

Neural Networks have gained massive popularity in the last years. This is not only a result of the improved algorithms and learning techniques in the field but also of the accelerated hardware performance and the rise of General Processing GPU (GPGPU) technology.
In this article, you’ll learn about the Multi-Layer Perceptron (MLP) which is one of the most popular neural network representations. After reading this 5-min article, you will be able to write your own neural network in a single line of Python code!
If you want to skip the background information, feel free to skip to the sklearn section about the MLPRegressor and copy&paste the code to use neural networks in your own script right away!
Video MLPRegressor
Data Generation and Preprocessing
My goal with this article is not to write another simplified introduction into neural networks using only dummy data. Instead, I decided to use relatable real-world data from my fellow Pythonistas. So I have asked my email subscribers to participate in a data generation experiment for this article.
If you are reading this article, you are interested in learning Python. So I asked my email subscribers six anonymized questions about their Python expertise and income. The responses to these questions will serve as training data for the simple neural network example (as a Python one-liner) at the end of this article.
The training data is based on the answers to the following six questions:
- How many hours have you been exposed to Python code in the last 7 days?
- How many years ago have you started to learn about computer science?
- How many coding books are in your shelf?
- What percentage of your Python time do you spend implementing real-world projects?
- How much do you earn per month (round to $1000) from SELLING YOUR TECHNICAL SKILLS (in the widest sense)?
- What’s your approximate Finxter.com Rating (round to 100 points)?
The first five questions will serve as an input, and the sixth question will serve as an output for the neural network analysis. If you already know about the different types of neural networks, you’ll realize that we are doing neural network regression here. In other words, we predict a numerical value (your Python skills) based on numerical input features. We are not going to explore classification in this article which is another great strength of neural networks.
The sixth question approximates the skill level of a Python coder. Finxter.com is a puzzle-based learning platform which assigns a rating value to any Python coder based on their performance in solving Python puzzles.
Let’s start with visualizing how each question influences the output (the skill rating of a Python developer).
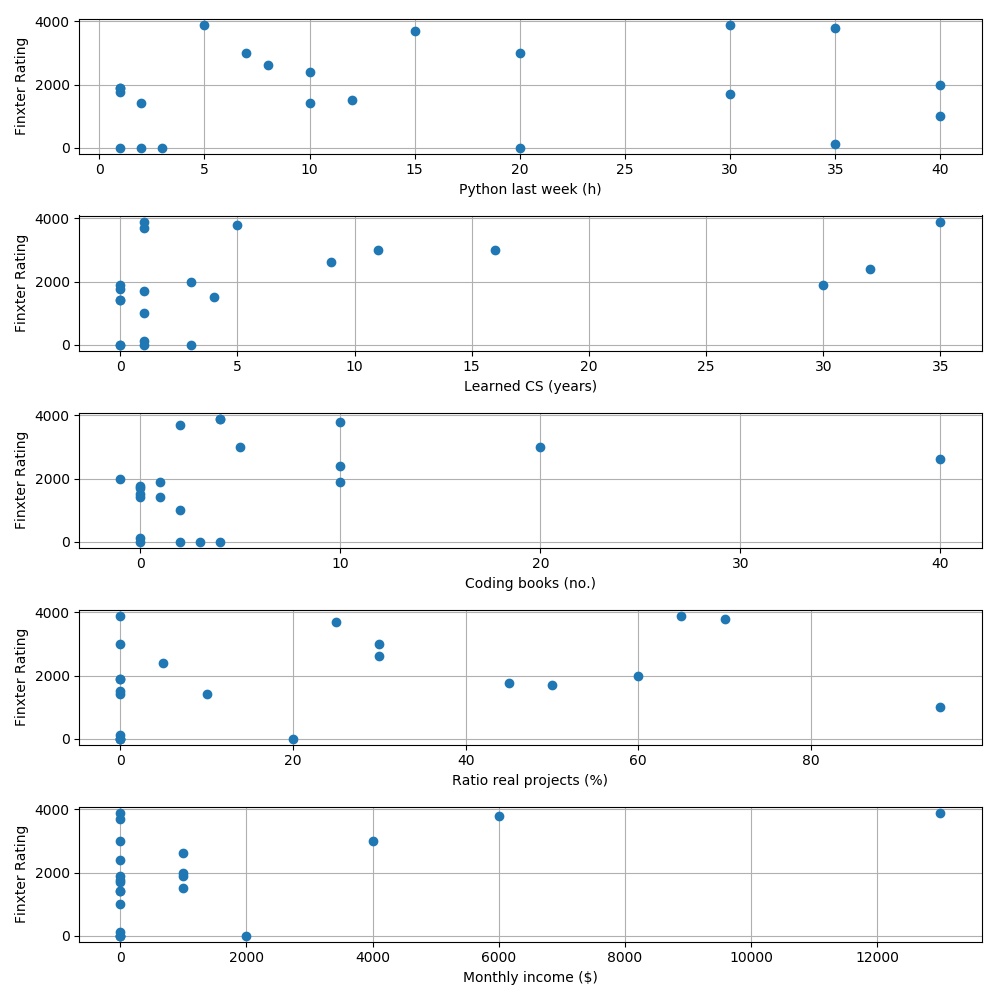
Note that these plots only show how each separate feature (question) impacts the final Finxter rating but it tells us nothing about the impact of a combination of two or more features. Some Pythonistas didn’t answer all six questions — in this case, I used the dummy value “-1”.
