
If there is one clustering algorithm you need to know – whether you are a computer scientist, data scientist, or machine learning expert – it’s the K-Means algorithm. In this tutorial drawn from my book Python One-Liners, you’ll learn the general idea and when and how to use it in a single line of Python code using the sklearn library.
Labeled vs Unlabeled Training
You may know about supervised learning where the training data is “labeled”, i.e., we know the output value of every input value in the training data. But in practice, this is not always the case. What if you have “unlabeled” data? Especially in many data analytics applications, there is no such thing as “the optimal output”. Prediction is not the goal here – but you can still distill useful knowledge from these unlabeled data sets.
For example, suppose you are working in a startup that serves different target markets with various income levels and ages. Your boss tells you to find a certain number of target “personas” that best fit your different target markets.
It’s time to learn about “unsupervised learning” with unlabeled training data. In particular, you can use clustering methods to identify the “average customer personas” which your company serves.
Here is an example:

Visually, you can easily see three types of Personas with different types of incomes and ages. But how to find those algorithmically? This is the domain of clustering algorithms such as the widely popular K-Means algorithm.
Finding the Cluster Centers
Given the data sets and an integer k, the K-Means algorithm finds k clusters of data such that the difference between the k cluster centers (=the centroid of the data in each cluster) and the data in the k cluster is minimal.
In other words, we can find the different personas by running the K-Means algorithm on our data sets:
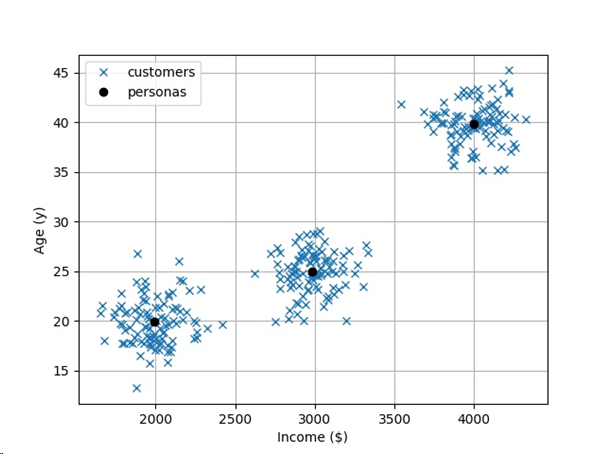
The cluster centers (black dots) fit very nicely to the overall data. Every cluster center can be viewed as one customer persona. Thus, we have three idealized personas:
- A 20-year-old earning $2000,
- A 25-year-old earning $3000, and
- A 40-year-old earning $4000.
And the great thing is that the K-Means algorithm finds those cluster centers completely automated – even in a high-dimensional space (where it would be hard for humans to find the personas visually).
As a small side note: The K-Means algorithm requires “the number of cluster centers k” as an input. In this case, we use domain knowledge and “magically” defined k=3. There are more advanced algorithms that find the number of cluster centers automatically.
K-Means Algorithm Overview
So how does the K-Means algorithm work? In a nutshell, it performs the following procedure:
- Initialize random cluster centers (centroids).
- Repeat until convergence
- Assign every data point to its closest cluster center.
- Recompute each cluster center to the centroid of all data points assigned to it.
KMeans Code Using Sklearn
How can we do all of this in a single line of code? Fortunately, the Scikit-learn library in Python has already implemented the K-Means algorithm in a very efficient manner.
So here is the one-liner code snippet that does K-Means clustering for you:
## Dependencies
from sklearn.cluster import KMeans
import numpy as np
## Data (Work (h) / Salary ($))
X = np.array([[35, 7000], [45, 6900], [70, 7100],
[20, 2000], [25, 2200], [15, 1800]])
## One-liner
kmeans = KMeans(n_clusters=2).fit(X)
## Result & puzzle
cc = kmeans.cluster_centers_
print(cc)Python Puzzle: What’s the output of this code snippet?
Try to guess a solution without understanding every syntactical element!
(In the next paragraphs, I will give you the result of this code puzzle. In my opinion, puzzle-based learning is one of the best
Code Explanation
In the first lines, we import the KMeans module from the

The data is two-dimensional. It correlates the number of working hours with the salary of some workers. There are six data points in this employee data set:
The goal is to find the two cluster centers that fits best to this data.
## One-liner kmeans = KMeans(n_clusters=2).fit(X)
In the one-liner, we explicitly define the number of cluster centers using the function argument n_clusters. First, we create a new KMeans object that handles the algorithm for us. We simply call the instance method fit(X) to run the K-Means algorithm on our input data X. The KMeans object now holds all the results. All which is left is to retrieve the results from its attributes.
cc = kmeans.cluster_centers_ print(cc)
So, what are the cluster centers and what is the output of this code snippet?

In the graphic, you can see that the two cluster centers are (20, 2000) and (50, 7000). This is also the result of the Python one-liner.
Python One-Liners Book: Master the Single Line First!
Python programmers will improve their computer science skills with these useful one-liners.

Python One-Liners will teach you how to read and write “one-liners”: concise statements of useful functionality packed into a single line of code. You’ll learn how to systematically unpack and understand any line of Python code, and write eloquent, powerfully compressed Python like an expert.
The book’s five chapters cover (1) tips and tricks, (2) regular expressions, (3) machine learning, (4) core data science topics, and (5) useful algorithms.
Detailed explanations of one-liners introduce key computer science concepts and boost your coding and analytical skills. You’ll learn about advanced Python features such as list comprehension, slicing, lambda functions, regular expressions, map and reduce functions, and slice assignments.
You’ll also learn how to:
- Leverage data structures to solve real-world problems, like using Boolean indexing to find cities with above-average pollution
- Use NumPy basics such as array, shape, axis, type, broadcasting, advanced indexing, slicing, sorting, searching, aggregating, and statistics
- Calculate basic statistics of multidimensional data arrays and the K-Means algorithms for unsupervised learning
- Create more advanced regular expressions using grouping and named groups, negative lookaheads, escaped characters, whitespaces, character sets (and negative characters sets), and greedy/nongreedy operators
- Understand a wide range of computer science topics, including anagrams, palindromes, supersets, permutations, factorials, prime numbers, Fibonacci numbers, obfuscation, searching, and algorithmic sorting
By the end of the book, you’ll know how to write Python at its most refined, and create concise, beautiful pieces of “Python art” in merely a single line.
Get your Python One-Liners on Amazon!!
Where to go from here?
In this article, you have learned how to run the popular K-Means algorithm in Python — using only a single line of code.
I know that it can be hard to understand Python code snippets. Every coder is constantly challenged by the difficulty of code. Don’t let anybody tell you otherwise.
To make learning Python less of a pain, I have created a Python cheat sheet course where I’ll send you a concise, fresh cheat sheet every week. Join my Python course for free!