position of each token within the input sequence, as the Transformer architecture processes the entire input simultaneously, contrary to RNNs and LSTMs, which process the input sequentially. Positional encodings, which are calculated using sine and cosine functions, are added to the word vector embeddings, resulting in a combined representation capturing both token meaning and position. 🌐
In summary:
- Both LSTM and Transformer models require tokenization of input sequences.
- Word vector embeddings provide a numerical representation for each token.
- Positional embeddings are used in Transformer models to encode positional information.
- The final input representation for a Transformer model combines word vector embeddings and positional encodings. 👍
Training and Performance
Training Time
Transformers and LSTMs are both popular choices for training neural networks in deep learning tasks. However, they differ in terms of training time. Transformers are known to have a faster training time compared to LSTMs, as they allow for better parallelization during training. This is because transformers use the self-attention mechanism, which does not rely on sequential computations like LSTMs (source). Additionally, this parallelization can lead to better utilization of modern GPU architectures, which helps speed up the training process.
Efficiency
When it comes to efficiency, transformers are often more efficient than LSTMs for handling long-range dependencies in sequences. The self-attention mechanism allows transformers to directly access any part of the input sequence, unlike LSTMs, which require processing the sequence step-by-step. Consequently, transformers can better model complex relationships between distant tokens in the input (source).
However, one study comparing transformer and LSTM encoder-decoder models in speech recognition tasks showed that transformers might have a higher tendency to overfit datasets. Despite their stable training process, generalization can still be an issue in some cases (source).
👨💻 TLDR: Transformers tend to have faster training times and are more efficient at handling long-range dependencies. On the other hand, LSTMs might have fewer generalization issues in certain tasks. It’s essential to consider these factors when choosing between these neural network architectures for your deep learning project. 🤔
Industry Applications and Examples

Machine Translation
Machine translation is a major application for both LSTM and transformer neural networks. LSTM-based models have been widely used in the past for this task due to their ability to capture the long-range dependencies in languages. However, transformer-based models, such as Google’s BERT, have recently gained popularity because of their better handling of longer-range contexts and improved performance in translation tasks.
Time Series Forecasting
In the realm of time series forecasting, both LSTM and transformers can be employed to model temporal dependencies present in data. LSTMs have long been a popular choice for their ability to capture both short and long-term dependencies in time series data. On the other hand, transformers can also be used effectively for time series forecasting tasks, thanks to their attention mechanism, which can help identify and focus on important parts of the input sequence.
Natural Language Processing
Natural language processing (NLP) tasks, such as sentiment analysis, text classification, and question-answering, greatly benefit from both LSTM and transformer architectures. LSTMs can handle sequential data like text with relative ease, while transformers’ attention mechanisms allow them to excel in these tasks as well. For instance, transformer-based models like OpenAI’s GPT-3 have shown remarkable advancements in NLP tasks, setting new benchmarks in the field.
Alexa
Alexa is an example of a voice-controlled virtual assistant developed by Amazon that relies on NLP techniques for understanding and responding to user queries. While the specific architecture used by Alexa is not publicly known, it is likely that a combination of LSTM and transformer models powers its ability to process and generate human-like responses. The advancements in both LSTM and transformer models have considerably contributed to the progress of voice-controlled virtual assistants like Alexa.
Challenges and Limitations
Sequential Processing
Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks are designed to handle sequential data processing, making them suitable for tasks such as time series forecasting 📈. However, they can struggle with capturing long-range dependencies in the input data due to their sequential nature. This limitation can make it difficult for them to learn complex patterns over long sequences, especially when the input length becomes significantly longer.
On the other hand, Transformers are specifically designed to overcome this limitation by using self-attention mechanisms that enable them to look at the entire input sequence at once, rather than processing it sequentially. This allows Transformers to efficiently handle long-range dependencies and perform better in various natural language processing tasks.
Memory Constraints
Although Transformers are known for their ability to handle long-range dependencies, they can also come at a cost in terms of computational resources and memory usage. They typically require more memory and computation power compared to RNNs and LSTMs due to their extensive use of self-attention mechanisms.🚀
For instance, using Transformers on mobile or embedded devices with limited CPU and memory can be challenging. Moreover, training deep Transformers can demand a significant amount of computational resources, which might not always be feasible depending on the application’s infrastructure.
While Transformers are powerful models that can outperform RNNs and LSTMs in various tasks, they are not without their challenges and limitations. The choice of model should be made considering the specific requirements and constraints of the problem at hand.💡
Frequently Asked Questions
What are the key differences between LSTM and Transformer?
Long Short-Term Memory (LSTM) and Transformers are two types of neural networks designed for sequence-based tasks like natural language processing. LSTM is a type of Recurrent Neural Network (RNN) that addresses the vanishing gradient problem, enabling it to capture longer dependencies in sequences. Meanwhile, Transformers utilize self-attention mechanisms to process sequence inputs, handling long-range dependencies more efficiently. The most notable difference is the absence of RNN cells in Transformer architecture, which allows it to process inputs in parallel, resulting in faster computation 🚀.
How do LSTM and Transformer models compare in terms of speed and performance?
In terms of performance, both LSTM and Transformer models can deliver impressive results. However, Transformers have been shown to outperform LSTMs in some tasks, particularly those involving longer input sequences. With respect to speed, Transformers have a significant advantage, as they can process sequence data in parallel, enabling faster training and inference times ⏱️.
Are Transformers more suitable for certain tasks compared to LSTMs?
Transformers are considered to excel in tasks that require long-range dependencies handling and parallel processing, such as machine translation, text summarization, and natural language understanding. LSTMs can still perform well on shorter sequences, and they may be more suitable for tasks that do not require the full power and complexity of a Transformer model, like sentiment analysis or time-series prediction 🔮.
Why might one choose Transformer over LSTM in specific applications?
Choosing a Transformer model over LSTM could be motivated by several factors, such as:
- Parallel processing capabilities: Transformers can process sequence data concurrently, which is beneficial for computational efficiency and shorter training times.
- Long-range dependency handling: Transformers excel at understanding dependencies across larger sequences, making them ideal for complex tasks like machine translation or text summarization.
- Scalability: Due to their parallel processing capability, Transformers can handle larger input sequences more effectively than LSTMs 🌐.
Can LSTM and Transformer models be combined effectively?
Yes, LSTM and Transformer models can be combined effectively in hybrid architectures, taking advantage of the strengths of both approaches. One example is the use of an LSTM layer for capturing local dependencies within a Transformer-based network, exploiting the flexibility of deep learning frameworks to design custom solutions tailored to specific tasks 🧠.
How do the architectures of LSTM and Transformer models differ?
LSTM models consist of RNN cells with a specialized internal structure, designed to store and manipulate information across time steps more efficiently. In contrast, Transformer models contain a stack of encoder and decoder layers, each consisting of self-attention and feed-forward neural network components. This architecture allows Transformers to process sequence data without the need for recurrent connections or cells, enabling parallel processing and more efficient long-range dependency handling 🔍.
Prompt Engineering with Python and OpenAI
You can check out the whole course on OpenAI Prompt Engineering using Python on the Finxter academy. We cover topics such as:
- Embeddings
- Semantic search
- Web scraping
- Query embeddings
- Movie recommendation
- Sentiment analysis
👨💻 Academy: Prompt Engineering with Python and OpenAI