What is an Artificial Neural Network?
The idea of creating a theoretical model of the human brain (the biological neural network) has been studied excessively in the last decades. The foundations of artificial neural networks have already been proposed in the 1940s and 1950s! Since then, the concept of artificial neural networks has been refined and improved more and more.
The basic idea is to break the big task of learning and inference into a number of micro-tasks. These micro-tasks are not independent but interdependent. The brain consists of billions of neurons that are connected with trillions of synapses. In the simplified model, learning is nothing but adjusting the “strength” of synapses (also called “weights” or “parameters” in artificial neural networks). Creating a new synapse is represented as increasing the weight from zero to a non-zero value.
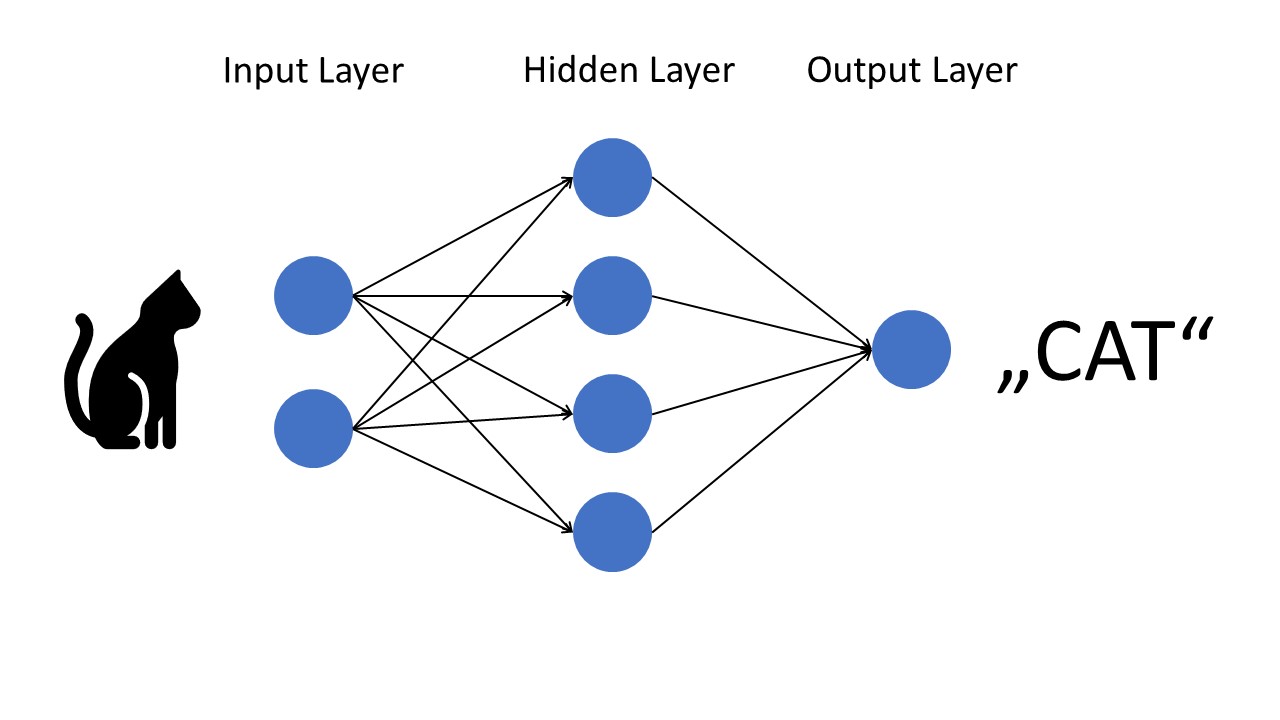
This Figure shows a basic neural network with three layers (input, hidden, output). Each layer consists of a number of neurons that are connected from the input layer via the hidden layer to the output layer. In the example, the neuronal network is trained to detect animals in images. In practice, you would use one input neuron per pixel of the image as an input layer. This can result in millions of input neurons that are connected with millions of hidden neurons. Oftentimes, each output neuron is responsible for one bit of the overall output. For example, to detect two different animals (for example cats and dogs), you’ll use only a single neuron in the output layer that can model two different states (0=cat, 1=dog).
The idea is that the activation of the input neurons propagates through the network: the neurons “fire”. A neuron fires with higher likelihood if its relevant input neurons fire, too.
But let’s have a detailed look into how neurons work mathematically.
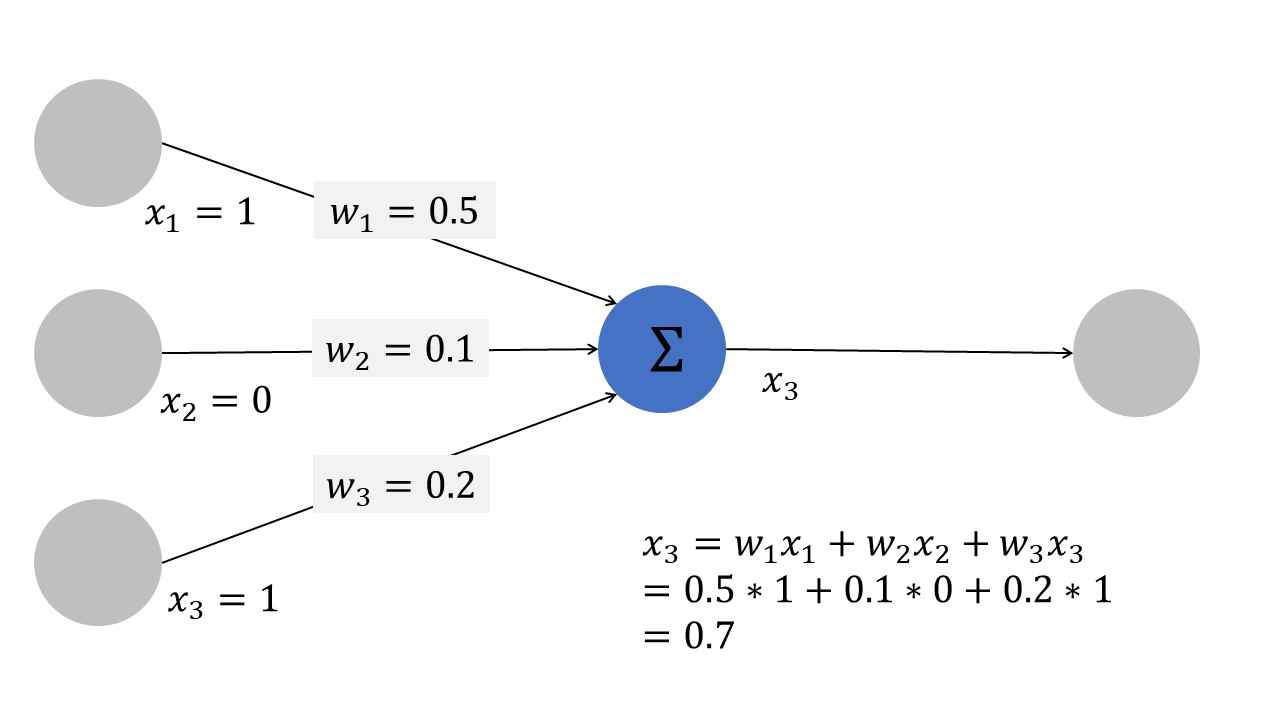
Each neuron is connected with other neurons. But not all connections are equal. Instead, each connection has an associated weight. You can think of the weight as how much of the “impulse” of the firing input neuron is forwarded to the neuron via the connection.
The neuron itself simply sums over all inputs to calculate its own output. In this way, the impulses propagate through the neural network.
What does the learning algorithm do? It uses the training data to select the weights w of the neural network. Given a training input value x, different weights w lead to different outputs. Hence, the learning algorithm gradually changes the weights w — in many iterations — until the output layer produces similar results as the training data. In other words, the training algorithm gradually reduces the error of correctly predicting the training data.
There are many different network structures, training algorithms, and activation functions. This article will show you a hands-on approach of using the neural network now, within a single line of code. You can then learn the finer details as you need to improve upon this (e.g. start with the Wikipedia article).
SKLearn Neural Network with MLPRegressor
The goal is to create a neural network that predicts the Python skill level (Finxter rating) using the five input features (answers to the questions):
- WEEK: How many hours have you been exposed to Python code in the last 7 days?
- YEARS: How many years ago have you started to learn about computer science?
- BOOKS: How many coding books are in your shelf?
- PROJECTS: What percentage of your Python time do you spend implementing real-world projects?
- EARN: How much do you earn per month (round to $1000) from selling your technical skills (in the widest sense)?
We use the
## Dependencies
from sklearn.neural_network import MLPRegressor
import numpy as np
## Questionaire data (WEEK, YEARS, BOOKS, PROJECTS, EARN, RATING)
Q = [[20, 11, 20, 30, 4000, 3000],
[12, 4, 0, 0, 1000, 1500],
[2, 0, 1, 10, 0, 1400],
[35, 5, 10, 70, 6000, 3800],
[30, 1, 4, 65, 0, 3900],
[35, 1, 0, 0, 0, 100],
[15, 1, 2, 25, 0, 3700],
[40, 3, -1, 60, 1000, 2000],
[40, 1, 2, 95, 0, 1000],
[10, 0, 0, 0, 0, 1400],
[30, 1, 0, 50, 0, 1700],
[1, 0, 0, 45, 0, 1762],
[10, 32, 10, 5, 0, 2400],
[5, 35, 4, 0, 13000, 3900],
[8, 9, 40, 30, 1000, 2625],
[1, 0, 1, 0, 0, 1900],
[1, 30, 10, 0, 1000, 1900],
[7, 16, 5, 0, 0, 3000]]
X = np.array(Q)
## One-liner
neural_net = MLPRegressor(max_iter=2000).fit(X[:,:-1], X[:,-1])
## Result
res = neural_net.predict([[0, 0, 0, 0, 0]])
print(res)
In the first few lines, we create the data set. The machine learning algorithms in the scikit-learn library use a similar input format: Each row is a single observation with multiple features. The more rows, the more training data exists; the more columns, the more features of each observation.
In our case, we have five features for the input and one feature for the output value of each training data.
The one-liner simply creates a neural network using the constructor of the MLPRegressor class. The reason I passed max_iter=2000 as an argument is simply because the interpreter complained that the training does not converge using the default number of iterations (i.e., max_iter=200).
After that, we call the fit() function that determines the parameters of the neural network. Only after calling fit, the neural network has been successfully initialized. The fit() function takes a multi-dimensional input array (one observation per row, one feature per column) and a one-dimensional output array (size = number of observations).
The only thing left is calling the predict function on some input values:
## Result res = neural_net.predict([[0, 0, 0, 0, 0]]) print(res) # [94.94925927]
In plain English: If
- you have trained 0 hours in the last week,
- you have started your computer science studies 0 years ago,
- you have 0 coding books in your shelf,
- you spend 0% of your time implementing real Python projects,
- you earn $0 selling your coding skills,
the neural network estimates that your skill level is VERY low (Finxter.com rating number of 94 means that you cannot even understand the Python program print('hello world')).
So let’s improve on this: what happens if you invest 20 hours a week learning and revisit the neural network after one week?
## Result res = neural_net.predict([[20, 0, 0, 0, 0]]) print(res) # [440.40167562]
Not bad, your skills improved quite significantly! But you are still not happy with this rating number (an above-average Python coder has at least 1500-1700 rating on Finxter.com), are you?
No problem, just buy 10 Python books (if you love code puzzles, maybe even my Python book “Coffee Break Python”).
Let’s see what happens to your rating.
## Result res = neural_net.predict([[20, 0, 10, 0, 0]]) print(res) # [953.6317602]
Again, we made significant progress and doubled your rating number! But buying Python books alone will not help you much. You need to study them! Let’s do this for a year.
## Result res = neural_net.predict([[20, 1, 10, 0, 0]]) print(res) # [999.94308353]
Not much happened. This is where I don’t trust the neural network too much. In my opinion, you should have reached a much better performance of at least 1500. But this also shows that the neural network can only be as good as its training data. There is very limited data and the neural network cannot really overcome this limitation: there is just too little knowledge in a handful of data points.
But you don’t give up, right? Next, you spend 50% of your Python time selling your skills as a Python freelancer (do you need some help with this? I show you how to sell your coding skills to the marketplace — even as a Python beginner — in my Python freelancer course)
## Result res = neural_net.predict([[20, 1, 10, 50, 1000]]) print(res) # [1960.7595547]
Boom! Suddenly the neural network considers you to be an expert Python coder. A very wise prediction of the neural network, indeed! Learn Python for at least a year and do practical projects and you’ll become a great coder.
Summary
In this article, you have learned about the very basics of neural networks and how to use them in a single line of Python code. As a bonus, you may have learned from the questionnaire data of my community that starting out with practical projects — maybe even doing freelancer projects from day 1 — matter a lot to your learning success (the neural network certainly knows that).
Some machine learning algorithms are more important than others. Learn about the “8 Pillar Machine Learning Algorithms” in my new course on the Finxter Computer Science Academy!